如何建设论坛网站网站建设销售工作怎么样
大家都知道CAJ文件吗?这是中国学术期刊数据库中的文件,这种文件类型比较特殊。如果想要提取其中的内容使用,该如何操作呢?大家可以试试下面这种免费的caj转word的方法,多个文档也可以一起批量转换。
准备材料:CAJ文档、电脑
转换工具:speedpdf在线转换工具
步骤:
1,首先点开百度搜索界面,搜索关键词speedpdf在线转换工具找到转换页面。
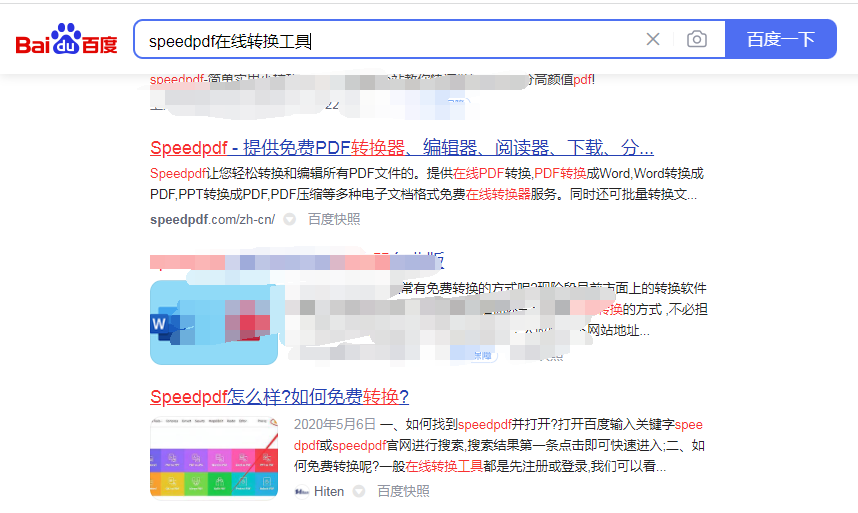
2,然后在首页点击文档转换中的CAJ转word选项,然后点击页面中的“选择文件”添加CAJ文件。可以一次性添加多个CAJ文件。这样就可以实现CAJ文件批量转换成word文件了。
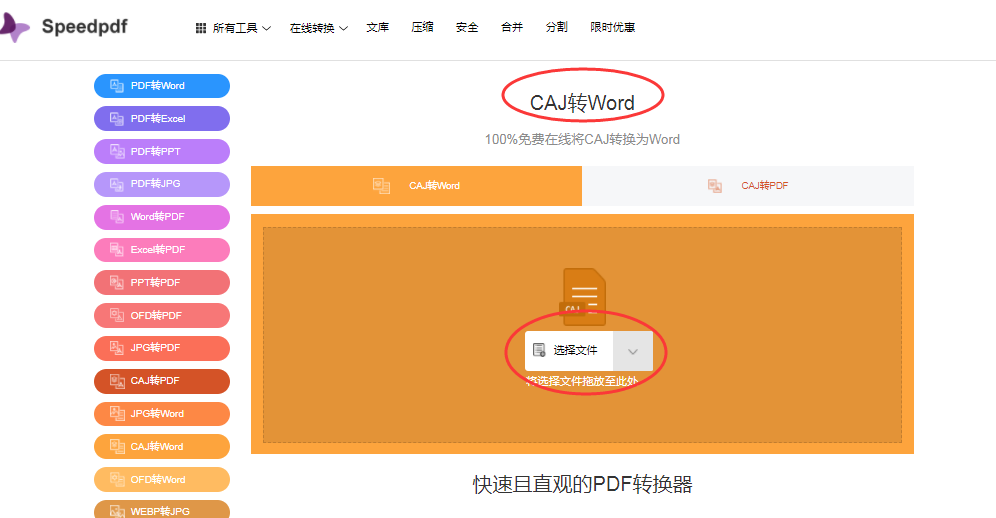
3,我们将需要转换的CAJ文件添加完成之后,接着点击右侧“转换”两个字就可以了。
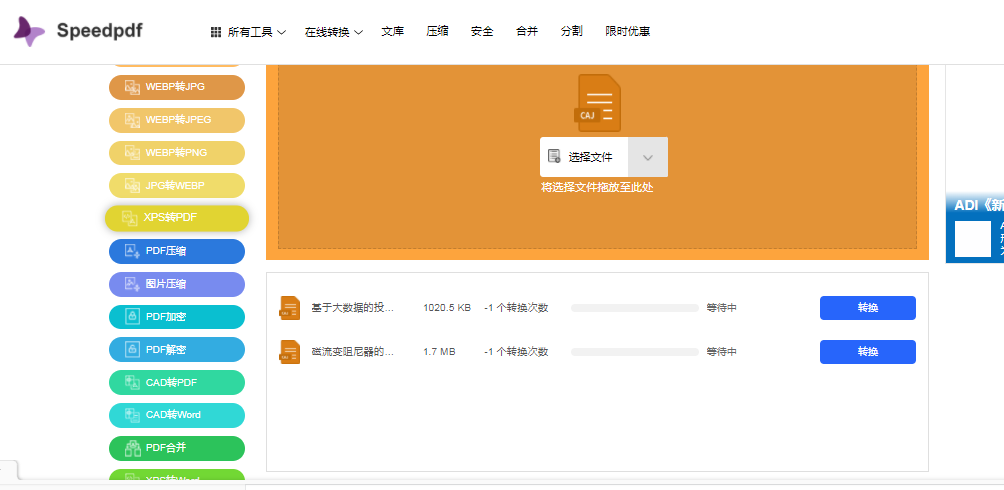
4,接下来CAJ文件会直接批量转换,当进度条显示完,出现成功2个字,说明CAJ文件已经转换成word文件了,点击下载按钮使用即可。
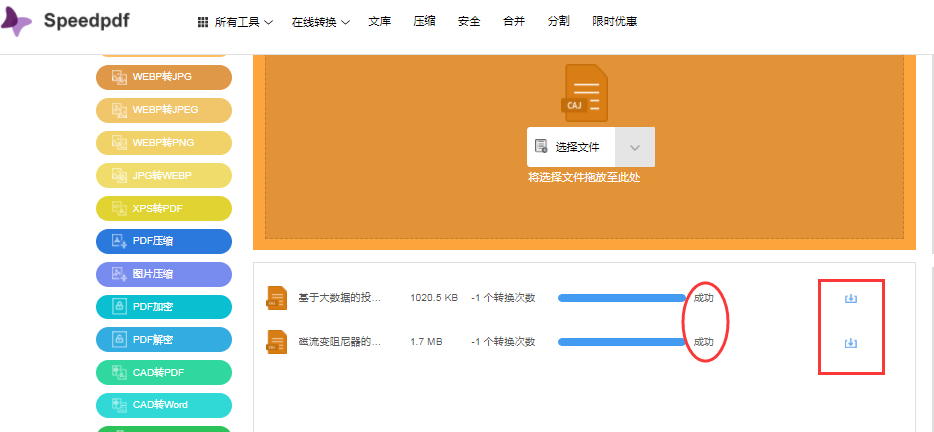
以上就是CAJ免费批量转word的转换方法,这种转换方法真的是很简单了,相信大家根据步骤转换文件一定没有问题,一起学习分享下吧。