类似于pinterest的设计网站上海网站开发团队
背景:很多时候我们需要jmeter调用接口,可是某些参数是需要做处理才可以得到的,比如参数为特定格式的zip包,或者文件名为特定的格式。我个人偏向打成jar包调用方法,因为jmeter中调试不方便。这样我们就可以在IDE中写好方法,然后打包成jar,在jmeter中调用。
1.要想使用jar包中方法的返回值做为参数,那么方法必须有返回值;
2.在项目的根目录下,使用【Git Bash Here】,然后输入命令【mvn clean package】就会生成jar包;
3.将jar包放到jmeter的lib目录中,重启jmeter;
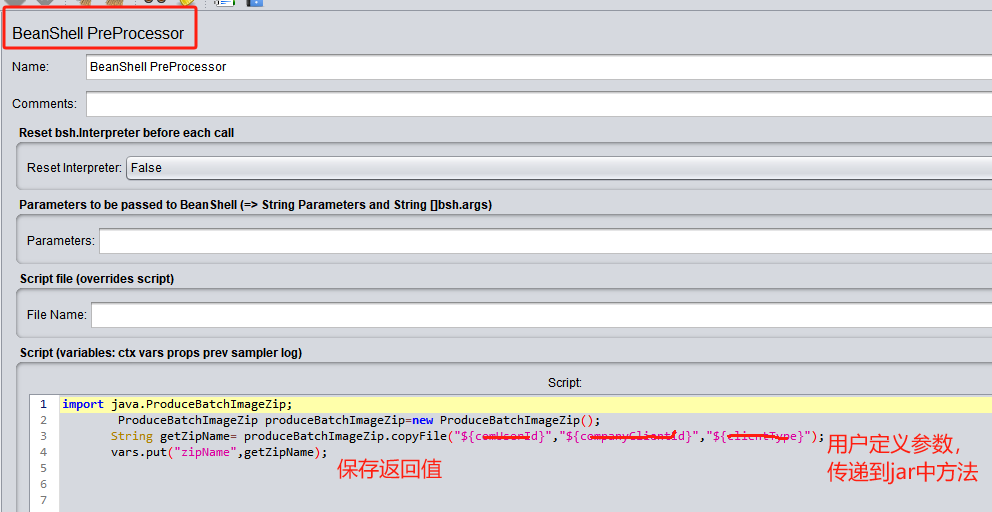
4.jmeter中请求添加BeanShell PreProcessor,导入方法对应的类,然后调用方法,再将返回值保存;同时调用方法时,也可用通过${}传递参数;
import java.ProduceBatchImageZip;ProduceBatchImageZip p=new ProduceBatchImageZip();String getZipName=p.copyFile("${name}","${password}","${clientType}");//调用方法vars.put("zipName",getZipName);//将返回值保存
5.请求可以直接通过${zipName}使用;
