呼家楼街道网站建设网站开发入门习题
1.什么是SQL Server?
SQL Server是由Microsoft开发和推广的以客户/服务器(c/s)模式访问、使用Transact-SQL语言的关系数据库管理系统(DBMS),它最初是由Microsoft、Sybase和Ashton-Tate三家公司共同开发的,并于1988年推出了第一个OS/2版本。Microsoft SQL Server近年来不断更新版本,1996年,Microsoft 推出了SQL Server 6.5版本;1998年,SQL Server 7.0版本和用户见面;SQL Server 2000是Microsoft公司于2000年推出,目前最新版本是2019年份推出的SQL SERVER 2019。 提供的主要功能:
- 支持存储过程、触发器、函数和视图
- 本机支持关系数据、XML、FILESTREAM 和空间数据,可存储所有类型的业务数据
- 除与 SQL Server Reporting Services 中的 Microsoft 2007 Office System 集成外,还改进了性能、可用性、可视化
- 通过利用现有的 T-SQL 技术、ADO.NET 实体框架和 LINQ 简化开发工作
- 与 Visual Studio 和 Visual Web Developer 紧密集成
SQL Server 2019 更是使用统一的数据平台实现业务转型,附带 Apache Spark 和 Hadoop Distributed File System(HDFS),可实现所有数据的智能化。
2.环境搭建
pull images
sudo docker pull mcr.microsoft.com/mssql/server:2022-latest
create a container
docker run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=Y.sa123456" -p 1433:1433 --name mssql2022 -d mcr.microsoft.com/mssql/server:2022-latest
default user/password: sa / Y.sa123456
init datas
CREATE DATABASE SampleDB;
USE SampleDB;#JPA AUTO CREATE TABLEINSERT INTO Employees (first_name, last_name, birth_date, hire_date, position)
VALUES
('John', 'Doe', '1980-01-15', '2010-06-01', 'Manager'),
('Jane', 'Smith', '1990-07-22', '2015-09-15', 'Developer'),
('Emily', 'Jones', '1985-03-10', '2012-11-20', 'Designer');
3.代码工程
实验目的
Spring Boot对SQL Server 数据库CRUD 操作
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>springboot-demo</artifactId><groupId>com.et</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>sqlserver</artifactId><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-autoconfigure</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>com.microsoft.sqlserver</groupId><artifactId>mssql-jdbc</artifactId><version>9.4.0.jre8</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>
</project>controller
package com.et.controller;import com.et.entity.Employee;
import com.et.service.EmployeeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;import java.util.List;@RestController
@RequestMapping("/api/employees")
public class EmployeeController {@Autowiredprivate EmployeeService employeeService;@GetMappingpublic List<Employee> getAllEmployees() {return employeeService.getAllEmployees();}@GetMapping("/{id}")public ResponseEntity<Employee> getEmployeeById(@PathVariable Integer id) {return employeeService.getEmployeeById(id).map(ResponseEntity::ok).orElse(ResponseEntity.notFound().build());}@PostMappingpublic Employee addEmployee(@RequestBody Employee employee) {return employeeService.addEmployee(employee);}@PutMapping("/{id}")public ResponseEntity<Employee> updateEmployee(@PathVariable Integer id, @RequestBody Employee employeeDetails) {return ResponseEntity.ok(employeeService.updateEmployee(id, employeeDetails));}@DeleteMapping("/{id}")public ResponseEntity<Void> deleteEmployee(@PathVariable Integer id) {employeeService.deleteEmployee(id);return ResponseEntity.noContent().build();}
}service
package com.et.service;import com.et.entity.Employee;
import com.et.reponsitory.EmployeeRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;
import java.util.NoSuchElementException;
import java.util.Optional;@Service
public class EmployeeService {@Autowiredprivate EmployeeRepository employeeRepository;public List<Employee> getAllEmployees() {return employeeRepository.findAll();}public Optional<Employee> getEmployeeById(Integer id) {return employeeRepository.findById(id);}public Employee addEmployee(Employee employee) {return employeeRepository.save(employee);}public Employee updateEmployee(Integer id, Employee employeeDetails) {Employee employee = employeeRepository.findById(id).orElseThrow(RuntimeException::new);employee.setFirstName(employeeDetails.getFirstName());employee.setLastName(employeeDetails.getLastName());employee.setBirthDate(employeeDetails.getBirthDate());employee.setHireDate(employeeDetails.getHireDate());employee.setPosition(employeeDetails.getPosition());return employeeRepository.save(employee);}public void deleteEmployee(Integer id) {employeeRepository.deleteById(id);}
}reponsitory
package com.et.reponsitory;import com.et.entity.Employee;
import org.springframework.data.jpa.repository.JpaRepository;public interface EmployeeRepository extends JpaRepository<Employee, Integer> {
}application.properties
server.port=8088
spring.datasource.url=jdbc:sqlserver://127.0.0.1:1433;databaseName=SampleDB
spring.datasource.username=sa
spring.datasource.password=Y.sa123456
spring.jpa.hibernate.ddl-auto=create
spring.jpa.show-sql=true以上只是一些关键代码,所有代码请参见下面代码仓库
代码仓库
- GitHub - Harries/springboot-demo: a simple springboot demo with some components for example: redis,solr,rockmq and so on.(SqlServer)
4.测试
启动Spring Boot应用
新增
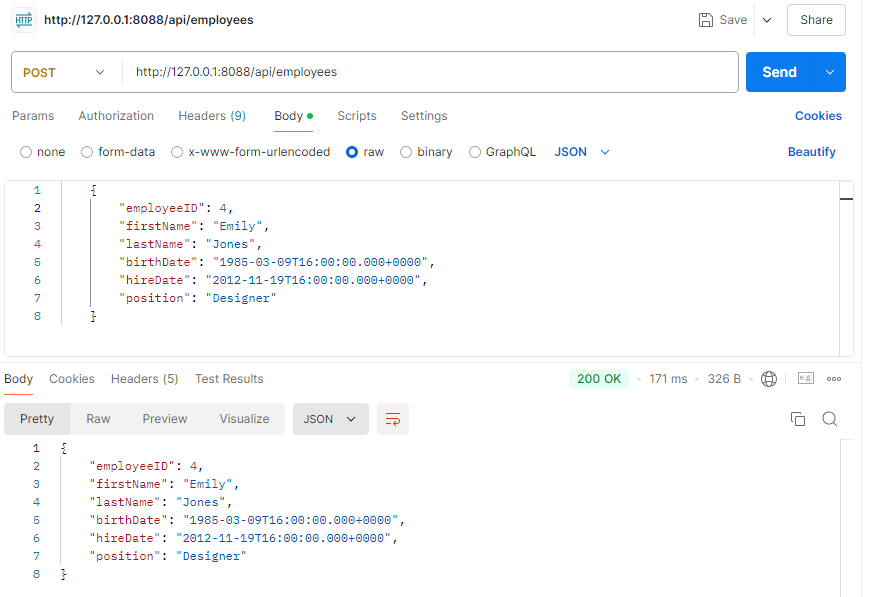
查询列表
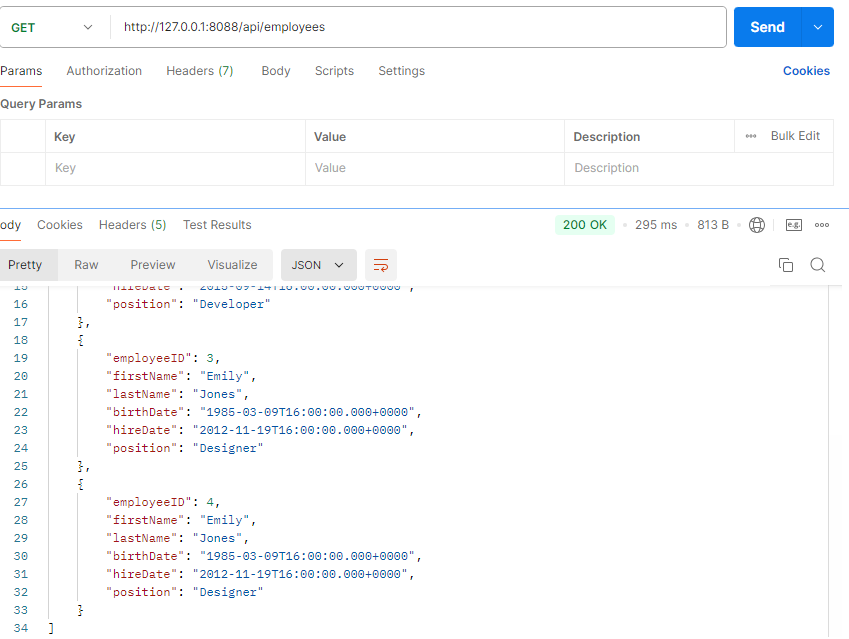
5.引用
- SQL Server technical documentation - SQL Server | Microsoft Learn
- Spring Boot集成SQL Server快速入门Demo | Harries Blog™