高端画册定制印刷公司北京seo排名厂家
基数排序
基数排序,给关键字分成d位(组),,对每一位的情况,可能会出现的值位r(基数)个,然后分成r个队列,对每个对林进行分配耗时O(n),最后按照改位(组)情况,进行收集耗时O(r)
所以基数排序的
时间复杂度:O(d*(r+n))。
空间复杂度:O(r),创建r个队列。-口令:饿(额外空间)鬼(归并排序),炸鸡(基数排序)块
稳定性:稳定,一直按照关键字,有序排列的,相同关键字入队,相对位置不会变
适用情况:
1.每组关键字方便拆成d位(组),且d比较小。
2.每组关键字取值不大,r较小。
3.元素个数较大时,d比较大。
2.思路:
有点乱,简单来说,以整数为例子,有一个线性表,每个结点存储的数据都为三位数(关键字)。
- 三位数按照位数分为:个位、十位、百位(d=3),
- 先进行个位的情况,个位可能出现的数字为0-9,十个数字,因此r=10.
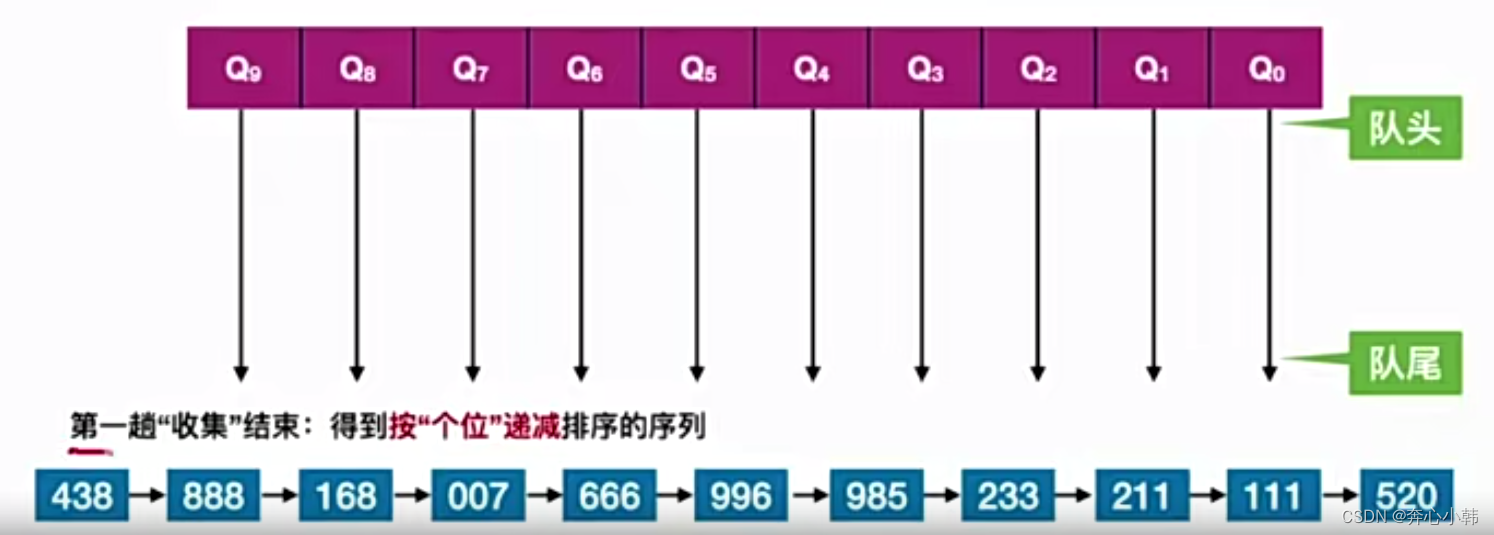
- 准备10个队列,每一个队列存储一个数字出现的可能性。按照个位,进行入队。这为分配
- 如果要求递减序列,则给个位按照递减,依次给队列从大队列到小队列,链接起来,最后收集成一个新的线性表,这叫收集
- 随后再根据十位的情况,重复类似的操作,最后进行完即可,
- 如图:
分配:

收集: