益阳网站制作公司地址网站模板制作教程视频教程
为了让镜像文件在mac 和windows平台通用, 所以需要将.dmg格式的镜像文件转换为.iso文件, 转换方法也非常简单, 一行命令即可
hdiutil convert /path/to/example.dmg -format UDTO -o /path/to/example.iso转换完成后的文件名称默认是 example.iso.cdr 这里直接将.cdr后缀删除即可
另外一个方法也可以通过mac系统中的 磁盘工具.app 来转换dmg为cdr/iso格式镜像, 方法如下:
1. 加载.dmg镜像;
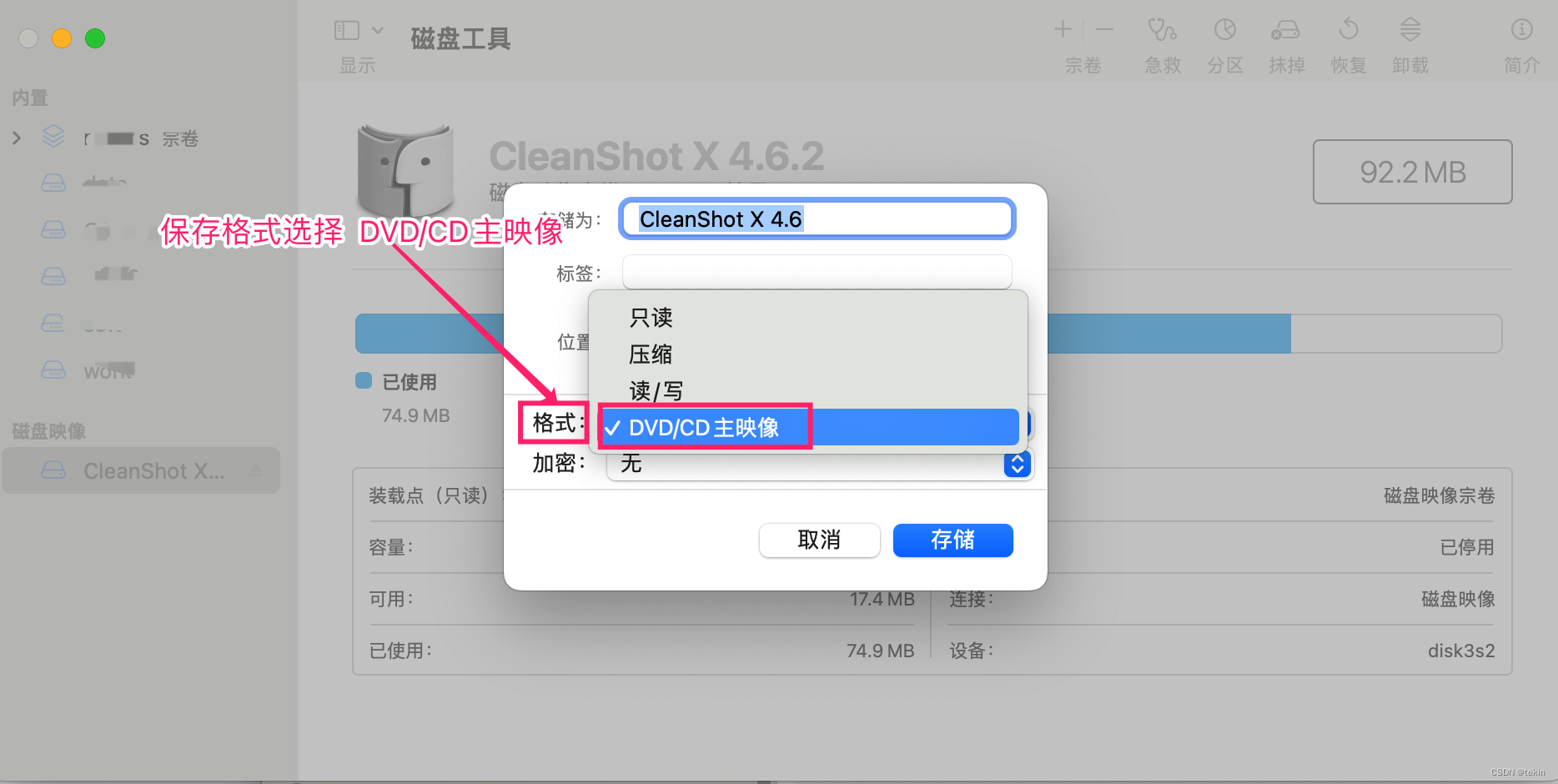
2. 打开 磁盘工具.app 选择 文件 --> 新建映像--> 基于 xxx 新建映像 然后选择保存路径和名称即可, 格式选择 DVD/CD主映像 然后保存后镜像的格式就是 .cdr / .iso 格式了.
下图以 CleanShot_X_4_6_2.dmg 镜像转换为 CleanShot_X_4_6_2.iso 镜像为例