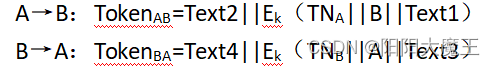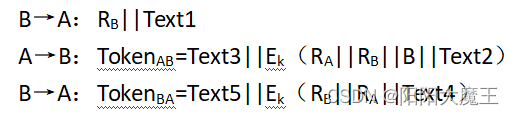著名设计网站营业执照网上申请
一、符号说明:
A→B:表示通信实体A向通信实体B发送消息;
Ek(x):表示用认证双方共享的密钥K对x进行加密;
Text1,Text2,……,Text n属于可选项;
||:表示比特链接;
RA:表示A生成的一次性随机数;
TNA:表示由A生成的时间戳或序列号;
KAB:通信实体A与通信实体B的共享密钥;
Kprt:可信第三方私钥;
Kprt:可信第三方公钥。
二、基于对称密码体制的身份认证:
对称密码体制是采用单一密钥的密码体制,即加解密都是用同一组密钥进行运算。对称密码体制下
的挑战/响应机制通常要求示证者和验证者共享对称密钥。
根据是否存在可信的第三方参与到身份认证过程中,对称密码身份认证可以分为无可信第三方认证
和有可信第三方认证两种。通常无可信第三方的对称密码认证用于只有少量用户的封闭系统,而有
可信第三方的对称密码认证则可用于规模相对较大的系统中。
(1)无可信第三方的对称密码认证
无可信第三方的对称密码认证的基本原理是验证者生成一个随机数作为挑战信息,发送给示证者;
示证者利用二者共享的密钥对该挑战信息进行加密,回传给验证者;验证者通过解密密文来验证示
证者的身份是否合法。认证过程描述如下:
① 无可信第三方对称密钥一次传输单向认证
A→B:TokenAB=Text2||Ek(TNA||B||Text1)
TokenAB中的B是可选项。A首先生成TokenAB并将其发送给B;B收到TokenAB后,解密并验证B
(如果包含)与TNA是否可接收。如果可接受则通过认证,否则拒绝。
② 无可信第三方对称密钥二次传输单向认证
B→A:RB||Text1
A→B:TokenAB=Text3||Ek(RB||B||Text2)
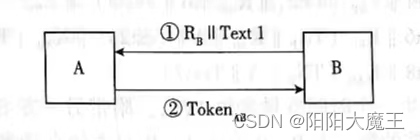
B首先生成一个随机数RB作为挑战信息发送给A(可附带选项Text1);A根据接收到的RB,利用
双方共享密钥加密生成响应信息TokenAB并发送回B;在收到TokenAB后,B通过解密查看随机数
RB是否与挑战信息中的一致,一致则接收A的认证,否则拒绝;
③ 无可信第三方对称密钥二次传输双向认证
A→B:TokenAB=Text2||Ek(TNA||B||Text1)
B→A:TokenBA=Text4||Ek(TNB||A||Text3)

与对称密钥一次传输单向认证一样,TokenAB和TokenBA中的A,B也为可选项,A生成TokenAB并
将其发送给B;B收到TokenAB后,解密并验证B(如果包含)与TNA是否可以接收,如果可接收则
通过认证;同样,B也可以生成TokenBA并来完成A对B的认证。此时需要注意的是,这两次认证的
过程都各自独立。
④ 无可信第三方对称密钥三次传输双向认证
B→A:RB||Text1
A→B:TokenAB=Text3||Ek(RA||RB||B||Text2)
B→A:TokenBA=Text5||Ek(RB||RA||Text4)

B首先生成一个随机数RB作为挑战信息发送给A(可附带可选项Text1);A生成一个随机数RA,
根据接收到的RB,利用双方共享密钥加密生成响应信息TokenAB后,B通过解密查看随机数RB是
否与第一次传输的挑战信息中的一致,如果一致则接收A的认证,并将RA和RB加密后生成的响应
消息TokenBA发送给A;A收到TokenBA后,通过解密检查RA和RB是否与之前传输的一致,如果一
致则接收B的认证,否则拒绝。
(2)有可信第三方的对称密码认证
与无可信第三方的对称密码认证技术相比,有可信第三方的对称密码认证技术的认证双方并不使用
共享密钥,而是各子与可信的第三方之间共享密钥。
有可信第三方的对称密码认证过程如下:
假设认证过程执行之前,认证的双方A和B已经分别安全地获得与可信地第三方——认证服务器P之
间地共享密钥EAP和EBP。
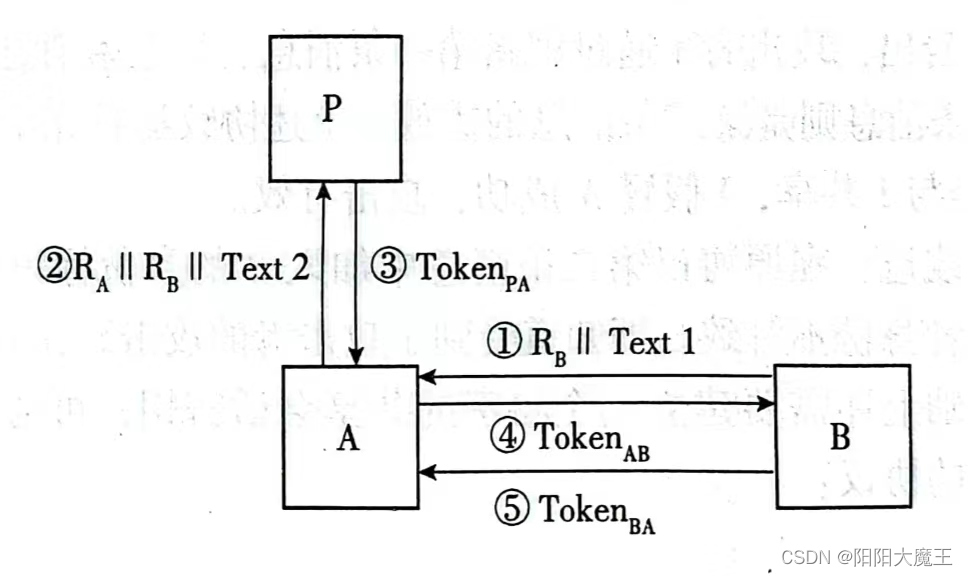
① 有可信第三方地对称密钥四次传输双向认证
A→P:TVPA||B||Text1
P→A:TokenPA=Text4||EAP(TVPA||KAB||B||Text3)||EBP(TNP||KAB||A||Text2)
A→B:TokenAB=Text6||EBP(TNP||KAB||A||Text2)||KAB(TNA||B||Text5)
B→A:TokenBA=Text8||KAB(TNB||A||Text7)
A产生一个时间变量参数TVPA,附带另一方B的ID,以及一个可选的附加信息Text1发送给可信的
第三方P;P生成A,B双方的会话密钥KAB,并分别用EAP和EBP加密后,合并生成消息TokenPA
发送给A;在收到信息TokenPA后,A解密TokenPA并获得TVPA,B和A,B双方的会话密钥KAB,
A检查TVPA和B是否正确;如果检查正确,A从TokenPA中提取“(TNP||KAB||A||Text2)”,并利用
A,B双方的会话密钥加密“(TNA||B||Text5)”,然后将它们合并生成消息TokenAB发送给B;B收
到消息TokenAB后,解密“EBP(TNP||KAB||A||Text2)”获得KAB,并利用其解密“KAB
(TNA||B||Text5)”,B根据解密得到的内容,检查用户ID,A,B,时间戳或序列号TNP,TNA的
正确性;如果B检查正确,则向A发送消息TokenBA;最后A通过TokenBA检查TNB和用户ID是否正
确,如果正确则完成整个认证过程。

如果只需要实现A向B的单向认证,则B在收到消息TokenAB后,只需要检查该消息正确与否即可。
如果正确,则可通过对A的身份认证。
② 有可信第三方地对称密钥五次传输双向认证
B→A:RB||Text1
A→P:RA||RB||B||Text2
P→A:TokenPA=Text5||EAP(RA||KAB||B||Text4)||EBP(RB||KAB||A||Text3)
A→B:TokenAB=Text7||EBP(RB||KAB||A||Text3)||KAB(R’A||RB||Text6)
B→A:TokenBA=Text9||KAB(RB||R’A||Text8)
B首先产生一个随机数RB并将其发送给A(可附带可选项Text1);A产生一个随机数RA,并联合
RB和B的ID一起发送至可信的第三方P;P生成A,B双方的会话密钥KAB,分别联合RA和RB,用
EAP和EBP加密后,并合并生成消息TokenPA发送给A;A收到消息TokenPA后,通过解密得到
KAB,并检查得到RA和B的ID正确性;如果检查正确,A产生一个随机数R’A,与RB一起用KAB进
行加密,并将加密得到的内容和从TokenPA中得到的内容“EBP(RB||KAB||A||Text3)”一起作为消
息TokenAB发送给B;B收到消息TokenAB后,解密“EBP(RB||KAB||A||Text3)”获得KAB,并利用
其解密“KAB(R’A||RB||Text6)”;B根据解密得到的内容,检查用户A的ID的正确性,以及两次解
密获得的RB值是否一致;如果B检擦完全正确,则向A发送消息TokenBA;最后A通过解密
TokenBA检查R’A和RB是否正确,如果正确则完成整个认证过程。
与有可信第三方的对称密钥四次传输身份认证相同,如果只需要实现A向B的单向认证,则B在收到
消息TokenAB后,只需要检查该消息正确与否。如果正确,则可通过对A的身份认证。
备注: