网站技术支持是什么wordpress 本地数据库
本期主题:程序的编译过程和gcc/g++的使用
博客主页:小峰同学
分享小编的在Linux中学习到的知识和遇到的问题
小编的能力有限,出现错误希望大家不吝赐

🍁 1.背景知识
预处理(进行宏替换,去注释,头文件的展开,条件编译)
编译(生成汇编)
汇编(生成机器可识别代码)
连接(生成可执行文件或库文件)
🍁 2.gcc如何完成编译
格式: gcc /g++[选项] 要编译的文件 [选项] [目标文件]
2.1.预处理(进行宏替换)
预处理功能主要包括宏定义,头文件的展开,条件编译,去注释等。
预处理指令是以#号开头的代码行。
实例: g++ –E test.cpp –o test.i
选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。
选项“-o”是指目标文件,“.i”文件为已经过预处理的C++原始程序
写一段测试代码


执行指令

用vim打开预处理后的test.i文件。
并和源文件进行比对:可以清楚的看到预处理阶段,源程序做的那些事情。
可以看到预处理后的还是C语言的程序。

结果就是这个

可以测试条件编译(在源文件里面定义,和在外面定义都一样)
也就是宏的命令行定义。

深层理解:
我们可以看到,预处理阶段,会把头文件拷贝到源文件里面,所以这个头文件一定在我们系统中存在,或者在库中存在,就相当于我们在某一个平台写代码的时候,这个头文件不是写着玩的,而是这个必须在系统中确确实实存在,在Linux下的头文件在 " ./usr/include/stdio.h"。
头文件存在的意义:
帮我们写代码,支持代码自动补齐。
可以使用vim打开看一看系统中的头文件,


2.2.编译(生成汇编)
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查 无误后,gcc 把C语言代码翻译成汇编语言。 用户可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。 实例: gcc –S test.i –o test.s
打开里面是汇编语言,都是一些助记符,这就汇编语言。汇编语言和体系结构有很大关系。

但是汇编语言并不能被计算机直接执行,下一步就是汇编生成二进制
2.3.汇编(生成机器可识别代码)
汇编阶段是把编译阶段生成的“.s”文件(汇编语言)转成二进制目标文件 读者在此可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码了 实例: gcc –c test.s –o test.o
执行汇编阶段的指令

用vim打开汇编阶段生成的 二进制目标文件。
可以看到此时我们已经看不懂了。

只能使用指令: "od test.o" 用二进制方式打开。

深入理解:
这里已经是一个机器可以识别的二进制目标文件,但是还是不能被执行。上面的三个步骤都只是在编译自己的代码,最后我们还要进行最后一步,就是链接c标准库,我们调用的一系列C语言函数,都是c标准库里面提前写好的,并且以及完成前三部预处理,编译,汇编。也是一个二进制目标文件。
2.4.连接(生成可执行文件或库文件)
把你写的代码和c标准库中的代码合起来。生成一个可执行程序。
实例:gcc test.o -o test
链接完成后就生成了可执行程序(可执行的二进制文件,包含库加你的代码)

帮助记忆:
看见盘的左上角 ESc 分别对应预处理,编译,汇编的指令。形成的临时文件对应后缀为 iso
gcc -(ESc) ------ test.(iso)
🍁 3.函数库(重要知识点)
3.1.动态链接和静态链接(感性的认识)
重要前提:
我们要清楚我们自己写的代码,和库是两码事。C标准库是别人已经给我们准备好的,让我们直接使用。我们的程序中用到的C语言函数(scanf ,printf,,,),其实我们自己只是写了函数的调用,并没有对应的实现!只有在链接的时候,对应的实现,才和我们的代码关联起来了。
链接的本质:
我们调用库函数的时候,和标准库是 怎么进行关联的。关联方式不同就是动态链接和静态链接的不同。
3.2.动态链接和静态链接(具体认识)
举个好认识的例子:小明去网吧的例子。



先直接编译链接出一个可执行程序

file test ,查看文件的具体信息。

ldd test :查看可执行程序依赖的动态库列表。

可以看到 Linux下默认使用的动态链接,使用的是静态库。
在Linux下库的命名:
动态库:libXXXX.so(XXXX为库的名称)
静态库:libXXXX.a(XXXX为库的名称)
选项-static 使用静态链接(注意自己是否安装静态库,后面有安装说明)

首先我们看到 静态链接的可执行程序大小比动态链接多很多。
Linux下的指令都是使用的动态库,所以电脑的动态库一定不能删除。
用这个库只有一个,但是这么多指令,这么多C语言成语程序,所以动态库也叫共享库。
所以以后我们写好的C语言程序我们就可以直接使用,可以共享同一个共享库。


静态链接的时候和动态库没有关系,拷贝的是"libc.a"静态库的东西。


一般系统会自动携带动态库:因为系统运行也需要动态库
不会自带静态库,需要我们自己安装静态库。
安装静态库指令:sudo yum install glibc -static

file静态链接的可执行程序。就可以看到静态链接完成。

3.3.c++的动静链接
c++中也和C语言相同默认是动态链接。
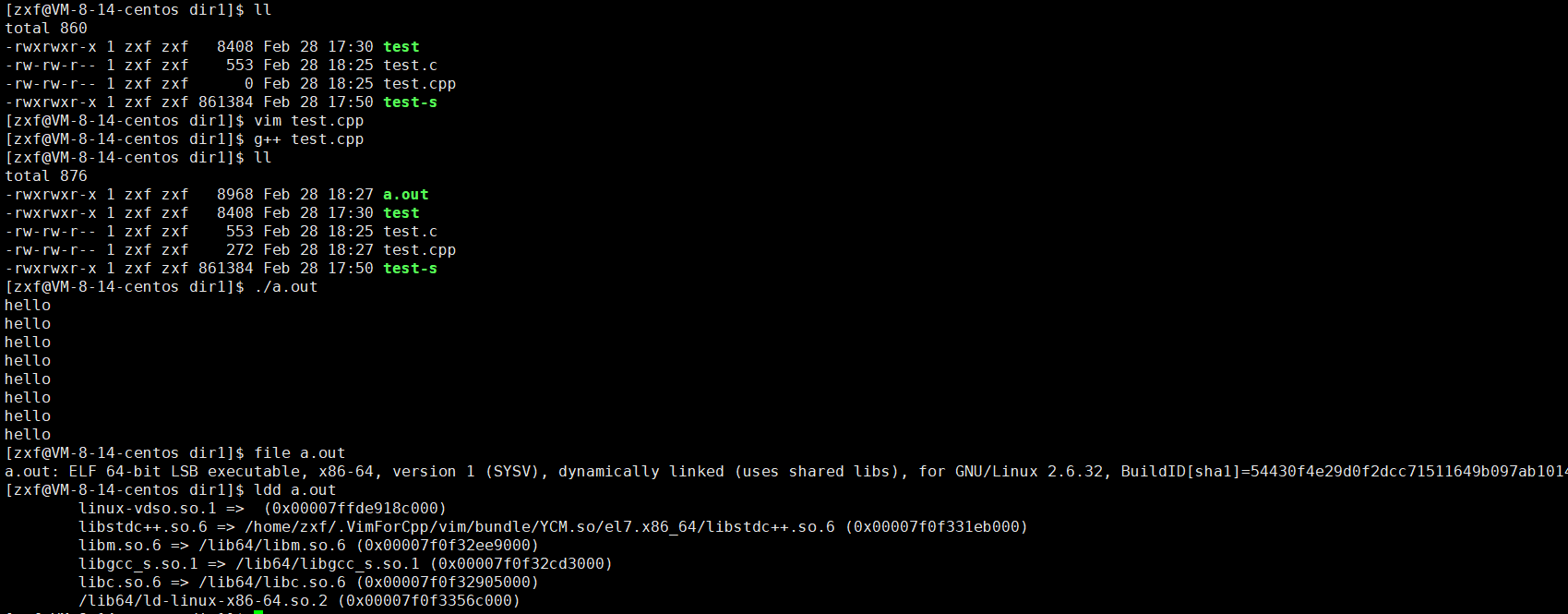
可以看到c++也有自己的动态库。
也可以-static 静态链接,也是需要自己安装的。
安装指令:sudo yum insatll -y libstdc++-static
和C语言相同。
系统为了支持我们编程,会给我们提供:标准库和标准库的 ".h"。
所以得到:我们的代码+库中的代码 == 可执行程序
上面我们讲到的,不只是在Linux下有效,在Windows下也是一样的原理。
window下的:
静态库:xxxx.dll
静态库:xxx.lib
🍁 4. gcc选项
-E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面 -S 编译到汇编语言不进行汇编和链接 -c 编译到目标代码 -o 文件输出到 文件 -static 此选项对生成的文件采用静态链接 -g 生成调试信息。GNU 调试器可利用该信息。 -shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库. -O0 -O1 -O2 -O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高 -w 不生成任何警告信息。 -Wall 生成所有警告信息。