山西网站建设推广网站开发与网页制作
前后端分离项目,前端在开发中使用proxy代理解决跨域问题,打包之后无效。
未配置前无法访问
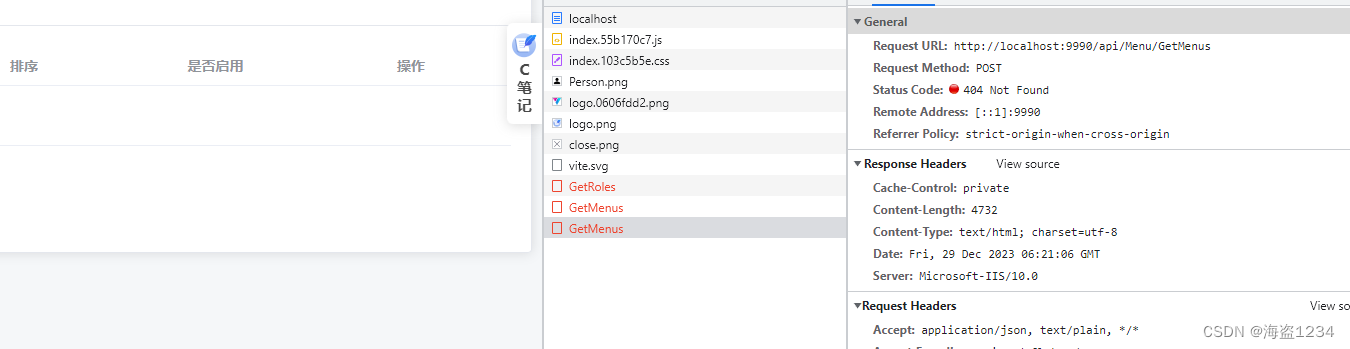
部署环境为windows +IIS,要在iis设置反向代理
安装代理模块
需要在iis中实现代理,需要安装Application Request Routing Cache和URL重写(URL Rewrite)两个模块
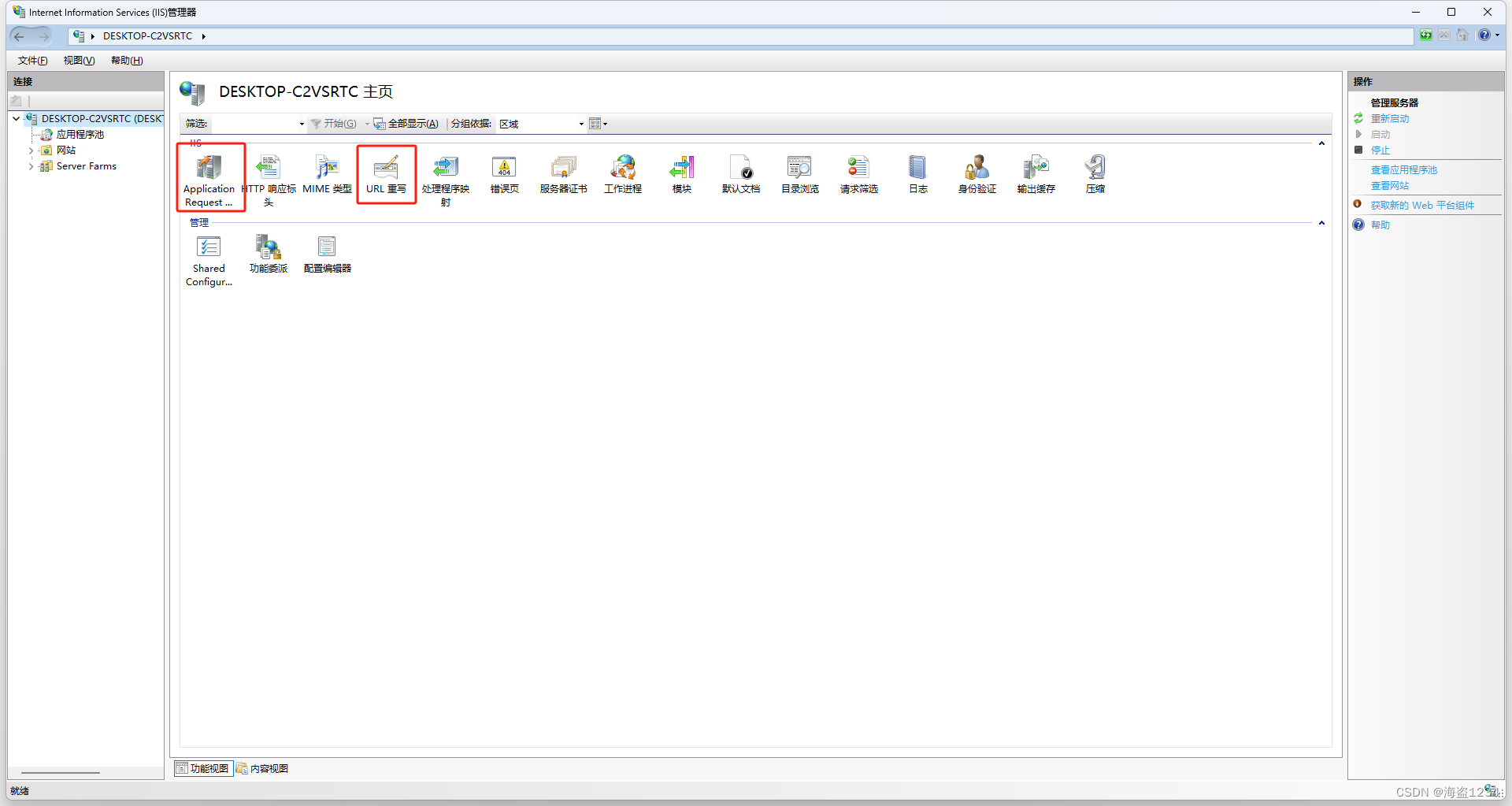
默认IIS没有这两个模块,需要自己下载安装
ARR(Application Request Routing Cache):
https://www.iis.net/downloads/microsoft/application-request-routing
URL重写:
https://www.iis.net/downloads/microsoft/url-rewrite
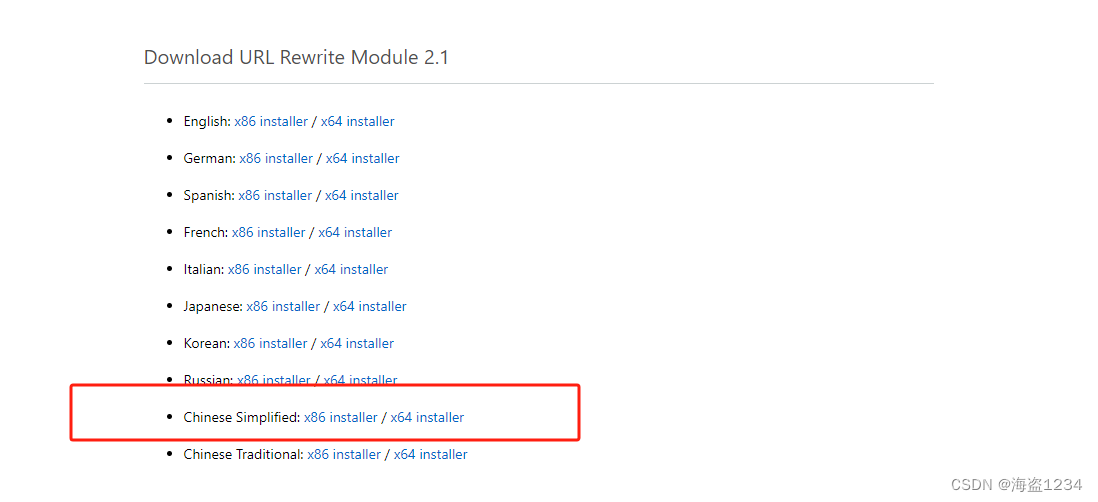
下载安装完成之后,关闭IIS的窗口,重新打开就会出现安装的模块
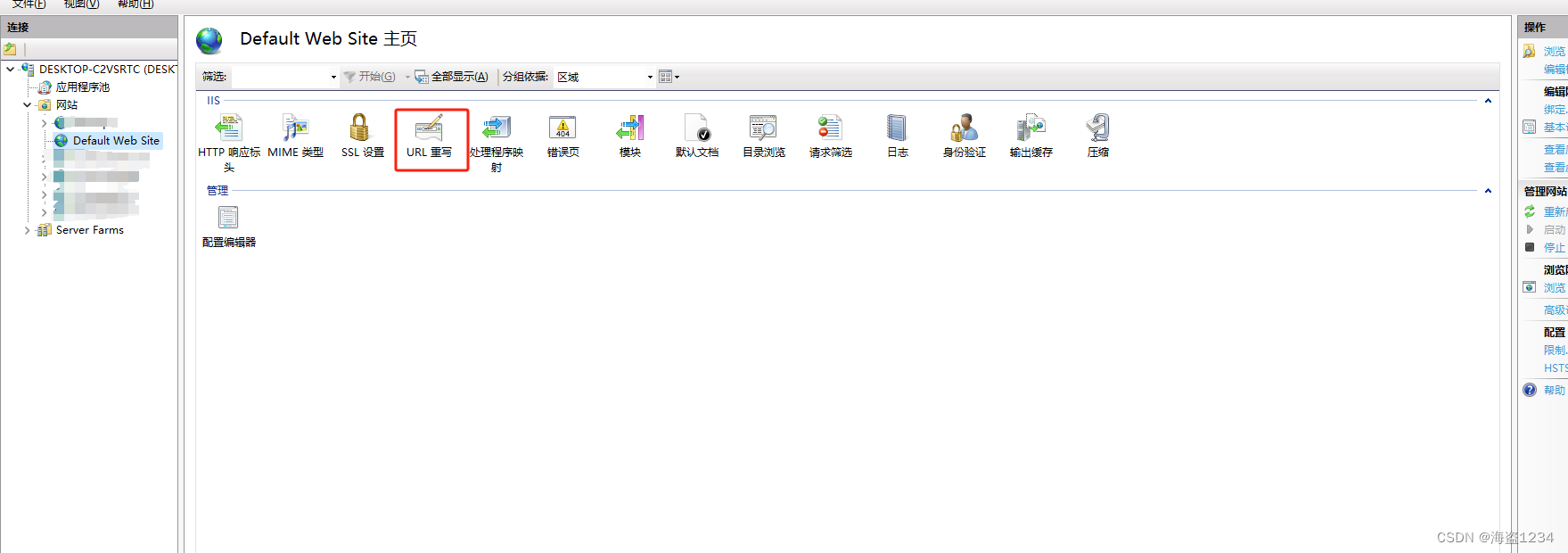
注意:只有IIS服务器主页才有Application Request Routing模块,网站页面下锚只有URL 重写模块
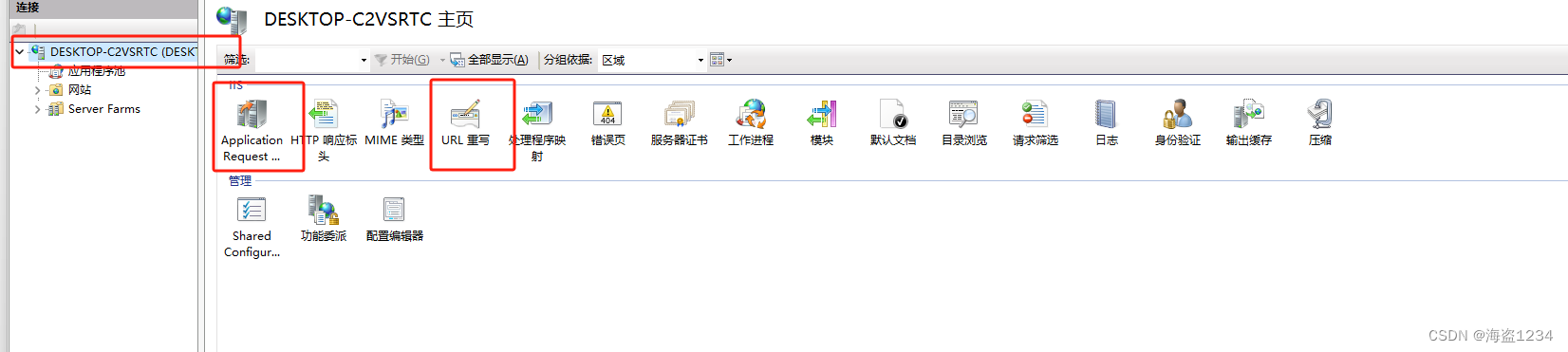
iis部署网站和前后端项目的步骤不在此处介绍,默认已经部署好了
可以查看另一篇IIS安装配置和简单网站部署流程
启动代理
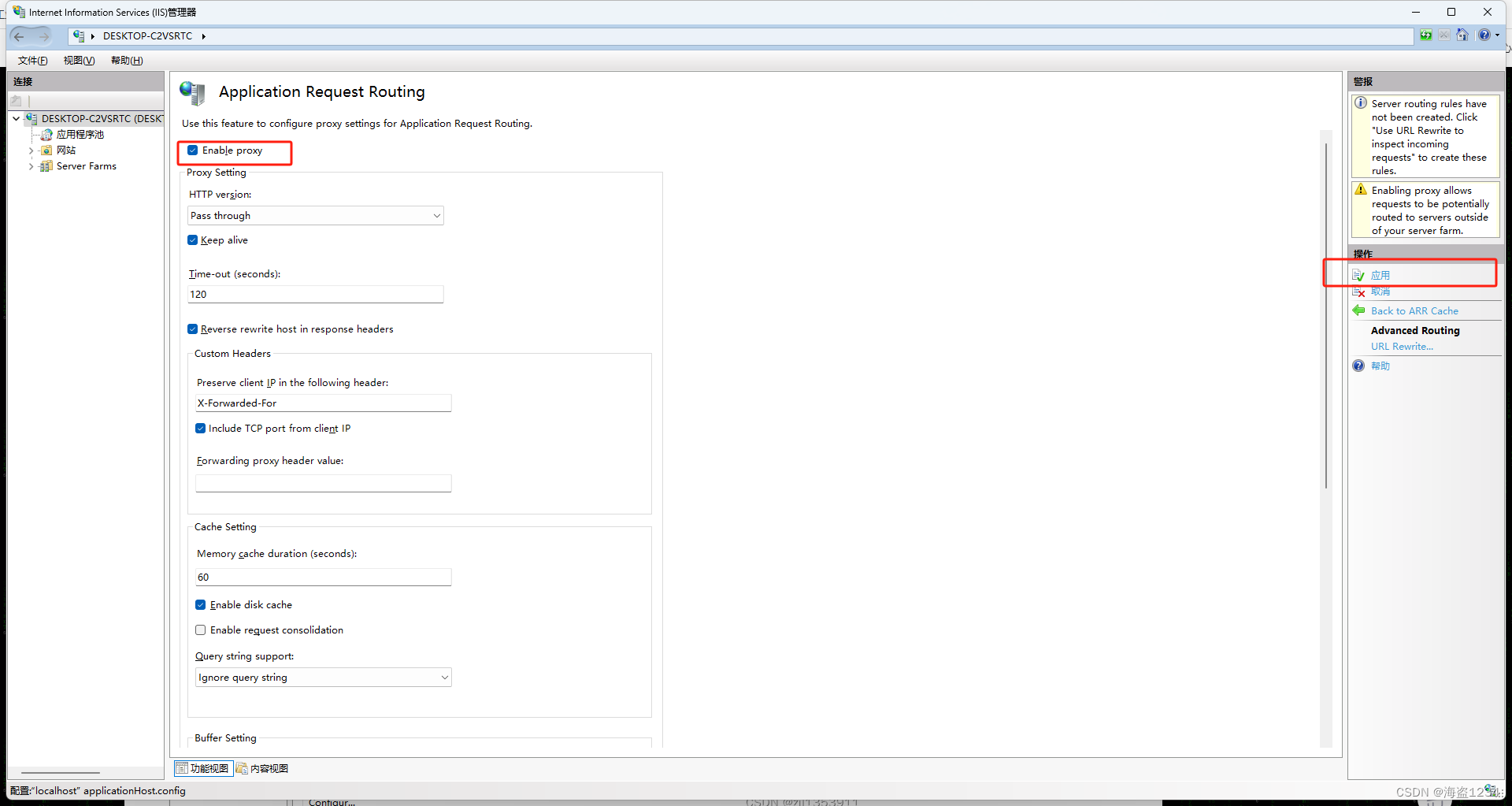
- 在IIS主页中,打开Application Request Routing模块,可以点击右侧“打开功能”或者双击
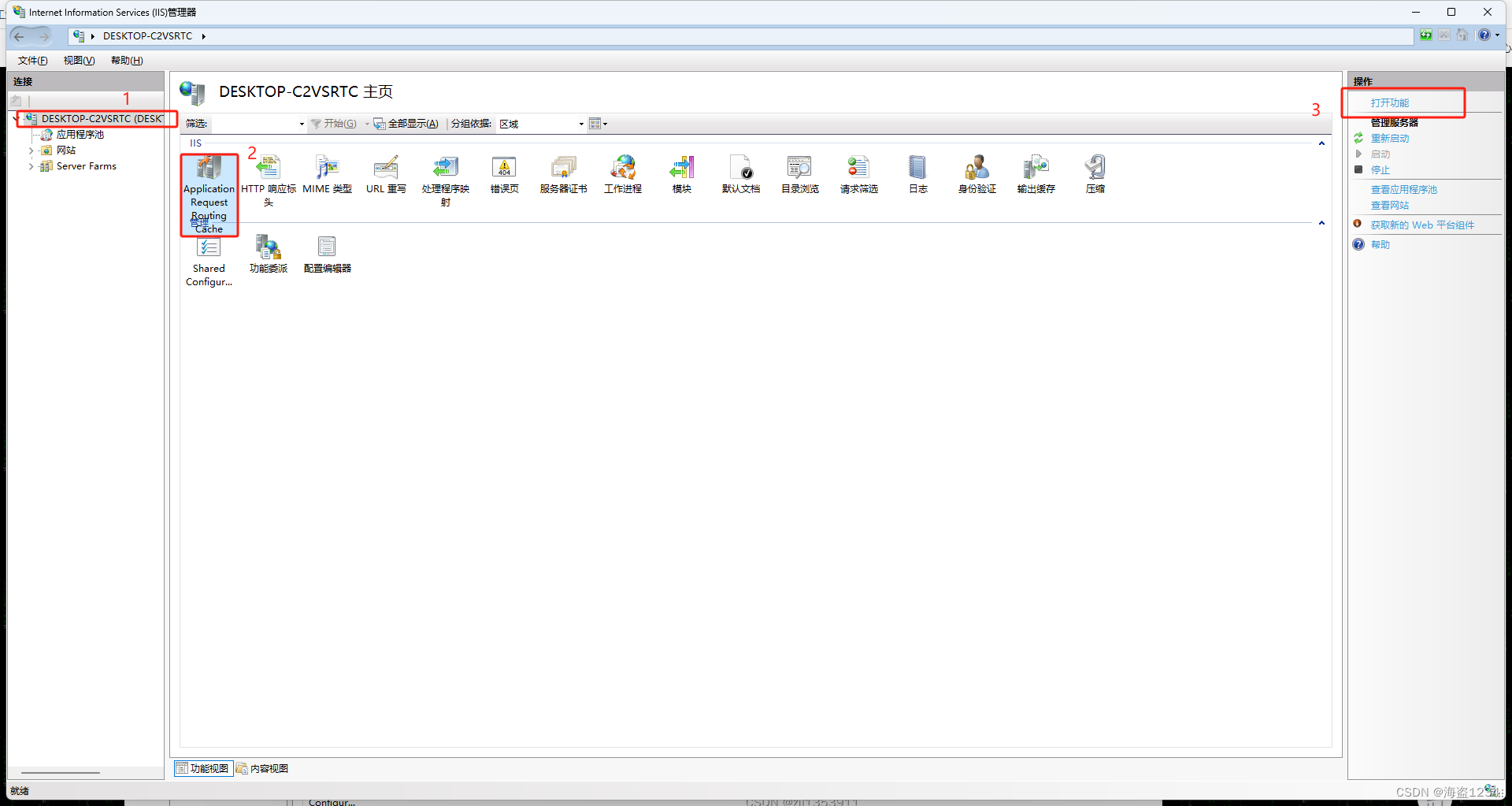
- 点击代理设置(Server Proxy Settings),进入设置界面
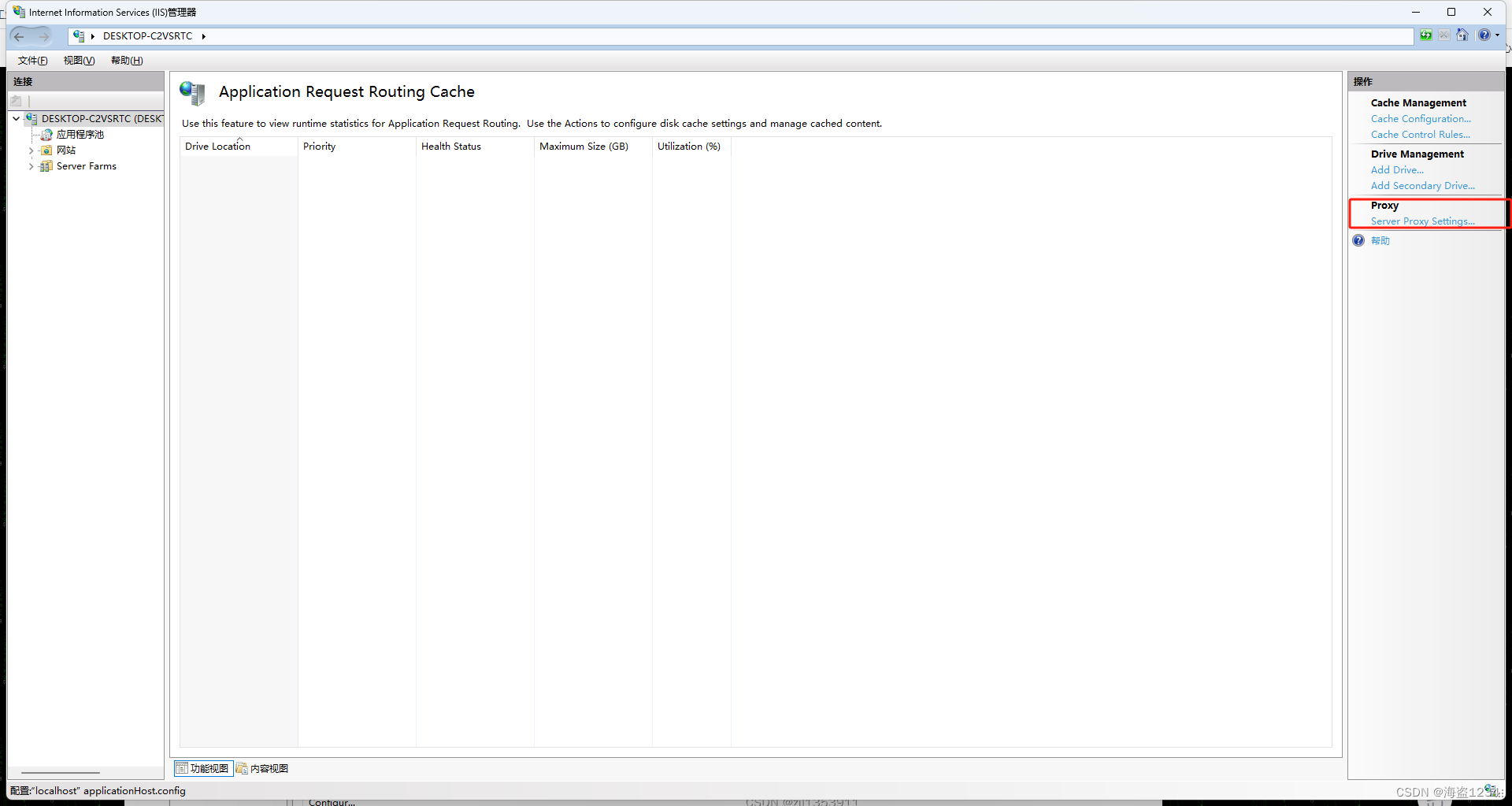
- 启用代理
勾选“Enable proxy”,其他不用修改,然后点击右侧“应用”,才能完成设置
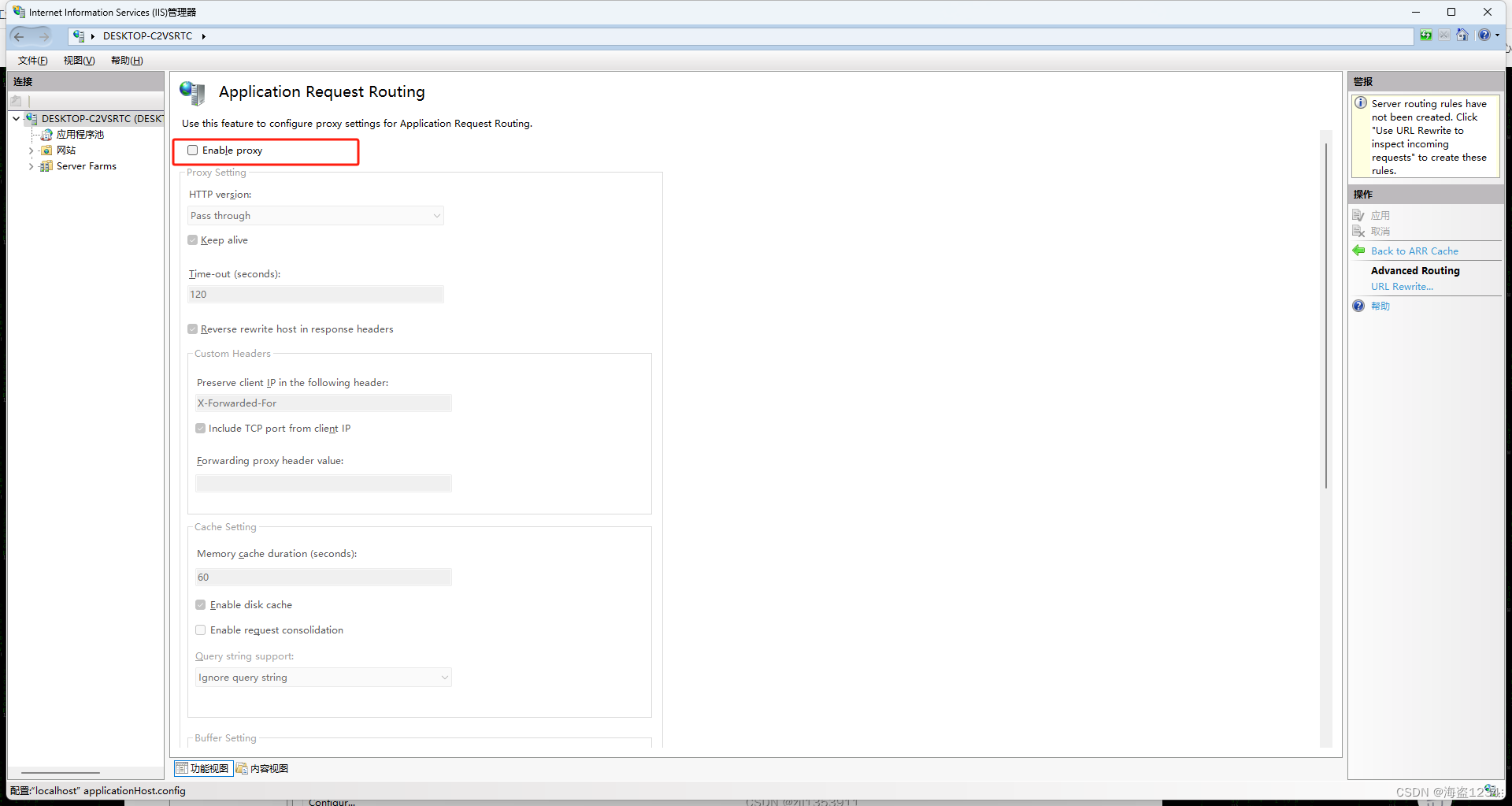
(点击右侧“应用”,只有点击应用了才算完成修改)
配置代理规则
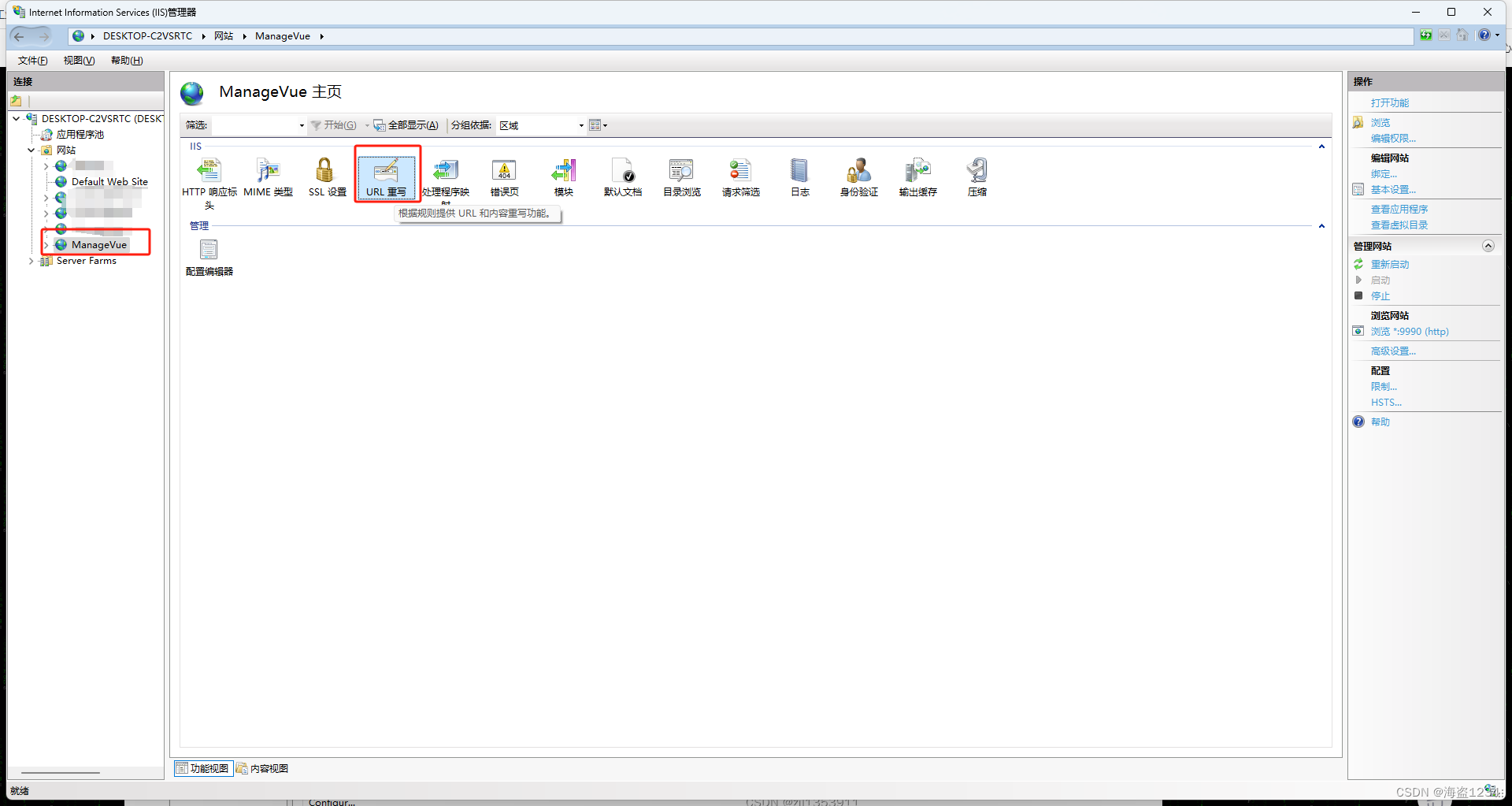
选择要配置的网站/前端项目,点击“URL重写”进入配置
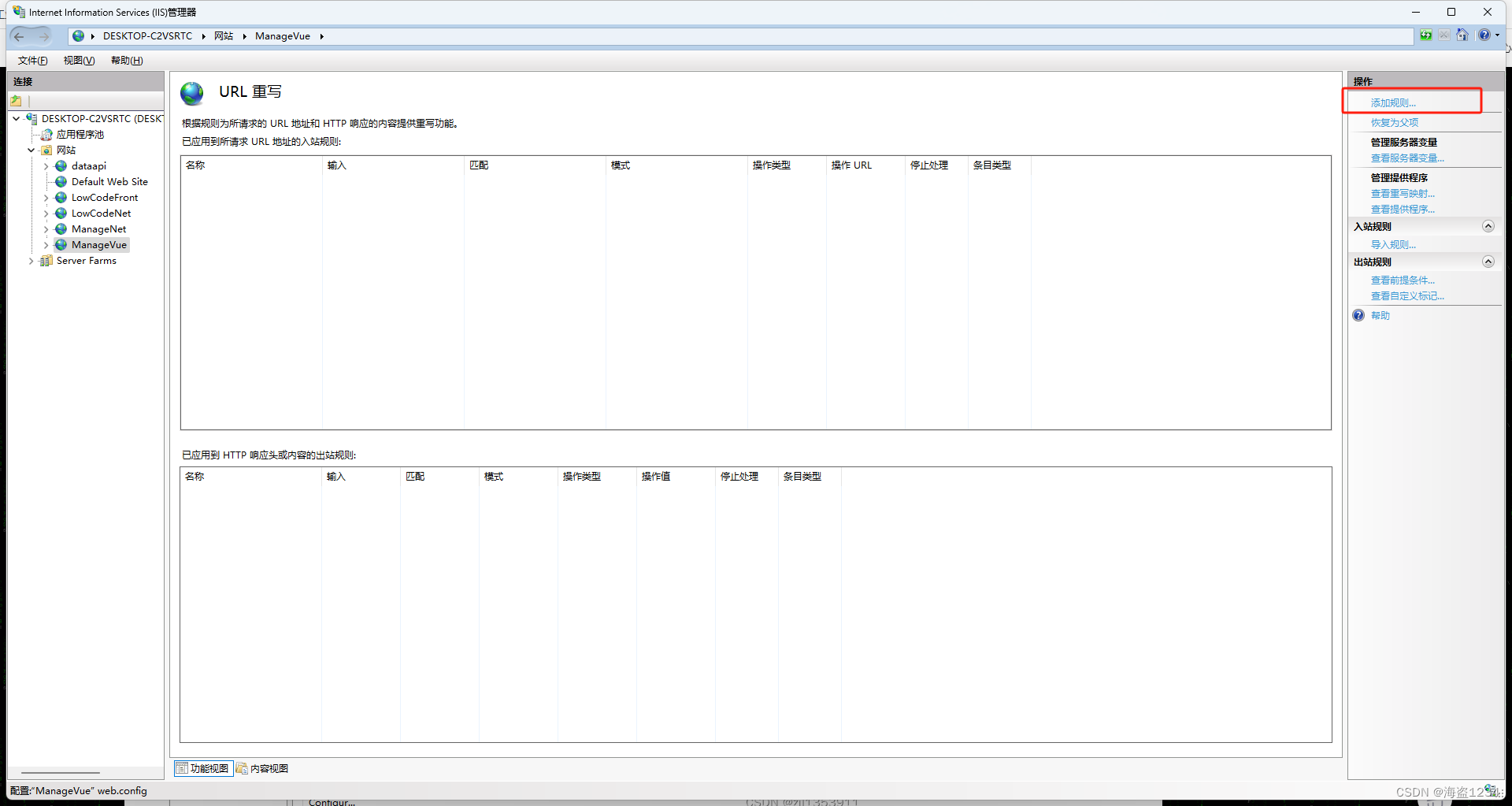
添加规则
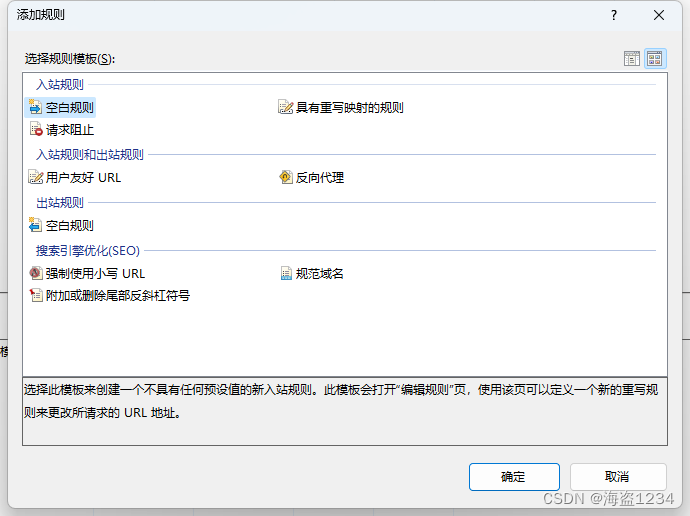
选择“空白规则”,进入配置
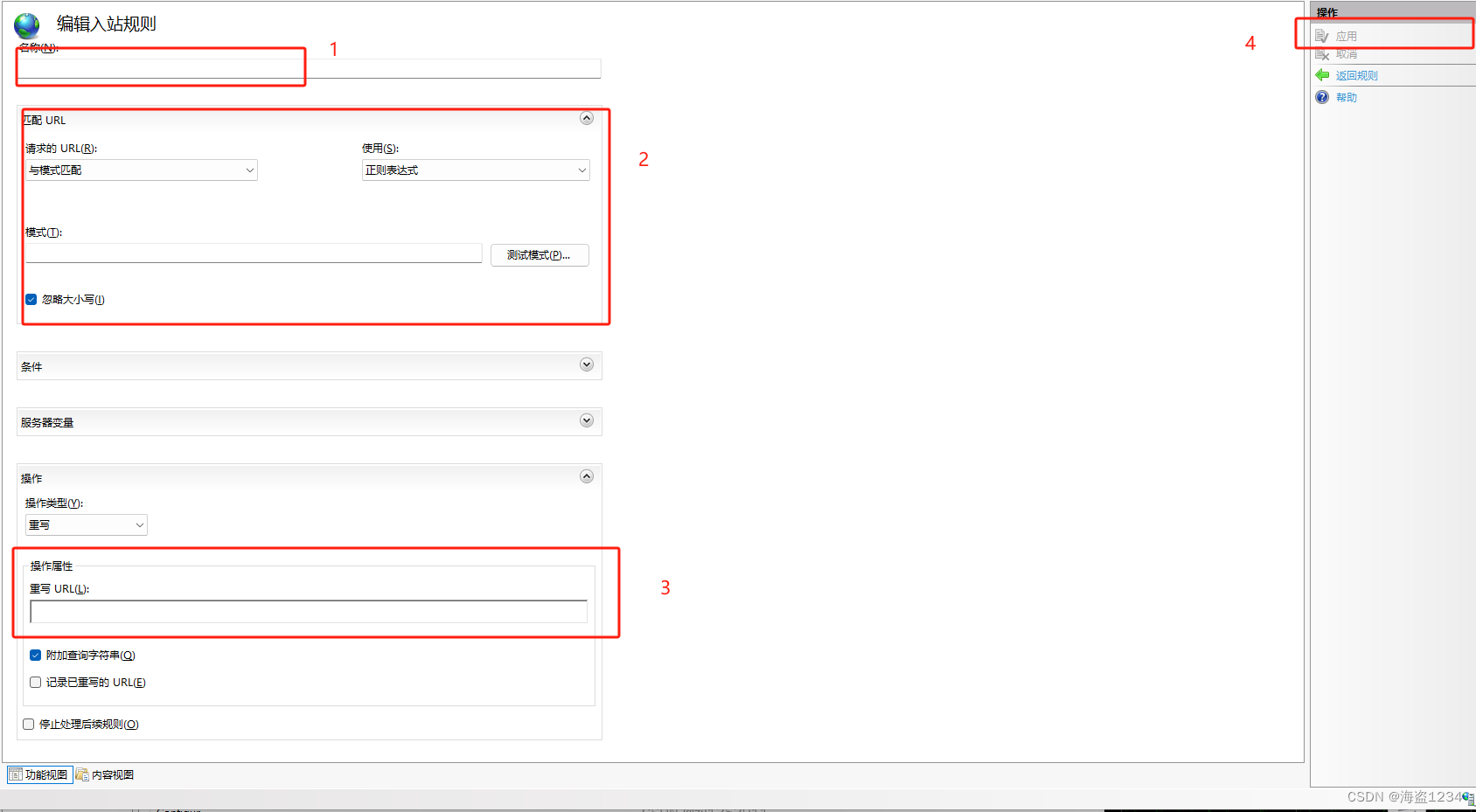
配置具体规则
- 输入规则名称
- 匹配URL的方式
- 对URL重写的规则
- 编辑完成点击应用生效
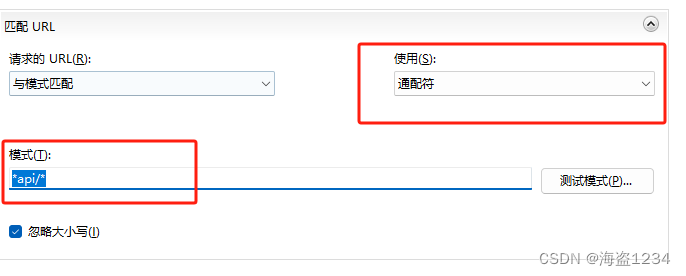
匹配URL的配置
首先匹配URL的规则,最常见的就是重写后端请求的api接口,转发一个端口
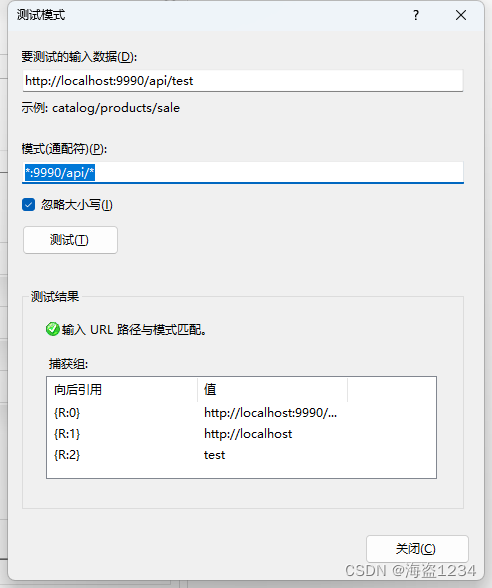
写完规则可以使用测试模式,测试对应的url,并且测试结果的向后引用,可以在重写操作中使用,测试中测出自己想要的方式。
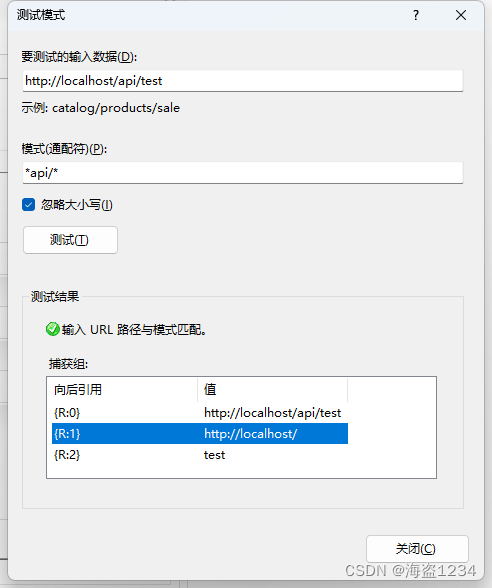
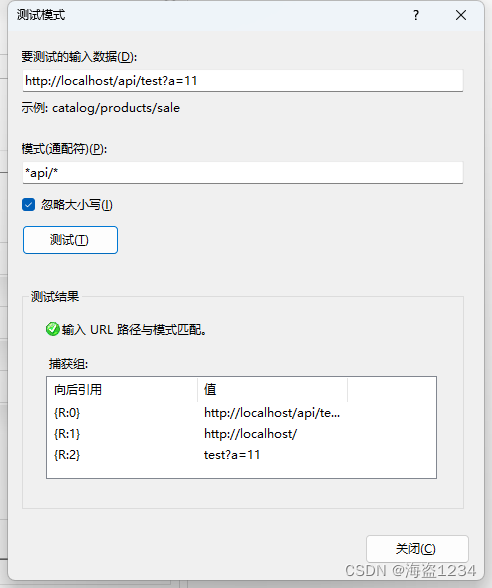
测试配置
在这里想把前端9990请求的api接口转到后端9991的配置
配置操作
结合上面测试的向后引用,编写需要重写的URL操作,然后确认应用
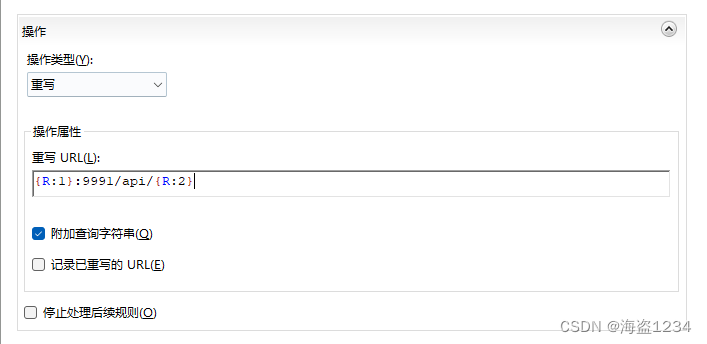
完成配置
配置完成点击应用 ,可以在URL重写模块界面看到具体的配置
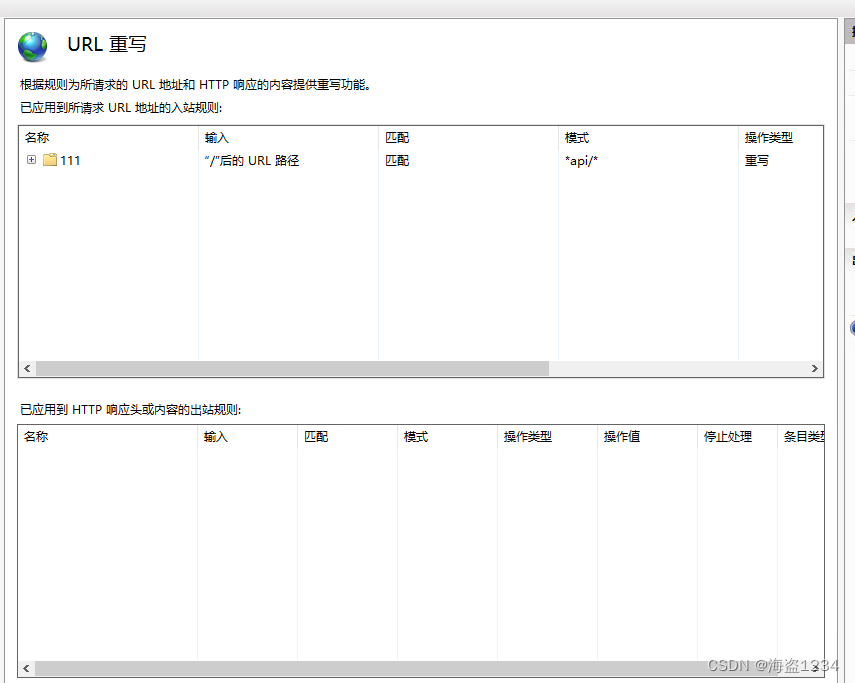
然后在物理路径下面会生成一个web.config文件,到处配置完成,就能正常访问
