北京做网站哪家好免费域名注册万网
今天带大家简单认识一下Linux,它和我们日常用的Windows有什么不同呢?
Linux介绍
Linux内核&发行版
Linux内核版本
内核(kernel)是系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,它提供了一个在裸设备与应用程序间的抽象层。
Linux内核版本又分为稳定版和开发版,两种版本是相互关联,相互循环:
- 稳定版:具有工业级强度,可以广泛地应用和部署。新的稳定版相对于较旧的只是修正一些bug或加入一些新的驱动程序。
- 开发版:由于要试验各种解决方案,所以变化很快。
内核源码网址:http://www.kernel.org 所有来自全世界的对Linux源码的修改最终都会汇总到这个网站,由Linus领导的开源社区对其进行甄别和修改最终决定是否进入到Linux主线内核源码中。
Linux发行版本
Linux发行版 (也被叫做 GNU/Linux 发行版) 通常包含了包括桌面环境、办公套件、媒体播放器、数据库等应用软件。
目前市面上较知名的发行版有:Ubuntu、RedHat、CentOS、Debian、Fedora、SuSE、OpenSUSE、Arch Linux、SolusOS 等。
linux和windows区别
- Linux是一种开源操作系统,可以根据需要更改源代码,而Windows操作系统没有访问源代码的权限,因为它是商业操作系统。
- 由于其出色的安全性,Linux可以更轻松地检测并修复错误,而Windows的大量用户群易受到黑客攻击。
- Windows运行缓慢,特别是在旧硬件上运行,而Linux运行速度显著更快。
- 在Windows操作系统中,打印机、CD-ROM和硬盘被视为设备。Linux外围设备,包括打印机、CD-ROM和硬盘被视为文件。
- Windows使用数据驱动器(C:D:E:)和文件夹来存储文件。Linux使用以根目录为开头的树形结构来组织文件。
- 在Linux中,同一目录中可以有两个名称相同的文件。在Windows中,用户不能在同一文件夹中使用完全相同的名称拥有两个文件。
- 在Microsoft Windows中,程序和系统文件几乎总是存储在C:驱动器中,而Linux上的程序和系统文件可以在不同的目录中找到。
Linux目录结构
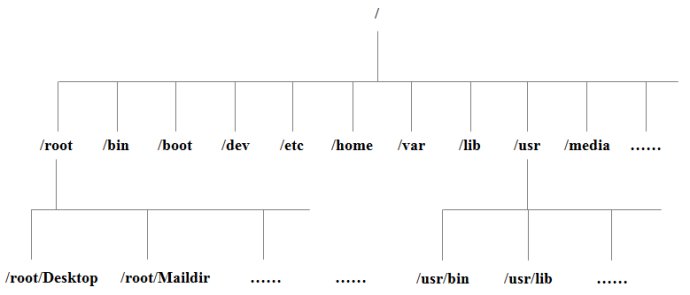
- /:根目录,一般根目录下只存放目录,在Linux下有且只有一个根目录。所有的东西都是从这里开始。当你在终端里输入“/home”,你其实是在告诉电脑,先从/(根目录)开始,再进入到home目录。
- /bin: /usr/bin: 可执行二进制文件的目录,如常用的命令ls、tar、mv、cat等。
- /boot:放置linux系统启动时用到的一些文件,如Linux的内核文件:/boot/vmlinuz,系统引导管理器:/boot/grub。
- /dev:存放linux系统下的设备文件,访问该目录下某个文件,相当于访问某个设备,常用的是挂载光驱 mount /dev/cdrom /mnt。
- /etc:系统配置文件存放的目录,不建议在此目录下存放可执行文件,重要的配置文件有 /etc/inittab、/etc/fstab、/etc/init.d、/etc/X11、/etc/sysconfig、/etc/xinetd.d。
- /home:系统默认的用户家目录,新增用户账号时,用户的家目录都存放在此目录下,表示当前用户的家目录,edu 表示用户 edu 的家目录。
- /lib: /usr/lib: /usr/local/lib:系统使用的函数库的目录,程序在执行过程中,需要调用一些额外的参数时需要函数库的协助。
- /lost+fount:系统异常产生错误时,会将一些遗失的片段放置于此目录下。
- /mnt: /media:光盘默认挂载点,通常光盘挂载于 /mnt/cdrom 下,也不一定,可以选择任意位置进行挂载。
- /opt:给主机额外安装软件所摆放的目录。
- /proc:此目录的数据都在内存中,如系统核心,外部设备,网络状态,由于数据都存放于内存中,所以不占用磁盘空间,比较重要的目录有 /proc/cpuinfo、/proc/interrupts、/proc/dma、/proc/ioports、/proc/net/* 等。
- /root:系统管理员root的家目录。
- /sbin: /usr/sbin: /usr/local/sbin:放置系统管理员使用的可执行命令,如fdisk、shutdown、mount 等。与 /bin 不同的是,这几个目录是给系统管理员 root使用的命令,一般用户只能"查看"而不能设置和使用。
- /tmp:一般用户或正在执行的程序临时存放文件的目录,任何人都可以访问,重要数据不可放置在此目录下。
- /srv:服务启动之后需要访问的数据目录,如 www 服务需要访问的网页数据存放在 /srv/www 内。
- /usr:应用程序存放目录,/usr/bin 存放应用程序,/usr/share 存放共享数据,/usr/lib 存放不能直接运行的,却是许多程序运行所必需的一些函数库文件。/usr/local: 存放软件升级包。/usr/share/doc: 系统说明文件存放目录。/usr/share/man: 程序说明文件存放目录。
- /var:放置系统执行过程中经常变化的文件,如随时更改的日志文件 /var/log,/var/log/message:所有的登录文件存放目录,/var/spool/mail:邮件存放的目录,/var/run:程序或服务启动后,其PID存放在该目录下。
Linux终端命令
终端命令格式
command [-options] [parameter]
说明:
- command :命令名,相应功能的英文单词或单词的缩写
- [-options] :选项,可用来对命令进行控制,也可以省略
- parameter :传给命令的参数,可以是 零个、一个 或者 多个
学习Linux终端命令的原因
- Linux 刚面世时并没有图形界面,所有的操作全靠命令完成,如磁盘操作、文件存取、目录操作、进程管理、文件权限 设定等
- 在职场中,大量的 服务器维护工作 都是在 远程 通过 SSH 客户端 来完成的,并没有图形界面,所有的维护工作都需要通过命令来完成
- 在职场中,作为后端程序员,必须要或多或少的掌握一些 Linux 常用的终端命令
- Linux 发行版本的命令大概有 200 多个,但是常用的命令只有 10 多个而已
Shell
●Linux系统中运行的一种特殊程序
●在用户和内核之间充当“翻译官”
●用户登录Linux系统时,自动加载一个Shell程序
●Bash是Linux系统中默认使用的Shell程序,Bash文件位于 /bin/bash

常用Linux命令的基本使用
| 序号 | 命令 | 对应英文 | 作用 |
|---|---|---|---|
| 01 | ls | list | 查看当前文件夹下的内容 |
| 02 | pwd | print work directory | 查看当前所在文件夹 |
| 03 | cd[目录名] | changge directory | 切换文件夹 |
| 04 | touch[文件名] | touch | 如果文件不存在,新建文件 |
| 05 | mkdir[目录名] | make directory | 创建目录 |
| 06 | rm[文件名] | remove | 删除指定文件 |
| 07 | clear | clear | 清屏 |
小技巧:
ctrl + shift + =放大终端窗口的字体显示ctrl + -缩小终端窗口的字体显示
自动补全
在敲出 文件 / 目录 / 命令 的前几个字母之后,按下 tab 键
- 如果输入的没有歧义,系统会自动补全
- 如果还存在其他
文件/目录/命令,再按一下 tab 键,系统会提示可能存在的命令
小技巧 - 按
上/下光标键可以在曾经使用过的命令之间来回切换 - 如果想要退出选择,并且不想执行当前选中的命令,可以按
ctrl + c
具体命令的使用
ls 常用选项
| 参数 | 含义 |
|---|---|
| -a | 显示指定目录下所有子目录与文件,包括隐藏文件 |
| -l | 以列表方式显示文件的详细信息 |
| -h | 配合 -l 以人性化的方式显示文件大小 |
ls通配符的使用
| 通配符 | 含义 |
|---|---|
| * | 代表任意个数个字符 |
| ? | 代表任意一个字符,至少 1 个 |
| [] | 表示可以匹配字符组中的任一一个 |
| [abc] | 匹配 a、b、c 中的任意一个 |
| [a-f] | 匹配从 a 到 f 范围内的的任意一个字符 |
注意:以 . 开头的文件为隐藏文件,需要用 -a 参数才能显示
切换目录
cd
cd 是英文单词 change directory 的简写,其功能为更改当前的工作目录,也是用户最常用的命令之一
注意:Linux 所有的 目录 和 文件名 都是大小写敏感的
| 命令 | 含义 |
|---|---|
| cd | 切换到当前用户的主目录(/home/用户目录) |
| cd ~ | 切换到当前用户的主目录(/home/用户目录) |
| cd . | 保持在当前目录不变 |
| cd - | 可以在最近两次工作目录之间来回切换 |
| cd . . | 切换到上级目录 |
相对路径和绝对路径
相对路径 在输入路径时,最前面不是 / 或者 ~,表示相对 当前目录 所在的目录位置
绝对路径 在输入路径时,最前面是 / 或者 ~,表示从 根目录/家目录 开始的具体目录位置
创建和删除操作
touch
- 创建文件或修改文件时间
如果文件 不存在,可以创建一个空白文件
如果文件 已经存在,可以修改文件的末次修改日期
mkdir
- 创建一个新的目录
| 选项 | 含义 |
|---|---|
| -p | 可以递归创建目录 |
新建目录的名称 不能与当前目录中 已有的目录或文件 同名
rm
- 删除文件或目录
使用 rm 命令要小心,因为文件删除后不能恢复
| 选项 | 含义 |
|---|---|
| -f | 强制删除,忽略不存在的文件,无需提示 |
| -r | 递归地删除目录下的内容,删除文件夹 时必须加此参数 |
查看文件内容
| 序 号 | 命令 | 对应英文 | 作用 |
|---|---|---|---|
| 01 | cat 文件名 | concatenate | 查看文件内容、创建文件、文件合并、追加文件内容等功能 |
| 02 | more 文件名 | more | 分屏显示文件内容 |
| 03 | grep 搜索文本 文件名 | grep | 搜索文本文件内容 |
cat
cat 命令可以用来 查看文件内容、创建文件、文件合并、追加文件内容 等功能
cat 会一次显示所有的内容,适合 查看内容较少 的文本文件
| 选项 | 含义 |
|---|---|
| -b | 对非空输出行编号 |
| -n | 对输出的所有行编号 |
Linux 中还有一个 nl 的命令和 cat -b 的效果等价
more
- more 命令可以用于分屏显示文件内容,每次只显示一页内容
- 适合于 查看内容较多的文本文件
使用 more 的操作键:
| 操作键 | 功能 |
|---|---|
| 空格键 | 显示手册页的下一屏 |
| Enter | 键 一次滚动手册页的一行 |
| b | 回滚一屏 |
| f | 前滚一屏 |
| q | 退出 |
| /word | 搜索 word 字符串 |
grep
Linux 系统中 grep 命令是一种强大的文本搜索工具
grep 允许对文本文件进行 模式查找,所谓模式查找,又被称为正则表达式。
| 选项 | 含义 |
|---|---|
| -n | 显示匹配行及行号 |
| -v | 显示不包含匹配文本的所有行(相当于求反) |
| -i | 忽略大小写 |
常用的两种模式查找
| 参数 | 含义 |
|---|---|
| ^a | 行首,搜寻以 a 开头的行 |
| ke$ | 行尾,搜寻以 ke 结束的行 |
拷贝和移动文件
| 序号 | 命令 | 对应英文 | 作用 |
|---|---|---|---|
| 01 | tree [目录名] | tree | 以树状图列出文件目录结构 |
| 02 | cp 源文件目标文件 | copy | 复制文件或者目录 |
| 03 | mv 源文件 目标文件 | move | 移动文件或者目录/文件或者目录重命名 |
tree
- tree 命令可以以树状图列出文件目录结构
| 选项 | 含义 |
|---|---|
| -d | 只显示目录 |
cp
- cp 命令的功能是将给出的 文件 或 目录 复制到另一个 文件 或 目录 中,相当DOS 下的 copy命令
| 选 项 | 含义 |
|---|---|
| -i | 覆盖文件前提示 |
| -r | 若给出的源文件是目录文件,则 cp 将递归复制该目录下的所有子目录和文件,目标文件必 |
须为一个目录名
mv
- mv 命令可以用来 移动 文件 或 目录,也可以给 文件或目录重命名
| 选项 | 含义 |
|---|---|
| -i | 覆盖文件前提示 |
查找文件
find 命令功能非常强大,通常用来在 特定的目录下 搜索 符合条件的文件
| 序号 | 命令 | 作用 |
|---|---|---|
| 01 | find [路径] -name “*.py” | 查找指定路径下扩展名是 .py 的文件,包括子目录 |
- 如果省略路径,表示在当前文件夹下查找
- 之前学习的通配符,在使用 find 命令时同时可用
通配符
表示一个任意字符——?
表示0个或多个任意字符——*
演练目标
- 1.搜索桌面目录下,文件名包含 1 的文件
find -name "*1*"
1
- 2.搜索桌面目录下,所有以 .txt 为扩展名的文件
find -name "*.txt"
1
- 3.搜索桌面目录下,以数字 1 开头的文件
find -name "1*"
1
软链接
| 序 号 | 命令 | 作用 |
|---|---|---|
| 1 | ln -s 被链接的源文件 链接文件 | 建立文件的软链接,用通俗的方式讲类似于 Windows 下的快捷方式 |
注意:
- 没有
-s选项建立的是一个 硬链接文件两个文件占用相同大小的硬盘空间,工作中几乎不会建立文件的硬链接 - 源文件要使用绝对路径,不能使用相对路径,这样可以方便移动链接文件后,仍然能够正常使用
未完待续……