网站建设合同 包括什么国内网站速度慢
史上最全最详细的Instagram 欢迎消息引流及示例!
关键词: Instagram 欢迎消息SaleSmartly(ss客服)
寻找 Instagram 欢迎消息示例,您可以用于您的业务。在本文中,我们将介绍Instagram欢迎消息的基础知识和好处,提供要使用的消息示例和示例模板 Instagram,并指导您完成设置过程 Instagram 欢迎消息。
配图来源:SaleSmartly(ss客服)
一、什么是Instagram 欢迎消息?
Instagram是世界上最受欢迎的社交应用程序之一 ,难怪越来越多的企业使用它来与客户互动并转换潜在客户。企业可以使用的一种简单方法 Instagram 建立客户关系是通过发送欢迎消息。
Instagram 欢迎消息是当客户与您开始新对话时Instagram 直接发送给他们的自动消息 。
二、欢迎消息的好处
欢迎消息是创造积极客户体验的关键因素。它们可作为您品牌的介绍,并在客户与您一起探索旅程时为他们提供指导。
通过在欢迎信息中提供清晰、有用和个性化的信息,企业可以有效地吸引和协助客户,从而实现更令人满意和成功的互动。以下是一些具体的优势:
- l缩短响应时间:预定义的消息消除了每次客户发送消息时制作新消息的需要。这使企业能够及时一致地响应消息。
- l提高客户满意度:个性化的欢迎信息可以让客户感到受到重视和赞赏。这有助于创造积极的第一印象,从而提高客户满意度。
- l设定期望:通过清楚地传达客户何时可以期待回复来管理客户的期望,并包括号召性用语 (CTA) 以提示他们下一步要采取的步骤。
现在我们已经了解了所有关于 Instagram 欢迎消息,我们将分享一些现成的示例。
三、Instagram 欢迎消息示例
创建欢迎消息时,必须牢记有效消息传递的关键原则。以下准则将帮助您撰写一条消息,传达您的目的并与客户建立联系。
以下是一些建议的最佳做法:
·保持信息简短明了
·使用与您的品牌声音一致的友好和平易近人的语气
·个性化您的信息,让客户感到被看到和听到。如果可能,请包括他们的姓名和其他相关详细信息。
·添加 CTA 以指导客户并让他们知道下一步应该做什么
·确保及时监控和响应客户消息,以确保积极的客户体验
现在,让我们来看看可用于不同方案的各种类型的欢迎消息。
配图来源:SaleSmartly(ss客服)
Instagram 欢迎消息示例:特别优惠
企业可以利用这个机会在其产品和服务中推广其产品或服务 Instagram 欢迎消息。让我们看看下面的一些例子。
1.“你好!我们已收到您的消息,并将尽快回复您。我们想让您知道,我们为所有关注者提供款待。在结帐时使用代码[代码]可享受下次购买20%的折扣。
2.“感谢您与您联系,我们将在接下来的3小时内回复。此外,这是我们的3周年纪念日!我们要感谢您对签名系列10%折扣的支持。只需在[日期]之前在结账时使用折扣代码[代码]。
3.“嗨[姓名],谢谢你的光临!我们的团队将在一小时内
Instagram 欢迎消息示例:潜在客户捕获
您也可以使用 Instagram 私信收集客户信息。关注您的客户 Instagram 帐户已经对您的产品或服务感兴趣,并且更愿意通过其他渠道与您的公司联系。您可以参考这些示例。
1.“嗨,我们收到了您的消息,并将与您在一起。同时,如果您想成为第一个了解我们促销活动的人,请将您的电子邮件地址发送给我们,我们会将您添加到我们的电子邮件列表中。
2.“您好,欢迎来到[公司名称]。如果您想了解更多关于我们的服务,请留下您的电子邮件地址,代理商将发送我们的目录。感谢您的关注,并期待为您提供
3.“嘿,[姓名]!我们很高兴您对我们的照片打印服务
Instagram 欢迎消息示例:客户支持
一些企业使用 Instagram 提供客户支持。像下面这样的欢迎消息可以帮助访问者在寻求帮助时在响应时间或支持代理的可用性方面设定期望。
1.“您好,感谢您的留言!我们在这里帮助您解决您可能遇到的任何问题或问题。请向我们发送您的疑虑,我们的一位友好代理商会尽快回复您。
2.“有问题吗?
3.“嗨[姓名],谢谢你的伸出援手!我们会在一小时内回复您。对于一般查询,您还可以在[链接]查看我们的常见问题解答页面。
Instagram 问候 消息示例:季节性消息
在欢迎信息中加入季节性元素可以改善客户对您的业务的看法。一些企业可能会在某些节日期间提供特别折扣或商品,这是提及它们的理想场所。
1.“圣诞快乐!感谢您访问我们。对于延迟回复,我们深表歉意,因为我们目前正在忙于准备和运送圣诞节订单。请在等待我们的回复时查看我们的页面以获取特别优惠。
2.“情人节
3.“谢谢你伸出援手!我们会尽快回复您。随着母亲节的到来,我们有一个精心策划的珠宝系列,可以作为宠坏妈的完美礼物。别忘了看看。
四、如何设置 Instagram 欢迎消息
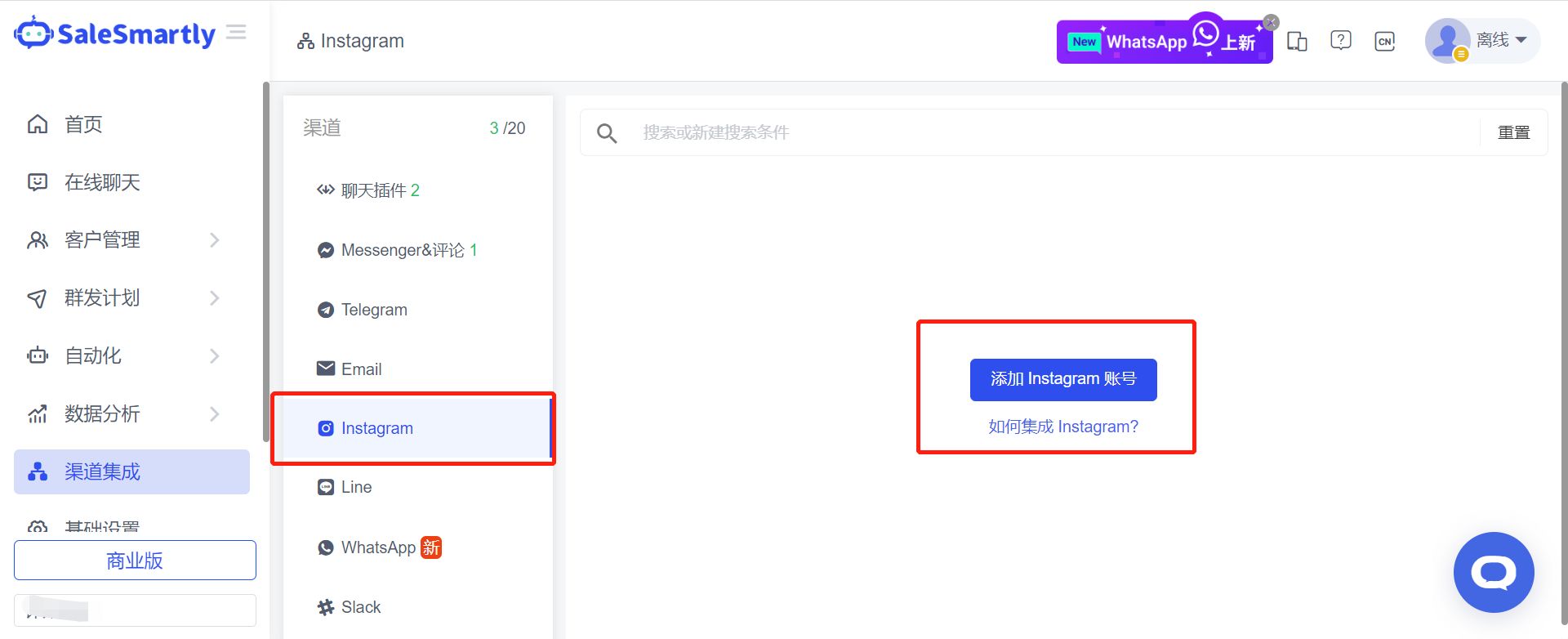
这里我们将引导您完成发送 Instagram 欢迎消息通过应用内收件箱开启 Instagram,完成之后,您就可以通过集成Instagram连接到客户对话管理软件,例如SaleSmartly(ss客服)。绑定Instagram账号到SaleSmartly(ss客服)上,若发送了欢迎消息有客户回复,就可以在SaleSmartly(ss客服)后台进行统一回复。
配图来源:SaleSmartly(ss客服)后台
如何设置欢迎消息 Instagram 消息应用收件箱
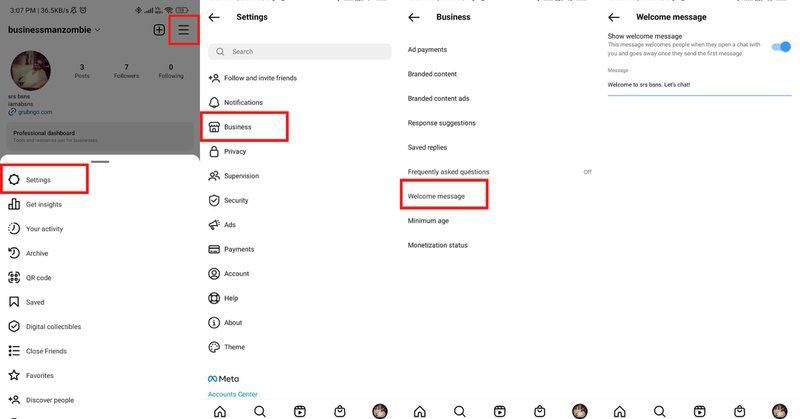
创建欢迎消息通过您的 Instagram 应用程序收件箱只需几个步骤即可完成。
如何设置Instagram欢迎消息
要通过您的 Instagram 应用收件箱,请按照以下说明操作:
1. 点击 位于右上角的三条水平线 Instagram 个人资料页面。
2. 单击“设置”,然后单击“业务”,最后单击“欢迎消息”。
3. 打开 切换开关以 显示欢迎消息。
4. 在文本字段中 输入 所需的消息,然后单击 保存。您的欢迎消息将在客户下次开始对话时发送。
请注意,设置欢迎消息的功能 Instagram 仅在 Instagram 安卓手机的应用程序。此功能不适用于 iPhone 用户。如果您是iPhone用户,则可以在下一节中找到替代方法。