上海植物租赁做网站明年做哪些网站能致富
目录
1.模型训练
2.模型验证
3.模型融合
4.模型部署
上节课我们讲了模型设计、特征工程,这节课我们来讲模型构建剩下的三个部分:模型训练、模型验证和模型融合。
1.模型训练
模型训练就是要不断地训练、验证、调优直至让模型达到最优。
那么怎么达到最优呢?就是要绘制一条比较好的决策边界。
决策边界
就是在符合某种条件做出某种选择的条件,根据这个条件可以将结果进行划分。
比如说:下午6:00不写完这篇博客我不吃饭,那么写完了就去吃,没写完就不吃。这个条件就是我们说的决策边界。
决策边界分为:线性决策边界和非线性决策边界。下图中,图1为线性决策边界,图2、图3为非线性决策边界。

决策边界曲线的平滑程度和算法训练出来的模型能力息息相关。曲线越陡峭模型的测试精度越准确,但是越陡峭的曲线模型越不稳定。
所以为了找到好的决策边界划分结果,我们需要找到稳定性和准确率的平衡点。使用专业术语来讲,我们就是需要找到泛化能力和拟合性能都好的平衡点。
通常,算法工程师会使用交叉验证来找到模型参数的最优解。
总结:模型训练就是要找到一个划分条件(决策边界),使得准确率(拟合)最高的同时兼顾稳定性(泛化性能)。
交叉验证
这里举例10折交叉验证法。如果一个样本集中有10个样本数据,对数据进行1-10的标号。
先使用1-9号标号的数据作为训练集,将10号标号的数据作为测试集。
接着将9号标号的数据作为训练集,其他数据作为测试集。
接着将8号标号的数据作为训练集,其他数据作为测试集。
……
依次类推,然后将测试结果取出平均值。
如果这里有100个样本,我们先将100个样本随机分成10组,将每一组按照这样的方式进行测试,然后10组再取平均值。

2.模型验证
算法工程师为了模型预测结果更加准确,将模型构建的比较复杂,越复杂的模型越依赖于训练集,但是越依赖训练集的模型泛化能力越差,造成过拟合的情况。
算法工程师为了使模型的泛化性能好一点,就降低模型的复杂度,这样就造成了准确率不高,也就是欠拟合。
下图的偏差我们可以看作误差率,而方差可以看作泛化能力。可以类比为我们这里的欠拟合和过拟合情况。
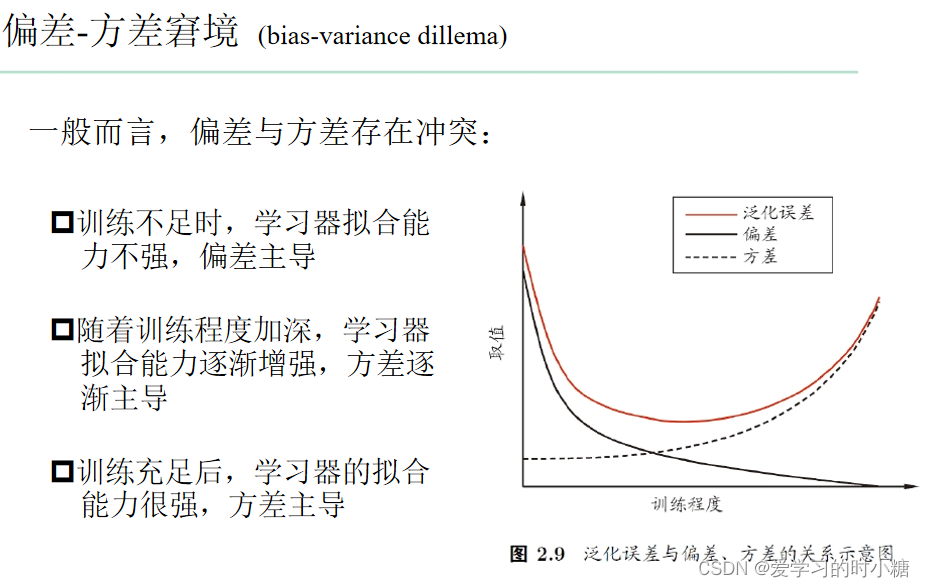
所以算法工程师在模型训练的绝大多数时间就是在找两者的平衡点,找到适合的参数。但是有时候我们以为的最优解并不是真正的最优解,所以我们需要模型验证工作。
模型验证分为两部分:模型性能和模型稳定性。
模型性能:简而言之就是模型的预测准不准确。具体的评估指标有具体章节来讲。
模型的稳定性:就是模型的效果可以持续多久?我们使用PSI指标来判断模型的稳定性,具体的计算方法和合理范围我们后面也会讲到。
基于此我们知道我们需要了解模型的性能指标、稳定性指标以及其合理范围才能够进行模型的验证,判断模型的好坏。
3.模型融合
我们以前谈到的例子都是使用一个模型来讲的,但是为了解决多种具体细节问题,算法工程师往往需要建立多个模型才能获得最佳的效果,此时就要考虑到模型的融合问题。
模型融合就是同时训练多个模型,然后融合集成在一起提高整体的准确率。
我们可以了解一些基本的融合方法,如下面的思维导图中的方法。
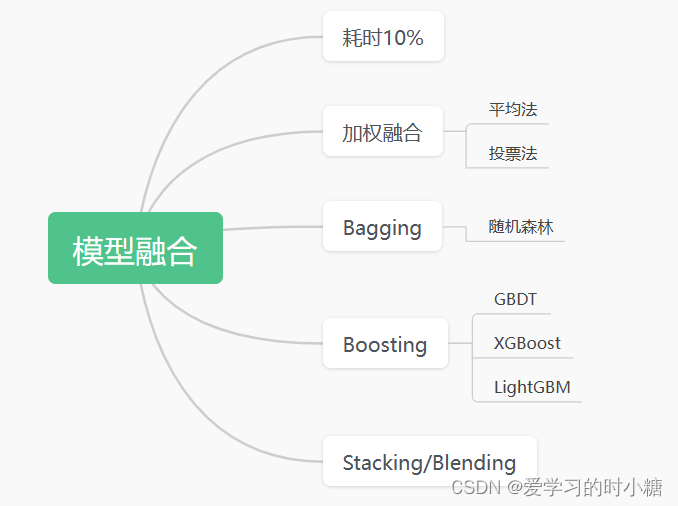
想要详细了解融合算法的可以看看下面两篇文章,有上面讲到的方法:【知出乎争】模型融合方法总结 - 知乎 (zhihu.com)
【机器学习】模型融合方法概述 - 知乎 (zhihu.com)
对于回归模型而言加权平均就是采用算术平均或加权平均的方法来融合。 对于分类问题而言,通常采用投票法来进行融合,就是把概率最大的,票数最多的作为结果。
在模型融合的过程中,产品经理需要做一个考虑成本问题。有时候算法工程师可能为了提升AUC(模型预测效果)的一个点,增加特征规模,导致模型部署成本增加,所以我们要注意一下。
4.模型部署
算法部门和研发部门是两个团队,为了降低彼此的依赖性,算法模型部署成独立的任务,然后暴露一个HTTP API给工程团队来调用。
我们需要根据业务场景选择离线/实时的部署。如果我们要实时的预测用户的UGC类别,那么我们的模型就要部署成在线的web服务并提供实时响应的API接口。如果模型只是需要对一段时间已有的数据进行分类,那么我们模型只需要部署成离线的就可以啦!