建站之星好不建立本地网站
首先先到此处下载VitrualBox选择对应的配置
Oracle VM VirtualBox


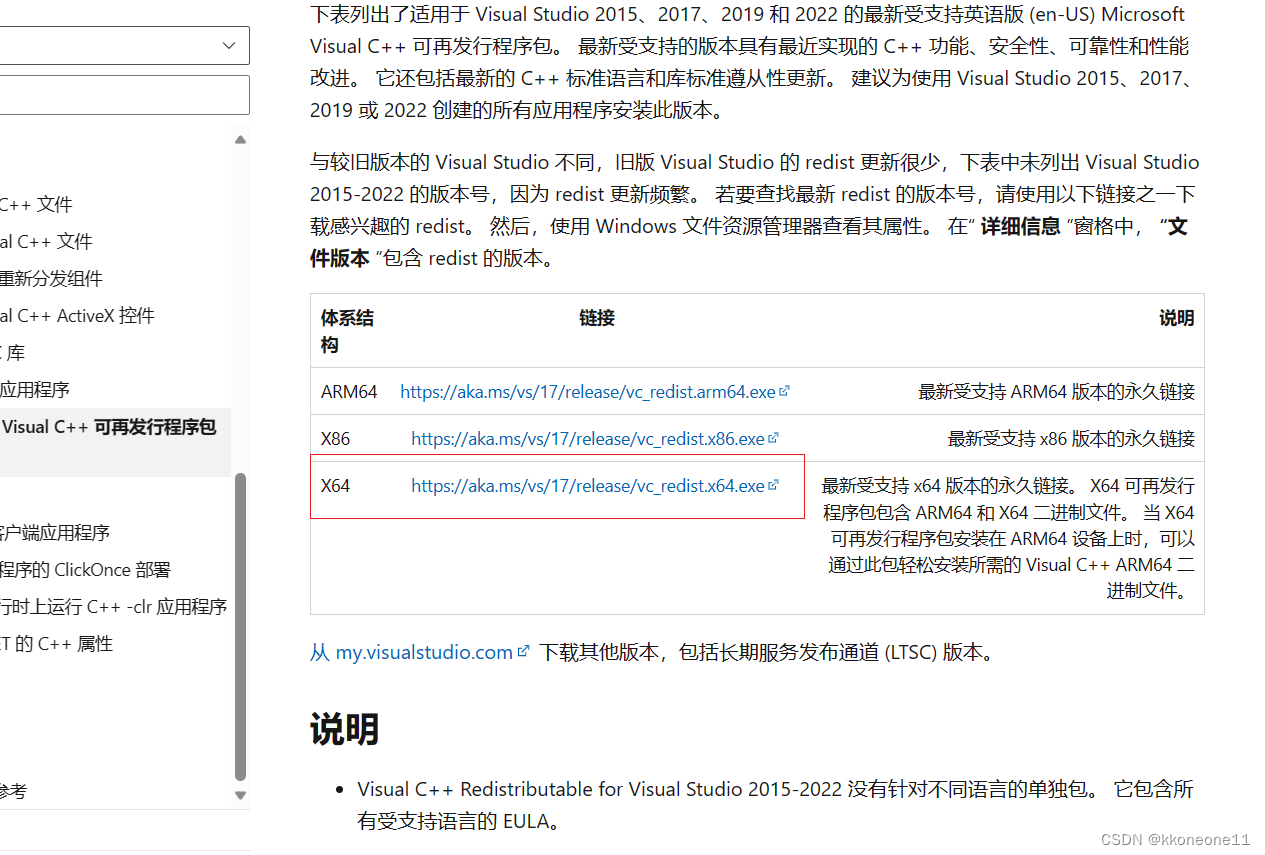
下载VitrualBox的同时要下载一个Visual,支持VitrualBox运行
最新受支持的 Visual C++ 可再发行程序包下载 | Microsoft Learn
同时再根据下面的网址去下载Ubantu

下载好后桌面出现这两个,然后先安装下面那个

点安装即可

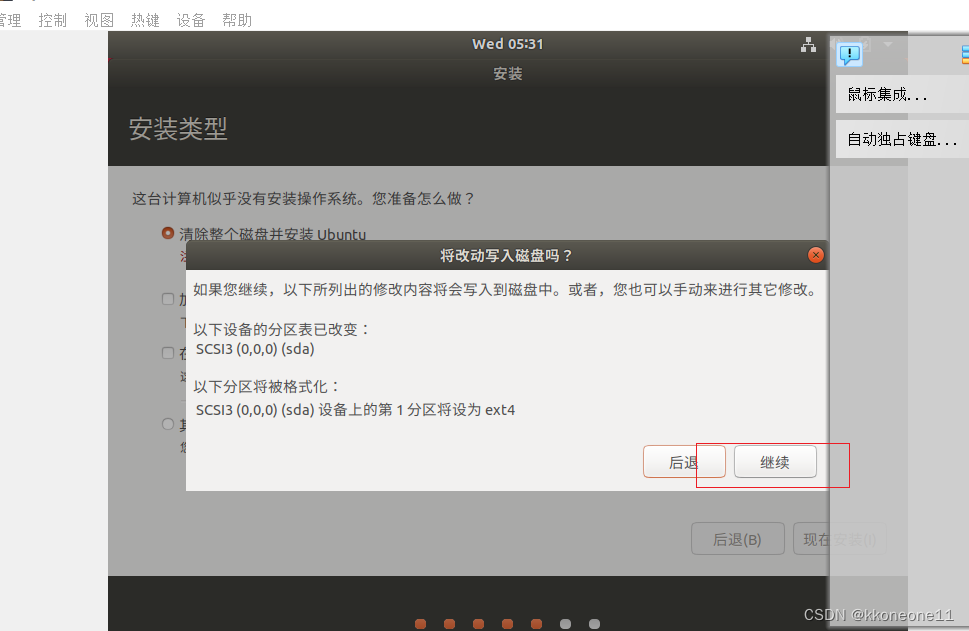
改个地址后一路确定即可,也可以不改

点击新建,然后找到刚刚ubantu的下载位置
 这里的文件夹要选择其他盘比较大的地方,当然你愿意C盘也无所谓,然后按照以下照片的进行配置就可以进行下一步
这里的文件夹要选择其他盘比较大的地方,当然你愿意C盘也无所谓,然后按照以下照片的进行配置就可以进行下一步

 最后点完成即可
最后点完成即可




启动虚拟机

接下来按照图片流程走即可





找到终端

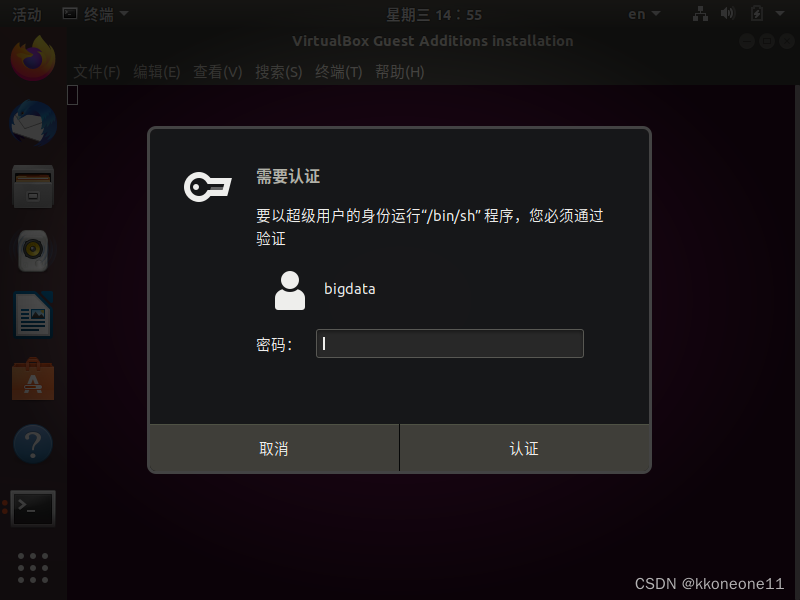
安装一下增强功能,否则后面用不了

输入密码安装即可
以下是接着的
设置hadoop+安装java环境-CSDN博客