莲都区建设分局网站北京网站设计与制作
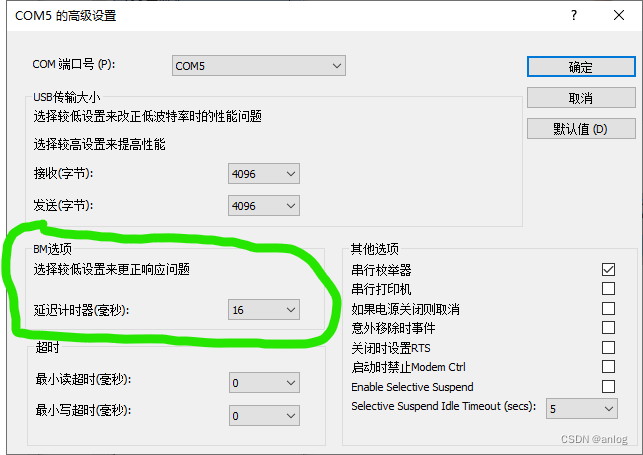

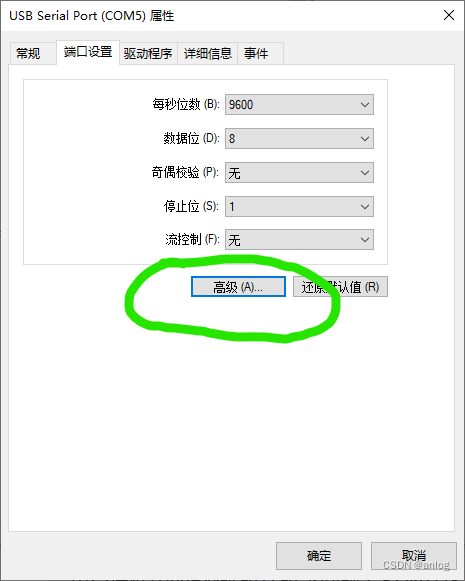
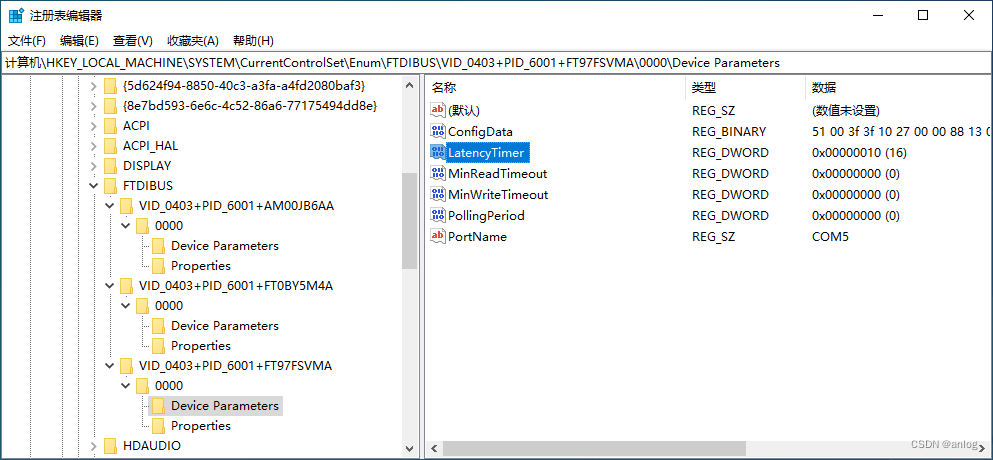
如果使用程序修改则需要修改注册表对应位置如下
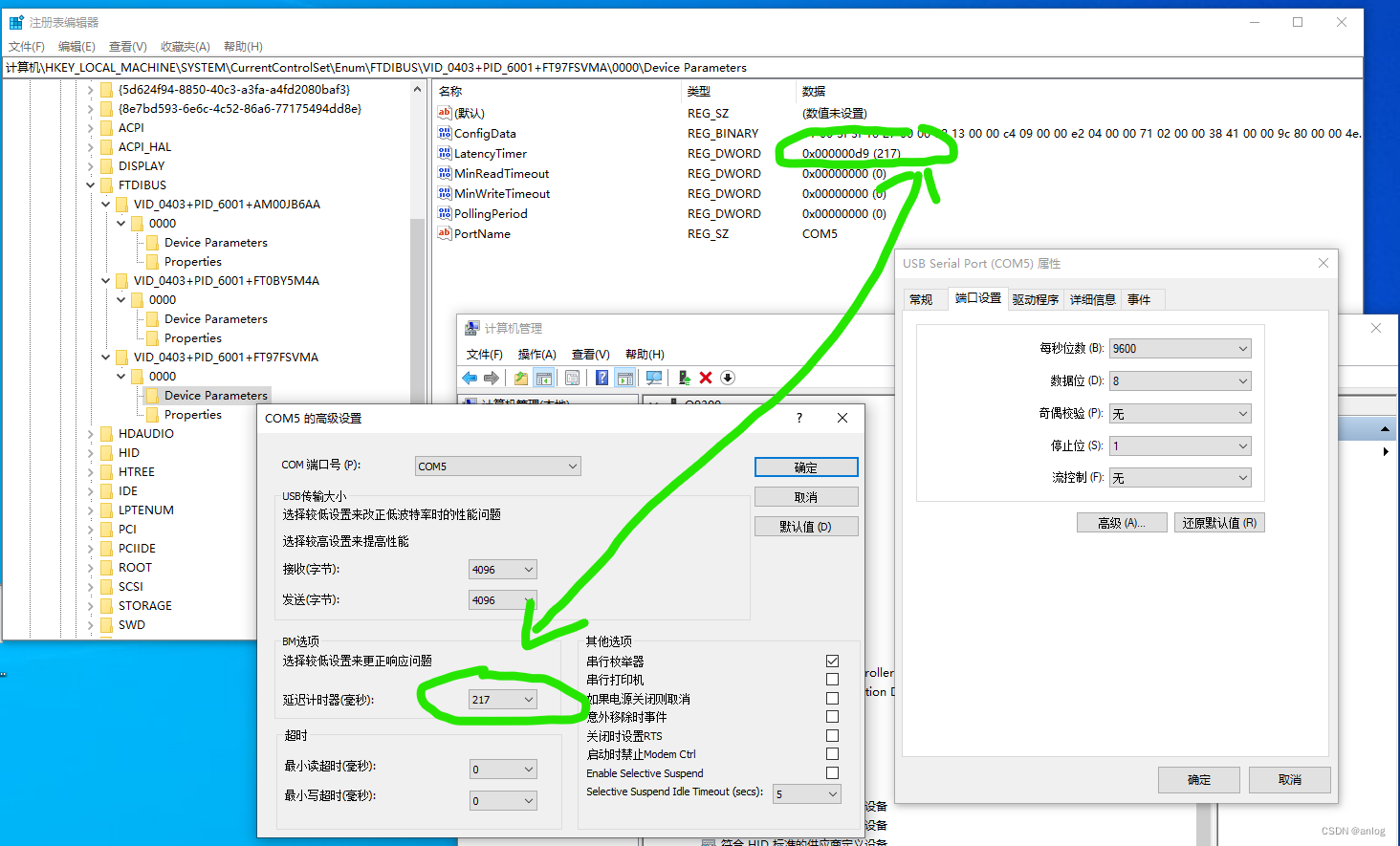
第一个示例(217)
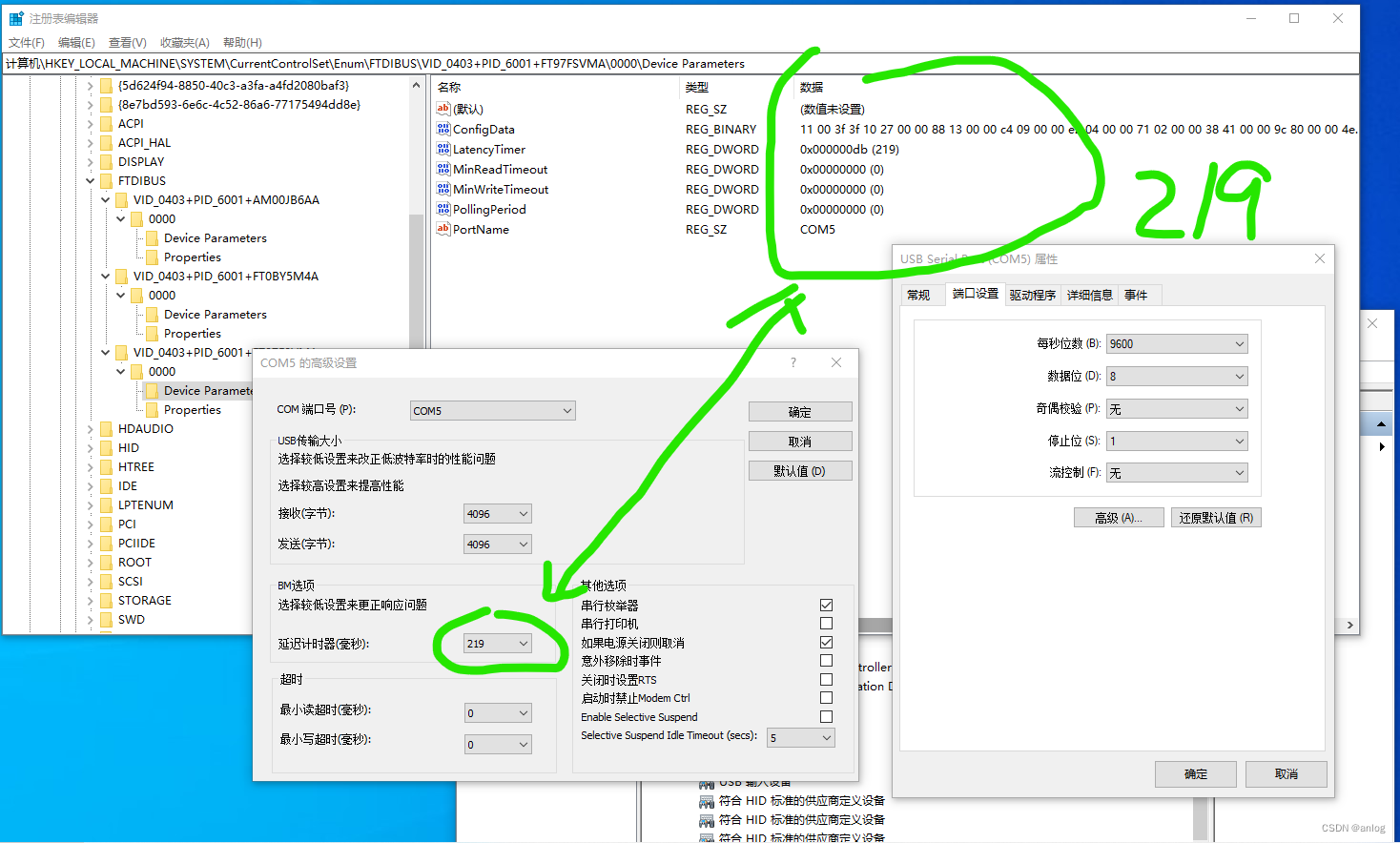
第二个示例(219)
需要注意的事情是修改前必须点查看串口名称(例如上图是com5)
程序修改:
有没有办法以编程方式更改USB < – >串行适配器的“BM选项延迟定时器”?
使用一个FTDI USB串行转换器。 然后你可以使用libftdi
并查阅应用笔记 (特别是AN232B-04),因为它们包含大量有用的信息。
如果您更喜欢使用FTDI自己的驱动程序和Windows的标准COM端口API,并且您需要配置此值,您仍然可以通过编辑注册表来永久并以编程方式更改它。
如果转到此路由,则需要更改HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\FTDIBUS\VID_0403+PID_6001+KBxxxxxxx\0000\Device Parameters下的DWORD值LatencyTimer 。 这个例子中的KBxxxxxxx需要用你设备的序列号来代替。 您需要更高的权限才能更改此值,例如通过提高UAC提示。 设备驱动程序可能需要在此时重新启动,才能使更改生效,例如通过拔下和重新插入设备。
本次测试电路实际路径
参考连接
如何设置调高COM端口速度_串口bm选项-CSDN博客![]() https://blog.csdn.net/dehuadeng/article/details/5532636#:~:text=%E8%AE%BE%E7%BD%AECOM%E7%AB%AF%E5%8F%A3%E9%80%9F,%E2%80%9D%EF%BC%8C%E9%80%89%E5%8F%96%E2%80%9C1%E2%80%9D%E3%80%82串口属性中的BM延时计时器问题-CSDN社区
https://blog.csdn.net/dehuadeng/article/details/5532636#:~:text=%E8%AE%BE%E7%BD%AECOM%E7%AB%AF%E5%8F%A3%E9%80%9F,%E2%80%9D%EF%BC%8C%E9%80%89%E5%8F%96%E2%80%9C1%E2%80%9D%E3%80%82串口属性中的BM延时计时器问题-CSDN社区![]() https://bbs.csdn.net/topics/390526127
https://bbs.csdn.net/topics/390526127
关于串口调试线延时问题的解决方法_串口接收数据为什么有延迟-CSDN博客![]() https://blog.csdn.net/Ijerome/article/details/127841939?spm=1035.2023.3001.6557&utm_medium=distribute.pc_relevant_bbs_down_v2.none-task-blog-2~default~OPENSEARCH~Rate-1-127841939-bbs-390526127.264%5Ev3%5Epc_relevant_bbs_down_v2_default&depth_1-utm_source=distribute.pc_relevant_bbs_down_v2.none-task-blog-2~default~OPENSEARCH~Rate-1-127841939-bbs-390526127.264%5Ev3%5Epc_relevant_bbs_down_v2_default 如何提升串口响应速度_串口助手传输速度慢怎么办-CSDN博客
https://blog.csdn.net/Ijerome/article/details/127841939?spm=1035.2023.3001.6557&utm_medium=distribute.pc_relevant_bbs_down_v2.none-task-blog-2~default~OPENSEARCH~Rate-1-127841939-bbs-390526127.264%5Ev3%5Epc_relevant_bbs_down_v2_default&depth_1-utm_source=distribute.pc_relevant_bbs_down_v2.none-task-blog-2~default~OPENSEARCH~Rate-1-127841939-bbs-390526127.264%5Ev3%5Epc_relevant_bbs_down_v2_default 如何提升串口响应速度_串口助手传输速度慢怎么办-CSDN博客![]() https://blog.csdn.net/weixin_43729257/article/details/108119146?spm=1001.2014.3001.5506
https://blog.csdn.net/weixin_43729257/article/details/108119146?spm=1001.2014.3001.5506
是否有可能以编程方式更改USB < – >串行转换器的“BM”延迟选项? 中国服务器网 (zgserver.com)![]() https://zgserver.com/usb-bmx9009.html
https://zgserver.com/usb-bmx9009.html
特此记录
anlog
2024年5月11日