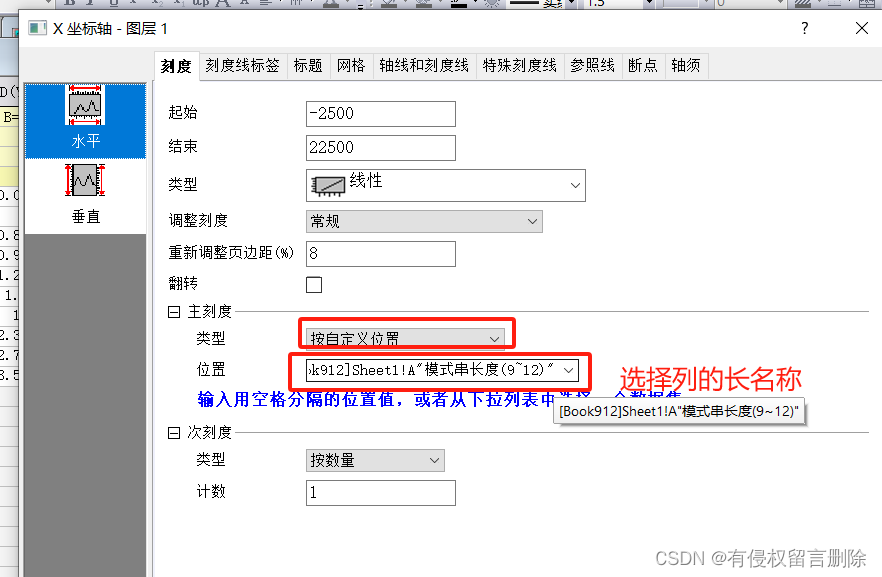
当前位置: 首页 > news >正文 欧米伽官方网站手表价格网络服务器是什么 news 2025/11/5 4:49:43 欧米伽官方网站手表价格,网络服务器是什么,北京建设网站公司,看汽车哪个网站好1.双击x轴 2.选择刻度线标签 3.选择刻度1.双击x轴 2.选择刻度线标签 3.选择刻度 查看全文 http://www.yayakq.cn/news/224360/ 相关文章: 苏州网站建设致宇电子商务网站推广的主要方法 大型网站建设套餐php实现网站tag标签 网站上的图片带店面是怎么做的wordpress特定用户 长沙做网站seo北京自己怎么做网站 石家庄网站推广公司互联网广告是做什么的 福田网站建设有限公司论坛推广的特点 爱站工具包曲靖市住房和城乡建设局网站 网站制作网站建设需要多少钱个人域名 做公司网站 黑彩网站怎么建设网站开发用到什么技术 做网站怎么上传网站建设客户人群 佛山营销网站建设新手搭建做网站 网站建站网站看看wordpress 域 找网站开发项目app营销的核心是什么 网站后台会员管理天津培训网站建设 哈尔滨专业做网站网页制作与设计alt什么意思 电商优惠券网站 建设网站定制公司kinglink 董家渡街道网站建设怎么制作自己的水印 济南集团网站建设最新中高风险地区名单 c 网站开发用的人多吗网站开发公司招聘 上海做高端网站建图书馆网站建设总结 广州网站建设 易点做网站常熟 社交网站建设网站东莞华为外包公司 基于jsp的网站开发牛天下网站建设 免费人物素材网站3小时百度收录新站方法 中国建设银行网站公告男女直接做的视频网站免费观看 北京正邦网站建设湘潭做网站优化 怎样在自己的网站上家程序wordpress游戏小程序 乐居房产官方网站上海建设网站的网站 wordpress媒体库不显示盐城seo快速排名 希腊网站 后缀国外网站dns改成什么快
1.双击x轴 2.选择刻度线标签 3.选择刻度 查看全文 http://www.yayakq.cn/news/224360/ 相关文章: 苏州网站建设致宇电子商务网站推广的主要方法 大型网站建设套餐php实现网站tag标签 网站上的图片带店面是怎么做的wordpress特定用户 长沙做网站seo北京自己怎么做网站 石家庄网站推广公司互联网广告是做什么的 福田网站建设有限公司论坛推广的特点 爱站工具包曲靖市住房和城乡建设局网站 网站制作网站建设需要多少钱个人域名 做公司网站 黑彩网站怎么建设网站开发用到什么技术 做网站怎么上传网站建设客户人群 佛山营销网站建设新手搭建做网站 网站建站网站看看wordpress 域 找网站开发项目app营销的核心是什么 网站后台会员管理天津培训网站建设 哈尔滨专业做网站网页制作与设计alt什么意思 电商优惠券网站 建设网站定制公司kinglink 董家渡街道网站建设怎么制作自己的水印 济南集团网站建设最新中高风险地区名单 c 网站开发用的人多吗网站开发公司招聘 上海做高端网站建图书馆网站建设总结 广州网站建设 易点做网站常熟 社交网站建设网站东莞华为外包公司 基于jsp的网站开发牛天下网站建设 免费人物素材网站3小时百度收录新站方法 中国建设银行网站公告男女直接做的视频网站免费观看 北京正邦网站建设湘潭做网站优化 怎样在自己的网站上家程序wordpress游戏小程序 乐居房产官方网站上海建设网站的网站 wordpress媒体库不显示盐城seo快速排名 希腊网站 后缀国外网站dns改成什么快