做户型图的网站wordpress微信扫码登录
目录
一、三层路由
1. 定义
2. 交换原理
3. 操作演示
3.1 图示
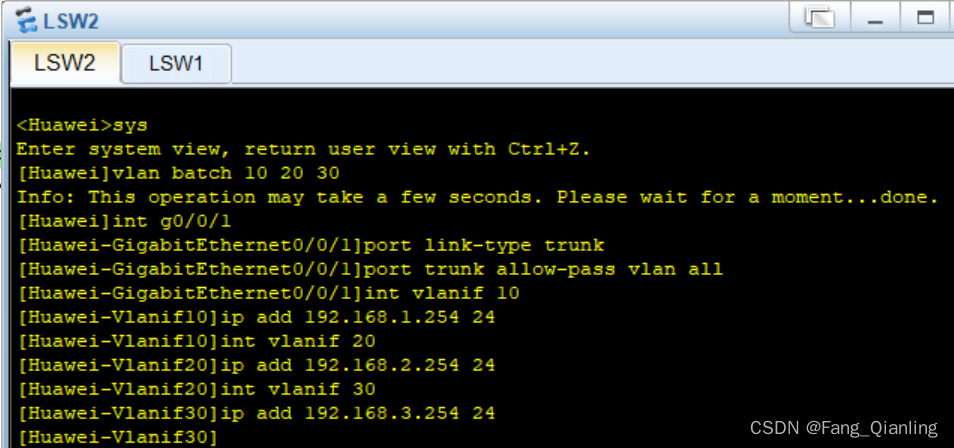
3.2 LSW1新建vlan10、20、30,分别对应123接口均为access类型,接口4为trunkl类型,允许所有vlan通过
3.3 LSW2新建vlan10、20、30,配置接口1为trunk类型,允许所有vlan通过;三个vlan分别配置虚拟接口和IP地址
3.4 LSW2配置vlan100虚拟接口和IP,选择access接口类型,且该接口默认属于vlan100;添加往PC4方向静态路由配置编辑
3.5 配置路由器接口IP,并且接口1配置为默认路由
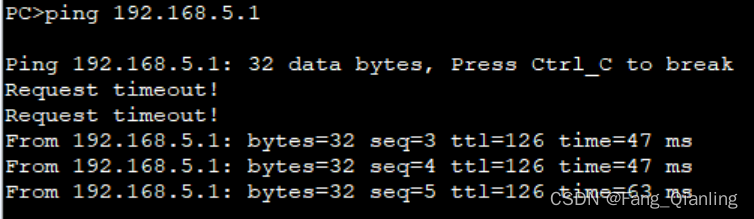
3.6 测试网络
二、DHCP
1. 定义
2. 使用DHCP的好处
3. DHCP的分配方式
4. DHCP租约过程
4.1 定义
4.2 图示
4.3 过程叙述
5. 操作演示
5.1 图示
5.2 配置接口IP地址、选择接口模式、设置租期时限、DNS
5.3 查看网络信息
5.4 抓包验证
5.5 图示
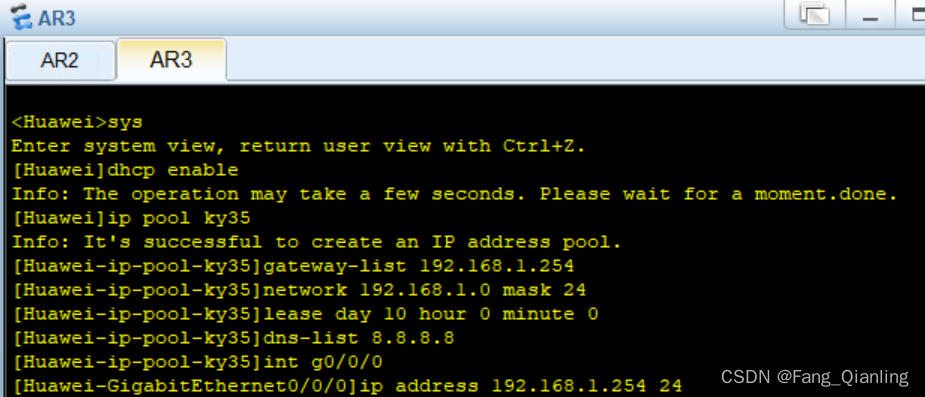
5.6 创建IP地址池ky35,配置出口网关地址、网段子网掩码、租期、DNS
5.7 查看网络信息
三、VRRP
1. 概述
2. 结构
2.1 状态机
3. VRRP主备路由器切换过程
4. VRRP路由器的抢占功能
5. VRRP路由器的优先级
一、三层路由
1. 定义
三层交换其实就是二层交换和三层转发的结合,使用三层交换技术实现不通VLAN间通信。
2. 交换原理
一次路由多次交换。三层交换机上,第3层引擎处理数据流的第一个包,只会查找一次路由表,然后形成mls条目,后续的包按照mls条目转发。
3. 操作演示
·不同vlan实现网络互通,4台PC分别配置对应网关192.168.x.254
3.1 图示

3.2 LSW1新建vlan10、20、30,分别对应123接口均为access类型,接口4为trunkl类型,允许所有vlan通过

3.3 LSW2新建vlan10、20、30,配置接口1为trunk类型,允许所有vlan通过;三个vlan分别配置虚拟接口和IP地址
3.4 LSW2配置vlan100虚拟接口和IP,选择access接口类型,且该接口默认属于vlan100;添加往PC4方向静态路由配置
3.5 配置路由器接口IP,并且接口1配置为默认路由

3.6 测试网络
二、DHCP
1. 定义
DHCP(Dynamic HostConfiguration Protocol,动态主机配置协议),由Internet工作任务小组设计开发,专门用于为TCP/IP网络中的计算机自动分配TCP/IP参数的协议(包含参数:IP、子网掩码、网关、DNS)。
2. 使用DHCP的好处
① 减少管理员的工作量
② 避免输入错误的可能
③ 避免IP地址冲突
④ 当更改IP地址段时,不需要重新配置每个用户的IP地址
⑤ 提高了IP地址的利用率
⑥ 方便客户端的配置
3. DHCP的分配方式
① 自动分配:分配到一个IP地址后永久使用(一般不使用)
② 手动分配: 由DHCP服务器管理员专门指定IP地址
③ 动态分配: 使用完后释放该IP,供其它客户机使用
4. DHCP租约过程
4.1 定义
客户机从DHCP服岛器获得IP地址的过程称为DHCP的租约过程
4.2 图示
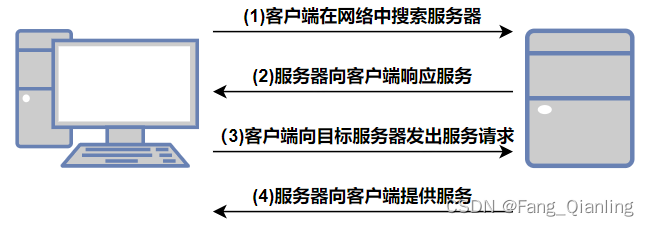
4.3 过程叙述
当客户机加入到网络中要得到IP地址:
① 客户端会发送一个广播报文discover,寻找DHCP服务器
② DHCP服务器收到discover报文,会回复一个offer报文,并且带有相关的配置信息,包含:网卡的IP地址、子网掩码;对应的网络地址、广播地址;默认网关地址;DNS服务器地址
③ 客户端收到offer报文后,会将报文中的配置信息配置好,再回复一个request报文,通知DHCP服务器,将使用的IP地址从合法地址池中去除
④ DHCP服务器收到request报文,会回复一个确认位ACK,通知客户机可以放行使用
5. 操作演示
基于接口配置设备自动获取配置信息:
5.1 图示

5.2 配置接口IP地址、选择接口模式、设置租期时限、DNS

5.3 查看网络信息
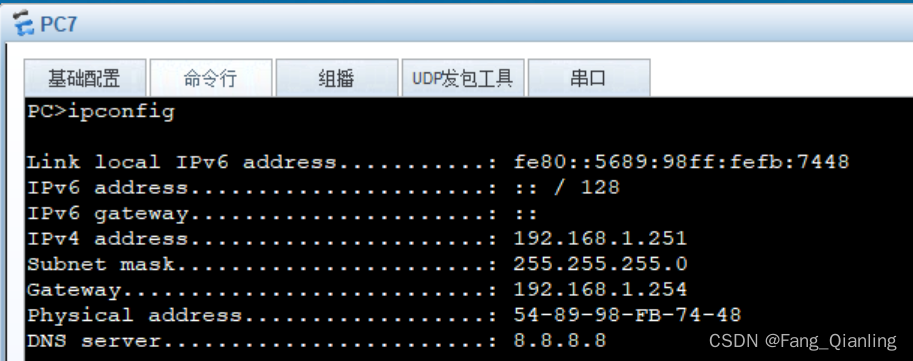
5.4 抓包验证 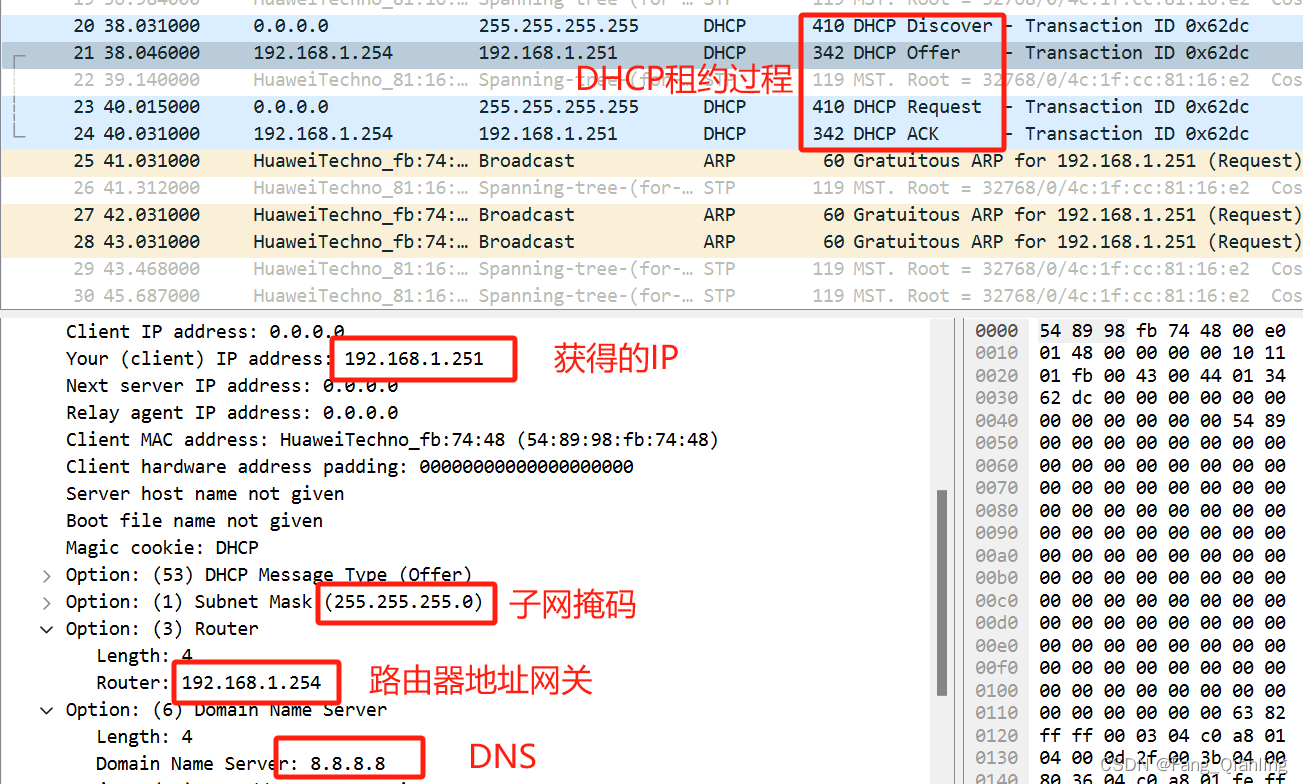
基于地址池的配置设备自动获取配置信息:
5.5 图示
5.6 创建IP地址池ky35,配置出口网关地址、网段子网掩码、租期、DNS
5.7 查看网络信息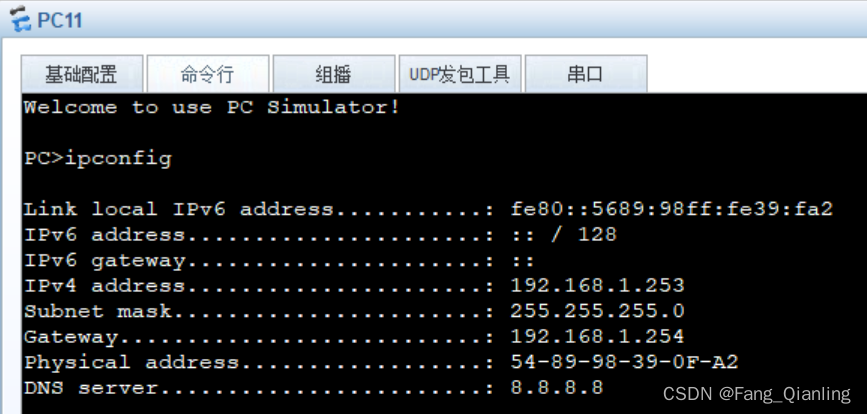
三、VRRP
1. 概述
VRRP能够在不改变组网的情况下,将多台路由器虚拟成一个虚拟路由器,通过配置虚拟路由器的IP地址为默认网关,实现网关的备份。协议版本常用VRRPv2,协议报文:心跳线。
2. 结构
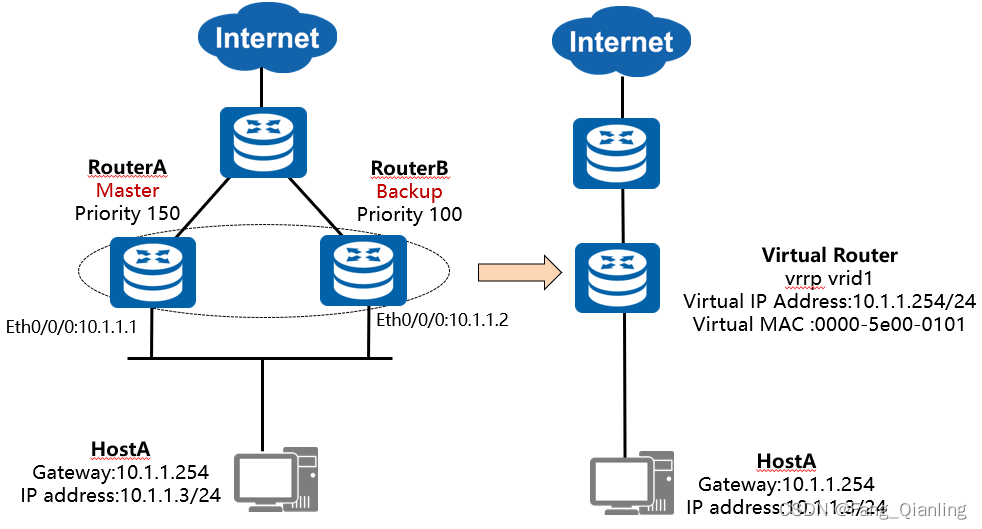
注:利用VRRP,一组路由器(同一个LAN中的接口)协同工作,但只有一个处于Master状态,处于该状态的路由器(的接口)承担实际的数据流量转发任务。在一个VRRP组内的多个路由器接口共用一个虚拟IP地址,该地址被作为局域网内所有主机的缺省网关地址。 VRRP决定哪个路由器是Master,Master路由器负责接收发送至用户网关的数据包并进行转发,以及响应PC对于其网关IP地址的ARP请求。 Backup路由器侦听Master路由器的状态,并在Master路由器发生故障时,接替其工作,从而保证业务流量的平滑切换。
2.1 状态机
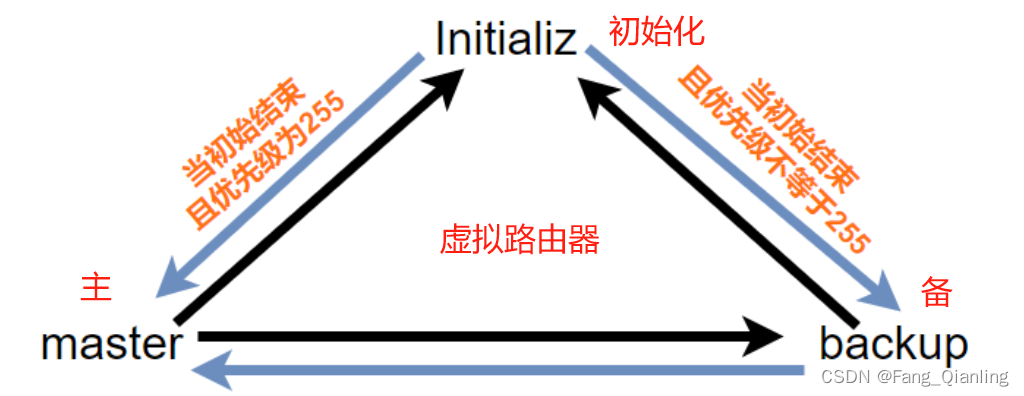
注:优先级都不是255,就先成为备,等待看看网络中是否有主发送报文,等待是3倍的hello时间
① 始终没有收到,变成主
② 收到比自己小也成为主
③ 收到比我大成为备
④ 收到优先级为0
3. VRRP主备路由器切换过程
· 如果Master发生故障,则主备切换:Backup在Master_Down_Interval时间内未收到Master发送的状态通告报文,则立即成为Master。
· 如果原Master故障恢复,则主备回切:发现收到RouterB的VRRP报文中的优先级比自己低,RouterA立即抢占成为Master。
4. VRRP路由器的抢占功能
VRRP设备的工作方式有如下两种:
· 抢占模式:在抢占模式下,如果Backup设备的优先级比当前Master设备的优先级高,则主动将自己切换成Master。
· 非抢占模式:在非抢占模式下,只要Master设备没有出现故障,Backup设备即使随后被配置了更高的优先级也不会成为Master设备。
因此,如果需要优先级高的VRRP设备能够主动成为Master,可以将此设备配置采用抢占方式。
5. VRRP路由器的优先级
VRRP根据优先级来确定虚拟路由器中每台设备的角色(Master设备或Backup设备)。优先级越高,则越有可能成为Master设备。
初始创建的VRRP设备工作在Initialize状态,收到接口Up的消息后,如果设备的优先级为255,则直接成为Master设备;如果设备的优先级小于255,则会先切换至Backup状态,待Master_Down_Interval定时器超时后再切换至Master状态。首先切换至Master状态的VRRP设备通过VRRP通告报文的交互获知虚拟设备中其他成员的优先级,进行Master的选举:
① 如果VRRP报文中Master设备的优先级高于或等于自己的优先级,则Backup设备保持Backup状态。
② 如果VRRP报文中Master设备的优先级低于自己的优先级,采用抢占方式的Backup设备将切换至Master状态,采用非抢占方式的Backup设备仍保持Backup状态。
③ 如果多个VRRP设备同时切换到Master状态,通过VRRP通告报文的交互进行协商后,优先级较低的VRRP设备将切换成Backup状态,优先级最高的VRRP设备成为最终的Master设备;优先级相同时,VRRP设备上VRRP备份组所在接口主IP地址较大的成为Master设备。
④ 如果创建的VRRP设备为IP地址拥有者,收到接口Up的消息后,将会直接切换至Master状态。
参考文献:VRRP的优先级和抢占功能 - S12700, S12700E V200R022C10 配置指南-可靠性 - 华为 (huawei.com)