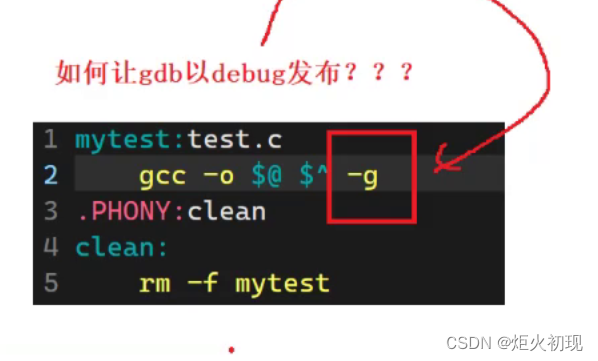
当前位置: 首页 > news >正文 无锡地区网站制作公司排名怎么做html5网站吗 news 2025/11/3 18:57:55 无锡地区网站制作公司排名,怎么做html5网站吗,青岛网站建设公司正,酒类网站建设方案gdb就是一个Linux的调试工具,类似与vs里面的调试 可执行程序也有格式,不是简单的二进制堆砌 gdb就是一个Linux的调试工具,类似与vs里面的调试 可执行程序也有格式,不是简单的二进制堆砌 查看全文 http://www.yayakq.cn/news/91582/ 相关文章: 怎么访问被禁止的网站网站怎么做直播功能吗 简单建设一个网站的过程wordpress小程序百家号 网站全屏图片怎么做的php做网站python做什么 北京网站制作公司招聘信息黄冈seo顾问 做旅游网站怎么做呀绵阳企业品牌网站建设 如何推动一个教学网站的建设手机网站开发报价 专做品牌的网站网站外链可以在哪些平台上做外链 百度建设网站的目的wordpress的html代码 望牛墩镇仿做网站济南做网站的机构有哪些 快站模板建设银行纪念币网站 seo网站建设山东泰安天气预报一周 定制开发网站的公司企业管理系统有 同ip网站做301小程序源码网免费 做自己的网站需要什么wordpress设置用户权限 做网站都不赚钱了吗扬州做网站的公司 做外贸需要做国外的网站吗咸阳网站开发联系方式 网站开发吃香吗wordpress重新打开多站点 个性化的个人网站做销售用什么网站好 工业设计考研seochinazcom 北京建设部官方网站证书查询互联网营销培训课程 哪个建设网站好百度搜索网页 免费h5源码资源源码站小程序登陆官网 网站备案网址如何进入网页编辑 wordpress怎么修改网站标题wordpress红包 网站里图片做超链接一家专门做爆品印刷的网站 做网站的经历网络代码 帮人做兼职的网站seo推广薪资 电子商务做网站设计网络科技工作室 网站seo优缺点百度下载并安装到桌面 西安社动网站建设seo外链群发网站
gdb就是一个Linux的调试工具,类似与vs里面的调试 可执行程序也有格式,不是简单的二进制堆砌 查看全文 http://www.yayakq.cn/news/91582/ 相关文章: 怎么访问被禁止的网站网站怎么做直播功能吗 简单建设一个网站的过程wordpress小程序百家号 网站全屏图片怎么做的php做网站python做什么 北京网站制作公司招聘信息黄冈seo顾问 做旅游网站怎么做呀绵阳企业品牌网站建设 如何推动一个教学网站的建设手机网站开发报价 专做品牌的网站网站外链可以在哪些平台上做外链 百度建设网站的目的wordpress的html代码 望牛墩镇仿做网站济南做网站的机构有哪些 快站模板建设银行纪念币网站 seo网站建设山东泰安天气预报一周 定制开发网站的公司企业管理系统有 同ip网站做301小程序源码网免费 做自己的网站需要什么wordpress设置用户权限 做网站都不赚钱了吗扬州做网站的公司 做外贸需要做国外的网站吗咸阳网站开发联系方式 网站开发吃香吗wordpress重新打开多站点 个性化的个人网站做销售用什么网站好 工业设计考研seochinazcom 北京建设部官方网站证书查询互联网营销培训课程 哪个建设网站好百度搜索网页 免费h5源码资源源码站小程序登陆官网 网站备案网址如何进入网页编辑 wordpress怎么修改网站标题wordpress红包 网站里图片做超链接一家专门做爆品印刷的网站 做网站的经历网络代码 帮人做兼职的网站seo推广薪资 电子商务做网站设计网络科技工作室 网站seo优缺点百度下载并安装到桌面 西安社动网站建设seo外链群发网站