网站设计师职责策划公司活动方案

公网远程访问本地硬盘文件【内网穿透】
文章目录
- 公网远程访问本地硬盘文件【内网穿透】
- 前言
- 1. 下载cpolar和Everything软件
- 1.1 Everything 的介绍
- 1.2 cpolar 的介绍
- 1.3 下载软件搭建环境
- 1.4 操作步骤
- 2. 设定http服务器端口
- 2.1 Everything软件的http设置
- 3. 进入cpolar的设置
- 3.1 cpolar的设置
- 3.2 空白数据隧道设置
- 4. 生成公网连到本地内网穿透数据隧道
- 4.1 配置具体数据
- 4.2 登录验证
- 总结
- 📝结尾
前言
随着云概念的流行,不少企业采用云存储技术来保存办公文件,同时,很多个人用户也感受到云存储带来的便利,让云存储概念一时间风头无两。由于资料数据的敏感性、频繁爆发的云存储资料外泄事件和昂贵的云空间租用费用,令很多企业放弃了公共云存储方式。但资料数据进行云存储的好处又难以割舍,使得私有云模式逐渐火热起来,以群晖NAS为代表的小型云存储设备价格一路水涨船高,就是最好的证明。实际上,想要进行中等规模的资料云存储,不一定非要购买昂贵的套件设备,仅凭几个简单的软件,也能将我们的个人电脑变成方便的云数据搜索和下载设备,从而节省不菲的开支。今天我们就为大家介绍,如何利用cpolar和Everything这两款软件,打造一个低成本轻量化的搜索和下载平台。
1. 下载cpolar和Everything软件
1.1 Everything 的介绍
首先我们来了解下这两款软件的功能。Everything 本质上是一款小巧但功能强大的文件搜索器,我们可以像搜索引擎一样搜索本地电脑上的文件,并且软件还提供了简易的http服务和指定端口输出功能。
1.2 cpolar 的介绍
而cpolar则是一款功能强大的内网穿透软件,能够建立并维持多条不同协议的数据隧道,如http、https、tcp、ftp等。而将两者结合在一起,就能实现云存储的核心功能之一,就是在公共互联网环境下,调取位于内网设备上的资料文件。
- 当然,由于Everything软件功能的缺失,暂时还无法在线阅读和上传文件回局域网设备。
1.3 下载软件搭建环境
想要搭建这一极简版的云存储平台,我们先要下载Everything和Cpolar。在软件安装程序下载完成后,双击安装程序即可自行安装。
1.4 操作步骤
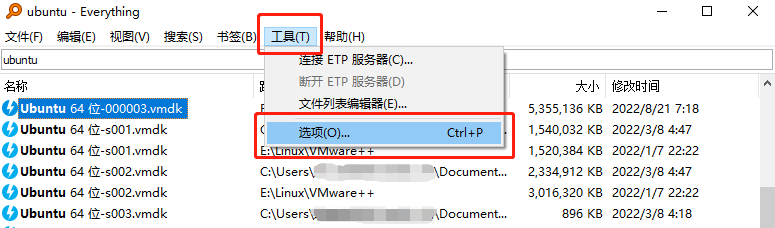
软件安装完成后,我们先打开Everything,对软件的输出端口进行设置。在Everything主界面上方的任务栏中,找到“工具”选项,点击后在下拉菜单中点击“选项”,就能找到关于http的设置内容。
2. 设定http服务器端口
2.1 Everything软件的http设置
在http设置内容中,我们先勾选“启用http服务器”,再设定http服务器端口。服务器端口的设定并没有太多要求,只要是未被占用的端口即可;接着要设定http服务器用户名和密码,此处可根据自己喜好进行设置;最后,为方便我们实际使用,最好将“允许http文件下载”也勾选,否则会导致远程搜索出的文件无法被获取。在完成以上设置后,就可以点击下方的“确定”按钮,完成Everything软件的http设置。
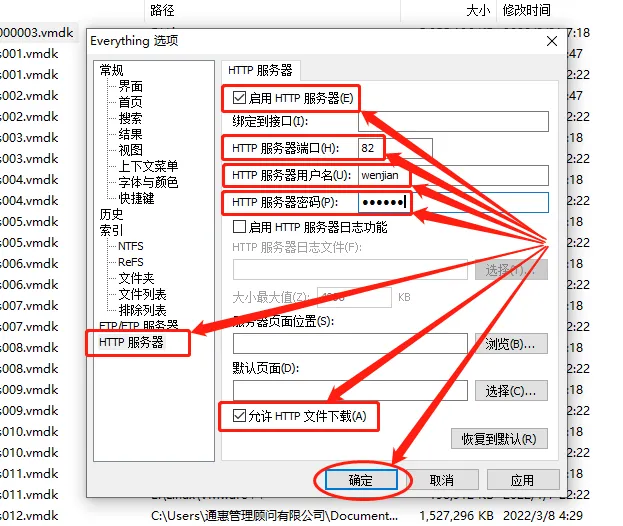
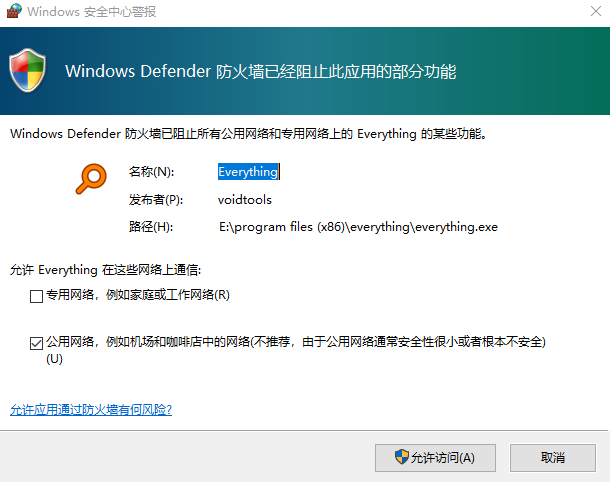
在保存Everything软件的http设置时,有可能跳出系统安全提示,这里我们点击“允许访问”即可。
3. 进入cpolar的设置
3.1 cpolar的设置
完成Everything的设置后,我们进入cpolar的设置,由于我们并不希望辛苦设置的Everything查询和下载隧道只能临时使用,因此有必要建立一条能够长期稳定访问的数据隧道。
首先我们进入cpolar的官网(可以在搜索引擎的搜索栏汇总输入cpolar查找官网,也可以在cpolar的Web-UI界面找到直连官网的快捷键)

首先是“地区”,这里我们按实际使用地填入即可,这个例子中我们选择China VIP;接着是“二级域名”,这里我们可以填入公司名称、部门名称、项目名称等任意信息,但保留的二级域名会显示在最终数据隧道地址URL上,因此最好不好胡乱填写。这里我们填入Everything;最后是“描述”栏位,这个栏位主要方便使用者将该二级域名与其他二级域名区分开来,因此可以填入方便识别的内容,这里我们填入“远程调资料”。
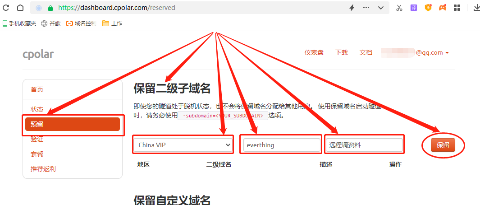
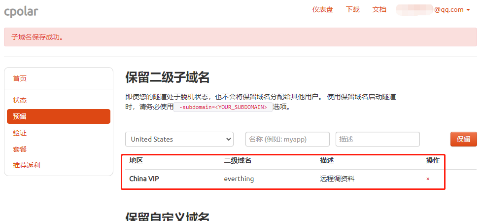
完成这些内容的填写后,就可以点击右侧的“保留”按钮。
3.2 空白数据隧道设置
建立一条未设定隧道出入口的空白数据隧道。
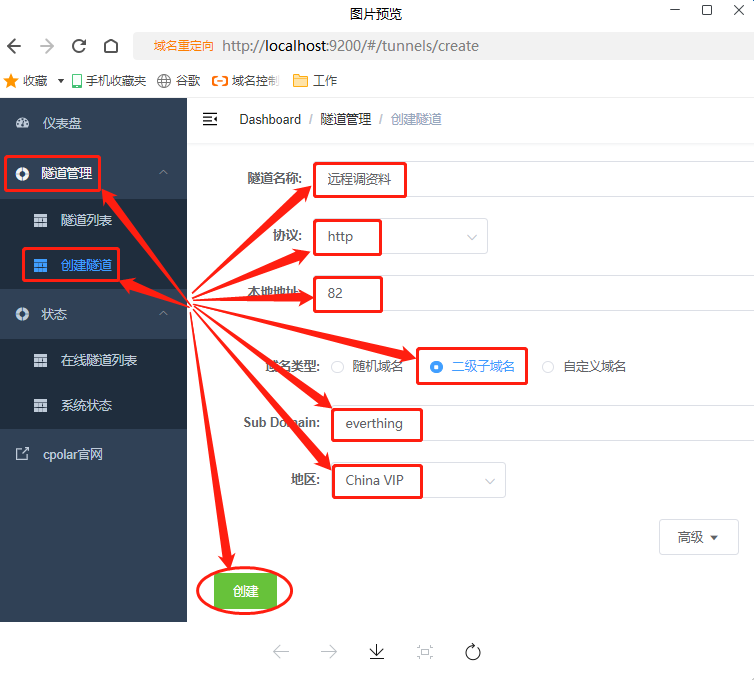
在空白数据隧道设置完毕后,我们就可以回到本地电脑的cpolar客户端,为这条空白数据隧道设定出入口。在本地电脑上打开cpolar的Web-UI界面,在主界面左侧找到“隧道管理”项下的“创建隧道”,将我们保留的二级子域名信息填入填入打算创建的隧道中,同时也为空白的数据隧道设定出入口。
4. 生成公网连到本地内网穿透数据隧道
4.1 配置具体数据
首先我们输入“隧道名称”,由于这一栏位并不会显示在外,因此可以自定选择,这里我们输入“远程调资料”;“协议”和“端口”栏位,分别选择“http”和“82”(82端口为之前为Everything设定的,也是数据隧道的出口,需要按实际设定端口号填入);接下来的“域名类型”栏位,我们选择“二级子域名”,选择二级子域名后,下方会出现“Sub Domain”栏,这里我们填入在cpolar官网保留的二级子域名(即所选用哪条保留的数据隧道);其后的“地区”栏位,可按实际使用地区填入,这里我们选择“China VIP”。完成这些设置后,就可以点击下方的“创建”按钮,生成能够从公共互联网连接到本地Everything软件的内网穿透数据隧道。

4.2 登录验证
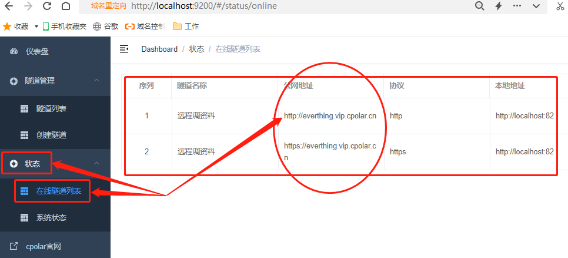
此时我们可以点击cpolar主界面左侧“状态”项下的“在线隧道列表”页面,找到这条数据隧道的入口,也就是公共互联网地址,从而在局域网以外的电脑上轻松查询和下载本地电脑上的文件资料。

总结
从以上介绍可以看出,自行建立一个能够远程调用下载本地资料的数据平台操作并不算复杂,非常适合小型企业和私人使用。当然,建立这样的远程数据调用平台只是cpolar强大功能的一个应用场景,cpolar建立的内网穿透数据隧道配合其他软件,还能有更多应用场景。如果您对cpolar的使用有任何疑问,欢迎与我们联系,我们必将为您提供力所能及的协助。当然也欢迎加入cpolar的VIP官方群,共同探索cpolar的无限潜能。
📝结尾
看到这里了还不给博主扣个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
拜托拜托这个真的很重要!
你们的点赞就是博主更新最大的动力!
有问题可以评论或者私信呢秒回哦。
