新郑龙湖网站建设成功案例网站建设
在2024年的今天,要问我会如何优化seo,我会专注于几个关键的方面。首先,随着AI内容生成技术的发展,我会利用这些工具来帮助创建或优化我的网站内容,但是,随着谷歌3月份的算法更新,纯粹的ai内容可能变得不太受谷歌喜欢,所以必须确保这些内容不仅与主题相关,还必须是高质量的,满足Google的标准,ai可以用,但人为的精修也是必须的,纯粹的ai内容已经不受谷歌喜欢了此外,Google现在强调了一个新的评价标准——EEAT,其中的“E”代表“经验”,这意味着网站内容需要展现出更多的亲身经历和实际体验,这些是区分AI生成内容的关键因素,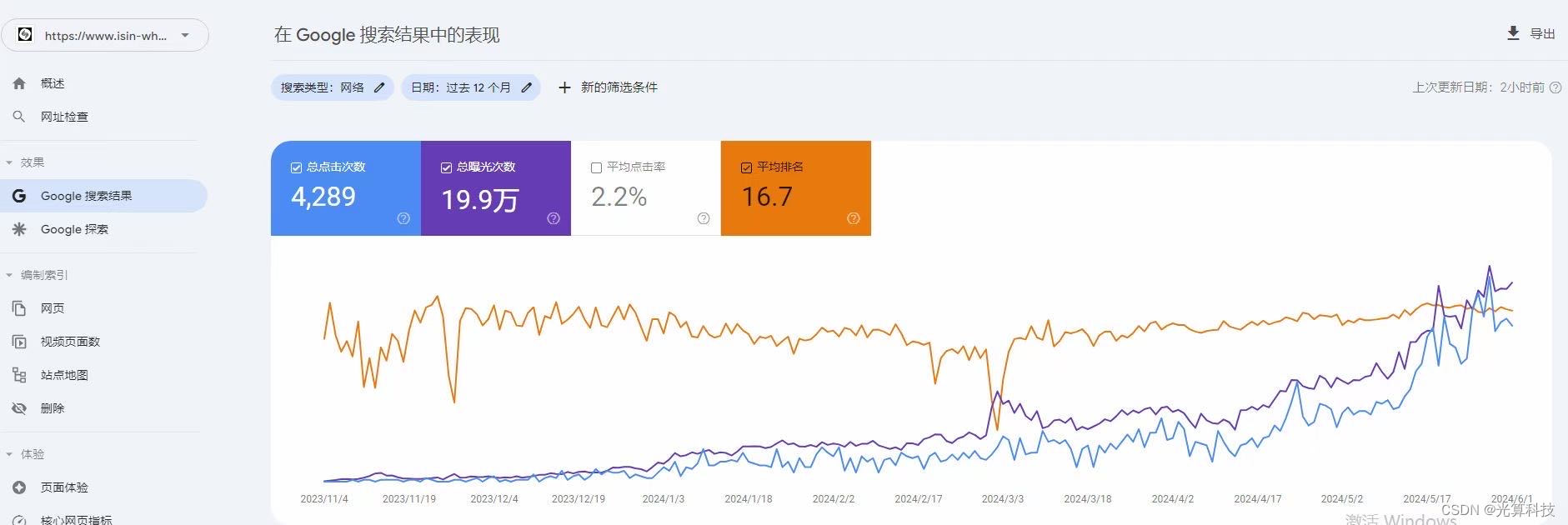 因此,我会努力分享更多基于真实经验的内容,以帮助提升我的网站质量评分最后,理解并满足用户的搜索意图是现在seo策略的核心,Google致力于帮助用户解决问题,需要通过精确地猜测和响应用户的搜索意图来提升网站内容,合理的用户信号反馈也会直接影响到网站排名,如果网站是工具性质的,就需要确保它能够满足用户的需求,从而获得正面的用户反馈
因此,我会努力分享更多基于真实经验的内容,以帮助提升我的网站质量评分最后,理解并满足用户的搜索意图是现在seo策略的核心,Google致力于帮助用户解决问题,需要通过精确地猜测和响应用户的搜索意图来提升网站内容,合理的用户信号反馈也会直接影响到网站排名,如果网站是工具性质的,就需要确保它能够满足用户的需求,从而获得正面的用户反馈