东莞东坑网站设计seo网络排名优化技巧
文章目录
- 前言
- 如何理解面向对象?
- 如何理解泛型编程?
- C++面向对象的三大特性是什么
- 构造函数有哪几种?
- 讲一下移动构造函数
- 当我们定义一个类 系统会自动帮我们生成哪些函数?
- 标题讲一下类中三类成员(公有私有保护)三种继承方式后的权限变化
- 讲一下面向对象的向上转型和向下转型
- 拷贝构造函数为何不能是值传递?
- 深拷贝和浅拷贝是什么?有什么区别?
- 拷贝构造函数用于深拷贝和浅拷贝的例子:
- 介绍一下成员函数的禁用函数delete
- 介绍一下类的静态变量和静态成员函数
- 静态成员变量为何要在类外初始化?
- 静态成员函数和静态函数的区别
- 介绍一下类的友元函数
- 函数重载和虚函数针对的对象有何不同?
- 介绍一下友元类
- 讲一下友元类和友元函数的区别?
- 讲一下this指针
- 如何理解被声明为const的成员函数?(如何理解常函数?)
- C++中的动态绑定是什么意思
- C++实现动态绑定的过程是什么样的(虚函数表怎么工作的)
- 静态类型和动态类型分别是什么?
- "动态绑定只适用于通过指针或引用访问对象的情况,直接通过对象调用虚函数时不会进行动态绑定" 这句话如何理解?
- 如何理解抽象类?
- 纯虚函数是什么 和虚函数是什么关系?
- 讲一下虚析构函数,为何没有虚构造函数?
- 除了构造函数,还有哪些函数不能设置为虚函数?
- 什么是菱形继承问题?
- 讲一下虚继承
- 讲一下typeid 函数在多态下的用法
- 使用函数模板有哪两种方式进行类型传递?
- 讲一下普通函数与函数模板在类型转换时的区别
- 普通函数的自动类型转换是什么?
- 类模板中成员函数和普通类中成员函数在实例化时机上的区别
- template<class NameType, class AgeType = int> 后面Int是在干啥
- 类模板对象做函数参数有哪些方式?
前言
秋招笔记汇总篇之C++面向对象特性,泛型编程特性
笔者是拿chatgpt写的,所以可能部分答案存在一定出路(3.5版本GPT有些缺陷),大部分答案我是写完了之后校正过一遍,有出入的地方还望各位同学指出。
2023.8.6首次更新
如何理解面向对象?
面向对象是一种编程范式,它将程序设计中的数据和操作封装为对象,并通过对象之间的交互来实现功能。面向对象的核心思想是将现实世界中的事物抽象为对象,对象具有属性(数据)和方法(操作),并且能够通过消息传递的方式与其他对象进行交互。
在面向对象的编程中,程序被组织为一组相互协作的对象,每个对象都有自己的状态(属性)和行为(方法)。对象之间通过消息传递来进行通信和交互,一个对象可以请求另一个对象执行某个操作,而被请求的对象则根据接收到的消息来执行相应的方法。
如何理解泛型编程?
泛型编程(Generic Programming)是一种编程范式,旨在实现通用和抽象的算法和数据结构,使其能够适用于多种数据类型,而不仅限于特定的数据类型。泛型编程的目标是在编写一次代码后,能够用于处理不同类型的数据,从而提高代码的复用性和灵活性。
在传统的编程语言中,通常需要为每种数据类型编写特定的代码,导致代码重复和冗余。而泛型编程通过使用类型参数(或称为泛型参数)来实现通用性,这样可以在编译时根据不同的类型生成特定的代码,从而避免了代码的重复编写。
一个常见的例子是C++中的模板(Template)机制。通过使用模板,可以编写通用的函数和类,然后在使用时指定具体的数据类型。这样,同一份模板代码可以在不同的数据类型上实例化,从而实现了泛型编程。
泛型编程的优点包括:
代码复用:可以编写一次代码,适用于多种数据类型,减少了代码的重复编写。
灵活性:能够处理不同类型的数据,使得程序更加灵活和可扩展。
性能优化:由于在编译时生成特定类型的代码,泛型编程可以在一定程度上提高程序的性能。
泛型编程在现代编程语言中得到广泛应用,例如C++、Java、C#等都支持泛型编程,使得编程变得更加高效和方便。STL(Standard Template Library)是C++标准库中的一个重要部分,它是泛型编程的一个典型例子。
C++面向对象的三大特性是什么
C++的面向对象编程具有三大特性,它们是:
封装(Encapsulation):封装是将数据和操作数据的方法(函数)组合在一起,形成一个类。通过封装,可以将数据隐藏在类的内部,只暴露必要的接口给外部使用。这样可以实现数据的安全性和保密性,同时也方便了代码的维护和重用。
继承(Inheritance):继承是指一个类可以继承另一个类的属性和方法。通过继承,可以构建类的层次结构,从而实现代码的重用和扩展。派生类可以继承基类的成员变量和成员函数,并且可以在派生类中添加新的成员或修改继承的成员。
多态(Polymorphism):多态是指同一个函数名可以根据不同的对象调用出不同的行为。多态可以通过虚函数**(重写)**和函数重载来实现。虚函数允许在子类中重写基类的函数,从而实现动态绑定。函数重载允许在同一个类中定义多个同名函数,但参数列表不同,根据调用时的参数类型进行匹配。
这三个特性共同组成了C++面向对象编程的基础,使得代码更加模块化、可扩展和易于理解。同时,它们也提供了更高层次的抽象和灵活性,使得程序设计更加灵活和可维护。
构造函数有哪几种?
构造函数是一种特殊的成员函数,用于在创建对象时初始化对象的数据成员。它的名称与类名相同,没有返回类型,并且可以有参数。在创建对象时,构造函数会被自动调用,用于初始化对象的状态。
根据参数的不同,构造函数可以分为以下几种类型:
默认构造函数(Default Constructor):没有参数的构造函数被称为默认构造函数。如果在类中没有定义任何构造函数,编译器会自动生成一个默认构造函数。默认构造函数的作用是创建一个对象并对其进行默认初始化。如果您在类中的某处提供了其他构造函数(例如带参数的构造函数),那么编译器将不再生成默认构造函数,除非您显式地声明它为 = default。
class Person {
public:Person() {name = "Unknown";age = 0;}// ...private:std::string name;int age;
};// 使用默认构造函数创建对象
Person p; // name = "Unknown", age = 0
带参数的构造函数(Parameterized Constructor):带有参数的构造函数可以接受一些初始值,并用这些值来初始化对象的数据成员。通过带参数的构造函数,可以在创建对象时指定初始化的值。
class Point {
public:Point(int x, int y) {this->x = x;this->y = y;}// ...private:int x;int y;
};// 使用带参数的构造函数创建对象
Point p(3, 5); // x = 3, y = 5
拷贝构造函数(Copy Constructor):拷贝构造函数用于创建一个新对象,并将其初始化为已有对象的副本。它通常接受一个同类型的对象作为参数,并将其数据成员复制到新对象中。拷贝构造函数在对象赋值、函数参数传递和函数返回值等场景中被调用。在C++11中还有移动赋值的概念
class Vector {
public:Vector(const Vector& other) {size = other.size;data = new int[size];for (int i = 0; i < size; i++) {data[i] = other.data[i];}}// ...private:int* data;int size;
};// 使用拷贝构造函数创建对象
Vector v1;
// 假设v1已经被初始化并赋值
Vector v2(v1); // 创建一个v1的副本v2
拷贝构造函数的格式:
ClassName(const ClassName& other) {// 构造函数的实现代码// 将other对象的数据成员复制到当前对象中
}
除了上述几种常见的构造函数类型,还有一些特殊的构造函数,例如:
移动构造函数(Move Constructor):移动构造函数用于在对象的资源所有权转移时进行高效的移动操作,而不是进行复制操作。移动构造函数通常用于实现移动语义,提高程序的性能。
转换构造函数(Conversion Constructor):转换构造函数用于将其他类型的对象转换为当前类的对象。它可以通过一个参数的构造函数来实现类型的隐式转换。
构造函数的选择和使用取决于具体的需求和设计。在类中可以定义多个构造函数,以满足不同的初始化需求。
注意:拷贝构造函数的参数传递是引用传递!
讲一下移动构造函数
移动构造函数是 C++11 引入的特性,用于在对象之间进行资源的高效转移,避免不必要的拷贝操作,提高性能。
在讲解之前,让我们先了解一下拷贝构造函数。拷贝构造函数用于创建一个对象的副本,通常在传递对象给函数、从函数返回对象、初始化对象时被调用。拷贝构造函数会将源对象的内容复制一份到目标对象,这可能涉及分配新的内存并复制数据。
移动构造函数通过右值引用(Rvalue reference)来接受临时对象,它可以将源对象的资源指针(如动态分配的内存)转移到目标对象中,而不需要实际的数据拷贝。这样可以避免不必要的内存分配和数据复制,提高性能。
下面是一个简单的示例,展示了移动构造函数的使用:
#include <iostream>class MyString {
private:char* data;public:// 构造函数MyString(const char* str) {size_t length = std::strlen(str) + 1;data = new char[length];std::strcpy(data, str);}// 移动构造函数MyString(MyString&& other) noexcept : data(other.data) {other.data = nullptr;}// 析构函数~MyString() {delete[] data;}// 打印字符串void print() const {std::cout << data << std::endl;}
};int main() {MyString str1("Hello, World!");// 使用移动构造函数将 str1 的资源转移到 str2MyString str2 = std::move(str1);std::cout << "str1: ";str1.print(); // 输出为空,资源已移动std::cout << "str2: ";str2.print(); // 输出 "Hello, World!"return 0;
}
在上面的示例中,MyString 类定义了一个移动构造函数,它将源对象的资源指针转移到目标对象,并将源对象的资源指针设为 nullptr,以确保在析构时不会重复释放资源。在 main 函数中,我们创建了一个 str1 对象,并使用 std::move 函数将其资源转移到 str2,这样就避免了不必要的数据拷贝和内存分配。
当我们定义一个类 系统会自动帮我们生成哪些函数?
在 C++ 中,当我们定义一个类时,编译器会自动为我们生成一些默认的成员函数,这些函数称为"特殊成员函数"。以下是系统会自动生成的默认成员函数:
默认构造函数(Default Constructor):如果我们没有显式定义任何构造函数,编译器会自动为类生成一个默认构造函数。默认构造函数没有参数,用于创建对象时不需要提供任何参数值。
拷贝构造函数(Copy Constructor):当我们使用一个对象初始化另一个对象,或者将对象作为参数传递给函数时,编译器会自动为类生成一个拷贝构造函数。拷贝构造函数用于创建一个新对象,该对象与传递给它的对象具有相同的值。
拷贝赋值运算符(Copy Assignment Operator):当我们使用一个对象给另一个对象赋值时,编译器会自动生成一个拷贝赋值运算符。该函数用于将一个对象的值复制到另一个对象。
移动构造函数(Move Constructor):C++11 引入了移动语义,如果我们没有显式定义移动构造函数,编译器会自动为类生成一个默认的移动构造函数。移动构造函数用于在对象所有权转移时进行高效的资源转移。
移动赋值运算符(Move Assignment Operator):C++11 同样引入了移动赋值运算符,如果我们没有显式定义该函数,编译器会自动为类生成一个默认的移动赋值运算符。
析构函数(Destructor):当对象的生命周期结束时(例如,对象超出作用域或通过 delete 运算符释放动态分配的对象),编译器会自动为类生成一个析构函数。析构函数用于释放对象所占用的资源,如释放动态分配的内存等。
需要注意的是,如果我们显式定义了一个构造函数、拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符或析构函数,编译器将不会自动生成相应的特殊成员函数。在这种情况下,我们需要确保自己实现这些函数的逻辑。
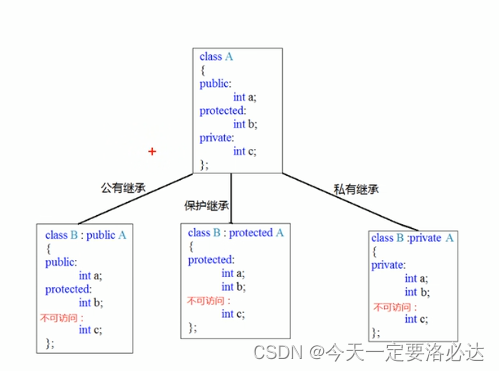
标题讲一下类中三类成员(公有私有保护)三种继承方式后的权限变化
如图所示(参考:黑马程序员)
讲一下面向对象的向上转型和向下转型
在面向对象编程中,涉及到子类和父类之间的转换,通常分为向上转型(子类转为父类)和向下转型(父类转为子类)两种操作。
向上转型(Upcasting):
向上转型是指将子类的对象转换为父类的对象。这种转型是隐式的,也就是说,不需要进行任何特殊的操作,编译器会自动完成。这是因为子类继承了父类的所有成员和方法,所以可以直接将子类对象当作父类对象来使用。
class Parent {
public:void someFunction() {// ...}
};class Child : public Parent {// ...
};int main() {Child childObj;Parent* parentPtr = &childObj; // 向上转型return 0;
}
向下转型(Downcasting):
向下转型是指将父类的指针或引用转换为子类的指针或引用。这种转型需要显示地进行,并且需要使用 C++ 的类型转换操作符 dynamic_cast 进行安全的转型,以防止在运行时出现类型不匹配的错误。
class Parent {
public:virtual void someFunction() {// ...}
};class Child : public Parent {// ...
};int main() {Parent* parentPtr = new Child;// 向下转型Child* childPtr = dynamic_cast<Child*>(parentPtr);if (childPtr) {// 转型成功,可以安全地使用 childPtr} else {// 转型失败,parentPtr 实际指向的不是 Child 类的对象}delete parentPtr;return 0;
}
需要注意的是,向下转型使用 dynamic_cast 进行类型检查,只有在父类指针或引用实际指向子类对象时,转型才会成功。如果父类指针指向的是其他类型的对象,则转型会失败。
总之,向上转型是隐式的,向下转型需要使用 dynamic_cast 进行显式转型,并进行类型检查以确保安全性。向下转型是相对不安全的操作
拷贝构造函数为何不能是值传递?
拷贝构造函数不能使用值传递的原因是,使用值传递会导致无限递归调用拷贝构造函数,从而导致栈溢出。
当我们使用值传递来传递一个对象作为参数时,会触发拷贝构造函数的调用。如果拷贝构造函数本身也是值传递的,那么在调用拷贝构造函数时,又会触发拷贝构造函数的调用,形成无限递归的循环。
例如,考虑以下代码片段:
class Vector {
public:Vector(const Vector& other) {// ...}
};Vector v1;
Vector v2(v1); // 使用值传递调用拷贝构造函数
在Vector v2(v1);这一行,如果拷贝构造函数是值传递的,那么它会尝试传递v1作为参数,触发拷贝构造函数的调用。然而,在拷贝构造函数内部又会尝试传递v1作为参数,再次触发拷贝构造函数的调用。这个过程会无限循环下去,直到栈溢出。
为了避免这种无限递归的情况发生,拷贝构造函数通常会使用引用传递(const Vector&)来传递对象参数,以确保只有一个拷贝构造函数被调用,从而避免无限递归。
拷贝构造函数可以使用指针传递,但这样做可能会导致潜在的问题。
使用指针传递作为拷贝构造函数的参数,意味着在拷贝构造函数中需要对指针进行解引用和内存分配,以创建新的对象副本。这样做可能会引发以下问题:
内存管理:拷贝构造函数需要负责分配新的内存空间来存储对象的副本,并确保在适当的时候释放这些内存。这就需要手动管理内存,容易出现内存泄漏或者释放错误的问题。
指针悬挂:如果在拷贝构造函数中使用指针传递,并且在析构函数中释放了指针指向的内存,那么在拷贝构造函数完成后,原始对象和新对象将共享相同的指针。这可能会导致在一个对象被销毁后,另一个对象仍然持有一个无效的指针,从而引发悬挂指针的问题。
深拷贝和浅拷贝是什么?有什么区别?
浅拷贝是指仅仅复制对象的成员变量的值,而不复制指向动态分配内存的指针。这意味着拷贝后的对象和原始对象将共享同一块内存,当一个对象修改了这块内存时,另一个对象也会受到影响。
深拷贝是指在拷贝对象时,不仅复制对象的成员变量的值,还复制指向动态分配内存的指针所指向的内存。这样,拷贝后的对象将拥有一份独立的内存副本,对其中一个对象的修改不会影响另一个对象。
在拷贝构造函数中,如果类中存在指向动态分配内存的指针成员变量,就需要进行深拷贝,以确保拷贝后的对象能够独立管理自己的内存。
eg:
lass Vector {
public:Vector(const Vector& other) {size = other.size;data = new int[size];for (int i = 0; i < size; i++) {data[i] = other.data[i];}}// ...private:int* data;int size;
};
Vector v1;
// 假设v1已经被初始化并赋值
Vector v2(v1); // 深拷贝,v2拥有独立的内存副本Vector v3 = v1; // 深拷贝,v3拥有独立的内存副本
Vector v2(v1); 和 Vector v3 = v1; 都是使用拷贝构造函数来创建对象的两种语法方式。
这两种方式都会调用拷贝构造函数,从已存在的对象v1创建一个新的对象v2和v3。拷贝构造函数会将v1的数据复制到v2和v3的独立内存副本中,确保每个对象拥有自己的数据副本。
两种语法方式的效果是一样的,都会进行深拷贝操作,使得v2和v3与v1拥有独立的内存副本。因此,无论是使用Vector v2(v1); 还是 Vector v3 = v1;,都会得到相同的结果。
拷贝构造函数用于深拷贝和浅拷贝的例子:
当需要实现深拷贝时,拷贝构造函数会创建一个新的对象,并复制原对象的数据到新对象中。这样,新对象和原对象将拥有各自独立的资源。
#include <iostream>class DeepCopyExample {
public:int* data;DeepCopyExample() {data = new int(0);}DeepCopyExample(const DeepCopyExample& other) {data = new int(*other.data);}~DeepCopyExample() {delete data;}
};int main() {DeepCopyExample obj1;*obj1.data = 10;DeepCopyExample obj2(obj1); // 使用拷贝构造函数进行深拷贝std::cout << *obj1.data << std::endl; // 输出:10std::cout << *obj2.data << std::endl; // 输出:10*obj2.data = 20;std::cout << *obj1.data << std::endl; // 输出:10std::cout << *obj2.data << std::endl; // 输出:20return 0;
}
在上述示例中,DeepCopyExample类包含一个指向堆内存的指针成员变量data。拷贝构造函数被用于实现深拷贝,它会为新对象obj2分配新的内存,并将原对象obj1的数据复制到新分配的内存中。这样,obj1和obj2将拥有各自独立的资源,修改一个对象的data不会影响另一个对象。
相反,当需要实现浅拷贝时,拷贝构造函数会简单地复制原对象的数据给新对象,新旧对象将共享同一份资源。
#include <iostream>class ShallowCopyExample {
public:int* data;ShallowCopyExample() {data = new int(0);}ShallowCopyExample(const ShallowCopyExample& other) {data = other.data;}~ShallowCopyExample() {// 注意:这里不需要手动释放 data,因为多个对象共享同一份资源}
};int main() {ShallowCopyExample obj1;*obj1.data = 10;ShallowCopyExample obj2(obj1); // 使用拷贝构造函数进行浅拷贝std::cout << *obj1.data << std::endl; // 输出:10std::cout << *obj2.data << std::endl; // 输出:10*obj2.data = 20;std::cout << *obj1.data << std::endl; // 输出:20std::cout << *obj2.data << std::endl; // 输出:20return 0;
}
在上述示例中,ShallowCopyExample类同样包含一个指向堆内存的指针成员变量data。拷贝构造函数被用于实现浅拷贝,它会简单地将原对象obj1的data指针赋值给新对象obj2。这样,obj1和obj2将共享同一份资源,修改一个对象的data会影响另一个对象。
介绍一下成员函数的禁用函数delete
在C++中,如果您希望禁用某个类的特定成员函数,可以通过将其声明为 delete 来实现。delete 是C++11引入的关键字,用于删除类的特定成员函数,从而防止其被调用。
示例:禁用默认构造函数
class MyClass {
public:// 默认构造函数被禁用MyClass() = delete;// 带参数的构造函数MyClass(int value) {// 构造函数实现}
};int main() {// 使用默认构造函数会导致编译错误// MyClass obj; // 编译错误,因为默认构造函数被禁用// 使用带参数的构造函数创建对象MyClass obj(42); // 正常创建对象return 0;
}
在上面的示例中,MyClass 类的默认构造函数被声明为 delete,因此在 main() 函数中尝试使用默认构造函数来创建对象时,会导致编译错误。只能使用带参数的构造函数来创建对象。
同样,您可以将其他成员函数也声明为 delete 来禁用它们的使用。这种做法可以用于防止意外调用某些函数,或者在特定情况下强制使用特定的构造函数。
介绍一下类的静态变量和静态成员函数
类的静态变量和静态成员函数是与类本身相关联而不是与类的实例对象相关联的成员。它们在整个类的所有实例对象之间共享,并且可以通过类名直接访问,而不需要创建类的实例。
1)静态变量(静态数据成员):
静态变量是在类中用 static 关键字声明的成员变量。它们属于类本身,而不是类的任何特定实例对象。静态变量只有一份拷贝,被所有该类的实例对象共享。
class MyClass {
public:// 静态变量static int staticVar;
};// 静态变量的初始化
int MyClass::staticVar = 0;int main() {MyClass obj1;MyClass obj2;// 修改静态变量的值MyClass::staticVar = 42;// 输出静态变量的值std::cout << "obj1.staticVar: " << obj1.staticVar << std::endl; // 输出 42std::cout << "obj2.staticVar: " << obj2.staticVar << std::endl; // 输出 42return 0;
}
2)静态成员函数:
静态成员函数是在类中用 static 关键字声明的成员函数。与静态变量类似,静态成员函数不属于类的实例对象,而是属于类本身。因此,它们不具有 this 指针 不能直接访问非静态成员变量和非静态成员函数()言下之意就是只能访问与静态成员变量相关的东西)。
class MyClass {
public:// 静态成员函数static void staticFunction() {std::cout << "This is a static member function." << std::endl;}
};int main() {// 调用静态成员函数,无需创建类的实例对象MyClass::staticFunction(); // 输出 "This is a static member function."return 0;
}
静态变量和静态成员函数的主要特点和用途:
与类的实例对象无关,属于整个类。
可以通过类名直接访问,无需创建对象。
静态变量用于表示类共享的状态或属性。
静态成员函数通常用于执行与类相关的全局操作,无需访问类的实例状态。
需要注意的是,在静态成员函数中不能直接访问非静态成员变量和非静态成员函数,但可以通过创建类的实例对象来访问。同时,静态成员函数也可以被声明为 const 或 volatile,取决于是否需要修改静态变量的值。
静态成员变量为何要在类外初始化?
静态成员变量需要在类的外部进行初始化,而不能在类的内部进行初始化。
在C++中,静态成员变量属于类本身,而不是属于类的每个对象。因此,为了分配内存并初始化静态成员变量,必须在类的外部进行这些操作。
以下是静态成员变量的定义和初始化的示例:
class MyClass {
public:static int staticVar; // 静态成员变量声明,不要在这里进行初始化
};// MyClass.cpp 源文件
int MyClass::staticVar = 42; // 静态成员变量的初始化
静态成员函数和静态函数的区别
静态成员函数和静态函数是两种不同的概念,它们在不同的语境和用途下使用。下面是它们之间的区别:
1)静态成员函数(C++):
隶属于类:静态成员函数是属于类的一部分,而不是属于类的实例对象。它与类的所有实例对象无关,不能访问非静态成员变量和成员函数。
用途:静态成员函数用于执行与类相关的全局操作,不依赖于实例的状态。它可以通过类名直接调用,无需创建类的实例对象。
示例用途:用于计算、转换、工具函数等,而不需要访问实例的具体状态。
2)静态函数(C语言):
隶属于源文件:静态函数是在定义它的源文件中可见的,其作用域仅限于同一个源文件内。它不能被其他源文件直接访问,用于限制函数的可见性,避免命名冲突。
用途:静态函数用于封装和隐藏函数的实现细节,同时避免与其他源文件中的函数名称发生冲突。它通常用于在模块化编程中实现私有的辅助函数。
总结:
静态成员函数是属于类的一部分,用于执行与类相关的全局操作,不依赖于实例的状态。它可以通过类名直接调用。
静态函数是在定义它的源文件中可见的,用于限制函数的作用域,避免与其他源文件中的函数名称发生冲突。它通常用于隐藏函数的实现细节。
需要注意的是,上述区别仅适用于C++和C语言的语境。在其他编程语言中,这些概念可能会有不同的实现和用法。
介绍一下类的友元函数
类的友元函数是在 C++ 中一种特殊的函数,它可以访问类的私有成员和保护成员,尽管这些成员在一般情况下不能被类外部的函数访问。友元函数通过在类的声明中使用 friend 关键字来声明。
友元函数的特点:
友元函数不是类的成员函数,它可以定义在类的内部或外部。
友元函数可以访问类的所有成员,包括私有成员和保护成员。
友元函数在权限上与普通函数相同,没有 this 指针,因此不能直接访问非静态成员变量和非静态成员函数。
下面是一个简单的示例,展示了如何在类中声明友元函数:
class MyClass {
private:int data;public:MyClass(int num) : data(num) {}// 声明友元函数friend void friendFunction(const MyClass& obj);
};// 定义友元函数,在类外部实现
void friendFunction(const MyClass& obj) {std::cout << "Friend function can access private data: " << obj.data << std::endl;
}int main() {MyClass obj(42);friendFunction(obj);return 0;
}
在上面的示例中,我们定义了一个类 MyClass,其中包含一个私有成员 data。在类的声明中,我们使用 friend 关键字声明了一个名为 friendFunction 的友元函数。这样,在 friendFunction 中就能够访问 MyClass 类的私有成员 data。
需要注意的是,友元函数通常用于增强类的封装性,但过度使用友元函数可能会破坏封装性,因为它们可以访问类的私有成员,从而绕过类的公有接口。因此,在使用友元函数时,应该慎重考虑,并确保其用途合理。
函数重载和虚函数针对的对象有何不同?
函数重载和虚函数的作用对象不同。函数重载主要针对同一个类内的函数,通过参数的不同来区分同名函数的调用。而虚函数主要针对基类和派生类之间的函数,通过在基类中声明虚函数,并在派生类中进行重写,实现在运行时根据对象的实际类型来确定调用哪个类的函数。
函数重载和虚函数对应着静态多态和动态多态。(早绑定和晚绑定)
静态多态性通过函数重载在编译时解析函数调用,而动态多态性通过虚函数在运行时解析函数调用。静态多态性在编译时确定函数的调用方式,因此效率较高,但灵活性较低;而动态多态性在运行时确定函数的调用方式,具有更高的灵活性,但会带来一定的运行时开销。
介绍一下友元类
友元类(Friend Class)是在C++中声明一个类能够访问另一个类的所有私有成员。下面我用一个简单的示例来介绍友元类:
#include <iostream>// 前向声明
class B;class A {
private:int privateDataA;public:A(int data) : privateDataA(data) {}// 声明B类为友元类friend class B;
};class B {
private:int privateDataB;public:B(int data) : privateDataB(data) {}// 可以访问A类的私有成员 privateDataA,因为A类声明了B为友元类void accessAData(A& objA) {std::cout << "Accessing privateDataA from class A: " << objA.privateDataA << std::endl;}
};int main() {A objA(10);B objB(20);// 在B类中可以访问A类的私有成员 privateDataAobjB.accessAData(objA);return 0;
}
在上面的示例中,我们有两个类A和B,类A中声明了类B为友元类。这意味着类B可以访问类A中的所有私有成员,即使它们是私有的。
在main函数中,我们创建了一个A类的对象objA和一个B类的对象objB。然后,在B类的成员函数accessAData中,我们可以直接访问A类的私有成员privateDataA,这是因为A类声明了B类为友元类。
友元类的用途是允许不同类之间共享私有成员,这在某些特定情况下可能很有用,但应该小心使用,以确保不会破坏类的封装性和数据安全性。
讲一下友元类和友元函数的区别?
友元类和友元函数是C++中的两个特性,它们都涉及到访问类的私有成员。下面我会分别介绍它们,并解释它们之间的区别:
1)友元类(Friend Class):
友元类是在一个类的声明中通过 friend 关键字声明的另一个类。声明为友元类的类可以访问该类中的所有私有成员,包括私有变量和私有函数。
友元关系是单向的,即如果类A声明类B为友元类,那么类B不自动声明类A为友元类。需要在类B中单独声明类A为友元类,如果需要让两个类互相访问私有成员的话。
2)友元函数(Friend Function):
友元函数是在一个类中通过 friend 关键字声明的全局函数。声明为友元函数的函数可以访问该类中的所有私有成员,类似于友元类的功能。
友元函数不属于类本身,但它能够访问类的私有成员。这使得我们可以在类外部定义一些操作类私有成员的函数,并将它们声明为友元函数,从而增加类的灵活性和封装性。
区别:
友元类是声明一个类能够访问另一个类的所有私有成员,而友元函数是声明一个全局函数能够访问一个类的所有私有成员。
友元关系是单向的:如果类A声明类B为友元类,类B不自动声明类A为友元类。需要在类B中单独声明类A为友元类,如果需要让两个类互相访问私有成员的话。
友元函数不属于类本身,而友元类是类本身的一部分。
需要谨慎使用友元特性,因为它会破坏类的封装性,导致代码更难维护。友元特性应该在确保必要的情况下才使用,尽量避免过度使用。
讲一下this指针
在C++中,this 指针是一个特殊的指针,它是一个隐含在每个非静态成员函数(即类的成员函数)中的指针。this 指针指向当前对象的地址,也就是调用该成员函数的对象实例的地址。通过 this 指针,我们可以在成员函数内部访问当前对象的成员变量和成员函数。
当一个成员函数被调用时,C++编译器会将调用该函数的对象的地址传递给 this 指针。这样,在函数体内部就可以使用 this 指针来访问对象的成员。
this 指针的使用情况:
在成员函数内部访问成员变量:this->memberVariable
在成员函数内部调用其他成员函数:this->memberFunction()
下面是一个简单的示例来展示 this 指针的使用:
#include <iostream>class MyClass {
private:int x;public:MyClass(int value) : x(value) {}void printX() {// 使用 this 指针访问成员变量 xstd::cout << "Value of x: " << this->x << std::endl;}void setX(int value) {// 使用 this 指针设置成员变量 x 的值this->x = value;}void printAddress() {// 使用 this 指针输出当前对象的地址std::cout << "Address of the current object: " << this << std::endl;}
};int main() {MyClass obj1(5);MyClass obj2(10);obj1.printX(); // 输出:Value of x: 5obj2.printX(); // 输出:Value of x: 10obj1.printAddress(); // 输出:Address of the current object: 0x7ffc6b234f40obj2.printAddress(); // 输出:Address of the current object: 0x7ffc6b234f3creturn 0;
}
在上面的示例中,我们定义了一个名为 MyClass 的类,其中包含了一个成员变量 x 和几个成员函数。在 printX() 和 setX() 函数中,我们使用 this 指针来访问对象的成员变量 x。在 printAddress() 函数中,我们使用 this 指针输出当前对象的地址。
需要注意的是,静态成员函数没有 this 指针,因为静态成员函数是属于类本身而不是类的对象。在静态成员函数中不能使用 this 指针。
this指针常用作变量值初始化,类比python的self
如何理解被声明为const的成员函数?(如何理解常函数?)
当一个成员函数被声明为 const 时,**它被视为一个只读函数,即该函数不能修改任何成员变量。**这样做的目的是为了确保在对象的 const 上下文中,该函数不会引入任何副作用。
以下是一些常见的情况,可以使用 const 成员函数:
1)打印对象的信息:例如,打印对象的属性值、状态等。这些操作只是读取对象的信息,不会修改对象的状态。
2)获取对象的信息:例如,返回对象的某个属性值、计算对象的某些属性等。这些操作只是读取对象的信息,不会修改对象的状态。
3)比较对象的相等性:例如,重载 == 运算符来比较对象的相等性。这个操作只是读取对象的信息,不会修改对象的状态。
下面是一个示例来展示不加 const 和加了 const 的区别:
class MyClass {
public:void modifyValue() {value = 10; // 可以修改非 const 成员变量}void printValue() const {// value = 20; // 编译错误,不允许修改非 mutable 成员变量std::cout << "Value: " << value << std::endl; // 可以读取非 const 成员变量}private:int value;
};int main() {MyClass obj;obj.modifyValue();obj.printValue(); // 输出:Value: 10const MyClass constObj;// constObj.modifyValue(); // 编译错误,不允许在 const 对象上调用非 const 成员函数constObj.printValue(); // 输出:Value: 10return 0;
}
在上述代码中,MyClass 类有一个成员变量 value 和两个成员函数 modifyValue() 和 printValue()。modifyValue() 函数没有被声明为 const,因此它可以修改成员变量 value 的值。而 printValue() 函数被声明为 const,因此它只能读取成员变量的值,而不能修改。
在 main() 函数中,首先创建了一个 MyClass 对象 obj,然后调用 modifyValue() 函数修改了 value 的值为 10,并通过 printValue() 函数打印出了修改后的值。
接着,创建了一个 const MyClass 对象 constObj,由于 constObj 是一个 const 对象,因此不能调用 modifyValue() 函数来修改成员变量的值。但是可以通过 printValue() 函数来读取成员变量的值。
如果一个虚函数在基类中被声明为 const,那么后续的派生类中重写该虚函数时,也必须将其声明为 const。这是因为派生类中的虚函数必须与基类中的虚函数具有相同的签名,包括 const 修饰符。
C++中的动态绑定是什么意思
动态绑定是实现多态性的一种机制。
动态绑定通过在基类中声明虚函数,并在派生类中进行重写,实现了在运行时根据对象的实际类型来确定调用哪个函数。当通过基类指针或引用调用虚函数时,会根据对象的实际类型来动态绑定到正确的函数,实现了多态性。
因此,动态绑定是实现多态性的关键机制之一。它使得我们可以以统一的方式处理不同类型的对象,提高了代码的灵活性和可维护性。通过动态绑定,我们可以在运行时根据对象的实际类型来调用正确的函数,而不需要在编译时就确定函数的具体实现。这为实现多态性提供了便利和灵活性。
一个简单的图形类为例来说明动态绑定的概念。
#include <iostream>class Shape {
public:virtual void draw() {std::cout << "Drawing a generic shape." << std::endl;}
};class Circle : public Shape {
public:void draw() override {std::cout << "Drawing a circle." << std::endl;}
};class Square : public Shape {
public:void draw() override {std::cout << "Drawing a square." << std::endl;}
};int main() {Shape* shape1 = new Circle();Shape* shape2 = new Square();shape1->draw(); // 动态绑定,调用Circle类的draw函数shape2->draw(); // 动态绑定,调用Square类的draw函数delete shape1;delete shape2;return 0;
}
在这个例子中,我们有一个基类 Shape 和两个派生类 Circle 和 Square。基类 Shape 声明了一个虚函数 draw(),并在派生类中进行了重写。
在 main() 函数中,我们创建了两个指向基类的指针 shape1 和 shape2,分别指向 Circle 和 Square 的对象。然后,通过这两个指针调用 draw() 函数。
由于 draw() 函数是虚函数,并且在派生类中进行了重写,因此在运行时,实际上会根据对象的实际类型来调用正确的函数。即使 shape1 和 shape2 的静态类型是基类 Shape,但由于动态绑定的存在,它们调用的是各自派生类中重写的 draw() 函数。
输出结果:
Drawing a circle.
Drawing a square.
C++实现动态绑定的过程是什么样的(虚函数表怎么工作的)
在C++中,当一个类声明了虚函数时,编译器会为该类生成一个虚函数表(vtable),该表存储了该类中所有虚函数的地址。每个对象都会有一个指向虚函数表的虚函数指针(vptr),该指针在对象创建时被初始化。
当通过基类指针或引用调用虚函数时,编译器会使用虚函数指针(vptr)来访问对象的虚函数表(vtable),根据函数在虚函数表中的索引,确定要调用的函数地址。这个过程就是动态绑定。
具体步骤如下:
1)对象创建时,虚函数指针(vptr)被初始化指向类的虚函数表(vtable)。
2)当通过基类指针或引用调用虚函数时,编译器会使用虚函数指针(vptr)来访问对象的虚函数表(vtable)。
3)根据函数在虚函数表中的索引,确定要调用的函数地址。
4)调用对应的虚函数。
由于虚函数表是在编译时生成的,并且每个对象都有自己的虚函数指针,所以可以在运行时根据对象的实际类型来确定要调用的函数,实现了多态性。
需要注意的是,动态绑定只适用于通过指针或引用访问对象的情况,而直接通过对象调用虚函数时,编译器会根据对象的静态类型来确定要调用的函数,不会进行动态绑定。
静态类型和动态类型分别是什么?
静态类型和动态类型是编程中的两个概念,用于描述对象在编译时和运行时的类型。
静态类型是在编译时已知的类型,它是通过对象的声明类型来确定的。在静态类型语言中,变量的类型在编译时就需要确定,并且在运行时不能改变。例如,C++、Java、C#等都是静态类型语言。
动态类型是在运行时确定的类型,它是对象实际所属的类型。在动态类型语言中,变量的类型可以在运行时根据赋值给它的对象的类型来确定。例如,Python、JavaScript等都是动态类型语言。
假设我们有一个基类 Animal 和两个派生类 Dog 和 Cat,它们都有一个虚函数 makeSound()。
class Animal {
public:virtual void makeSound() {cout << "Animal makes a sound." << endl;}
};class Dog : public Animal {
public:void makeSound() override {cout << "Dog barks." << endl;}
};class Cat : public Animal {
public:void makeSound() override {cout << "Cat meows." << endl;}
};
现在我们创建一个指向 Animal 类型的指针,并将其指向一个 Dog 对象:
Animal* animal = new Dog();
在这里,animal 的静态类型是 Animal*,因为我们将其声明为指向 Animal 类型的指针。
但是,animal 指向的实际对象的动态类型是 Dog。
(在编译时,animal 的静态类型是 Animal*,它在编译后仍然是 Animal* 类型。但是在运行时,根据对象的动态类型来调用相应的函数。)
“动态绑定只适用于通过指针或引用访问对象的情况,直接通过对象调用虚函数时不会进行动态绑定” 这句话如何理解?
如果你有一个基类指针或引用指向派生类对象,并通过该指针或引用调用虚函数,编译器会根据对象的实际类型来确定要调用的函数,实现动态绑定。这是因为基类指针或引用可以指向派生类对象,并且通过虚函数表来查找正确的函数。
但是,如果你直接通过对象调用虚函数,编译器会根据对象的静态类型来确定要调用的函数,而不会进行动态绑定。这是因为对象的类型在编译时就已经确定了(这句话的意思是没有动态绑定的环节了),编译器可以直接知道要调用的函数是哪个,不需要通过虚函数表进行查找。
以下是一个示例来说明这个问题:
#include <iostream>class Base {
public:virtual void func() {std::cout << "Base::func()" << std::endl;}
};class Derived : public Base {
public:void func() override {std::cout << "Derived::func()" << std::endl;}
};int main() {Base* obj = new Derived();obj->func(); // 动态绑定到 Derived 类的 func 函数Derived derivedObj;derivedObj.func(); // 静态绑定到 Derived 类的 func 函数delete obj;return 0;
}
在上述代码中,Base 类和 Derived 类分别定义了一个虚函数 func(),派生类 Derived 重写了基类的虚函数。
在 main() 函数中,创建了一个指向派生类对象的基类指针 obj。通过基类指针调用虚函数时,会根据对象的实际类型进行动态绑定,所以调用的是派生类 Derived 中的函数。
另外,直接创建了一个 Derived 类的对象 derivedObj,并直接通过对象调用虚函数。在这种情况下,编译器会根据对象的静态类型(即 Derived 类)确定要调用的函数,所以调用的也是派生类 Derived 中的函数。
运行上述代码,输出结果为:
Derived::func()
Derived::func()
可以看到,通过基类指针调用虚函数时,会进行动态绑定,调用的是对象的实际类型对应的函数。而直接通过对象调用虚函数时,会进行静态绑定,调用的是对象的静态类型对应的函数。
如何理解抽象类?
抽象类是一种不能被实例化的类,它的主要目的是作为其他类的基类,定义了一组接口或纯虚函数,要求派生类必须实现这些接口或纯虚函数。纯虚函数是在抽象类中声明的虚函数,
纯虚函数是什么 和虚函数是什么关系?
纯虚函数(Pure Virtual Function)是在基类中声明但没有实现的虚函数 它的声明形式为在函数原型后面加上 = 0。纯虚函数的存在是为了让基类可以定义一个接口,但不需要提供具体的实现。
纯虚函数的目的是为了让派生类必须提供自己的实现。派生类在继承了包含纯虚函数的基类后,必须实现纯虚函数,否则派生类也会成为抽象类,无法实例化。
纯虚函数(Pure Virtual Function)是虚函数的一种特殊形式。虚函数是在基类中声明并且有默认实现的函数,而纯虚函数则是在基类中声明但没有提供默认实现的函数。
以下是一个具体的例子:
#include <iostream>class Shape {
public:virtual double getArea() const = 0; // 纯虚函数
};class Circle : public Shape {
private:double radius;public:Circle(double r) : radius(r) {}double getArea() const override {return 3.14 * radius * radius;}
};class Rectangle : public Shape {
private:double width;double height;public:Rectangle(double w, double h) : width(w), height(h) {}double getArea() const override {return width * height;}
};int main() {Circle circle(5.0);Rectangle rectangle(3.0, 4.0);Shape* shapePtr1 = &circle;Shape* shapePtr2 = &rectangle;std::cout << "Circle area: " << shapePtr1->getArea() << std::endl;std::cout << "Rectangle area: " << shapePtr2->getArea() << std::endl;return 0;
}
在上述代码中,Shape 类是一个抽象基类,它包含一个纯虚函数 getArea()。Circle 类和 Rectangle 类都继承自 Shape 类,并且必须实现 getArea() 函数。
在 main() 函数中,创建了一个 Circle 类的对象和一个 Rectangle 类的对象,并将它们的地址分别赋值给 Shape 类的指针 shapePtr1 和 shapePtr2。
通过 shapePtr1 和 shapePtr2 调用 getArea() 函数时,会根据指针指向的实际对象类型来调用相应的函数。这就体现了多态性的特性。
纯虚函数使得基类成为一个抽象类,无法实例化,只能被用作其他类的基类。派生类必须实现纯虚函数,否则它们也会变成抽象类。在上述例子中,Circle 类和 Rectangle 类分别实现了 getArea() 函数,以计算各自的面积。
通过使用纯虚函数,可以定义抽象的接口,让派生类根据自身的特性来实现具体的功能。这种设计方式提供了灵活性和可扩展性,同时也强制了派生类的实现。
讲一下虚析构函数,为何没有虚构造函数?
虚析构函数和虚构造函数是C++中的两个特殊的虚函数,用于管理对象的生命周期和多态性。
虚析构函数(Virtual Destructor):
虚析构函数是在基类中声明为虚函数的析构函数。它的作用是确保在删除指向派生类对象的基类指针时,能够正确调用派生类的析构函数,从而释放对象的资源。
虚析构函数的声明形式为:
virtual ~ClassName();其中,ClassName是类的名称。
使用虚析构函数的主要场景是当基类指针指向派生类对象时,通过基类指针删除对象时,可以确保调用派生类的析构函数,从而正确释放派生类对象的资源。
当使用基类指针指向派生类对象时,通过虚析构函数可以确保调用派生类的析构函数,从而正确释放派生类对象的资源。下面是一个简单的例子:
#include <iostream>class Base {
public:virtual ~Base() {std::cout << "Base destructor called" << std::endl;}
};class Derived : public Base {
public:~Derived() {std::cout << "Derived destructor called" << std::endl;}
};int main() {Base* ptr = new Derived(); // 使用基类指针指向派生类对象delete ptr; // 删除基类指针,会调用派生类的析构函数return 0;
}
在上面的例子中,Base是基类,Derived是派生类。在Base类中声明了虚析构函数,而在Derived类中重写了析构函数。
在main函数中,通过new关键字创建了一个Derived类的对象,并将其地址赋给了一个Base类的指针ptr。然后,通过delete关键字删除了ptr指针,这会触发对象的析构过程。
由于Base类的析构函数被声明为虚函数,因此在删除指针时,会根据实际对象的类型来调用相应的析构函数。在这个例子中,会调用Derived类的析构函数,输出Derived destructor called。
通过使用虚析构函数,可以确保在删除基类指针时,能够正确调用派生类的析构函数,从而释放派生类对象的资源。
如果不适用虚析构函数的话:删除基类指针时只会调用基类的析构函数,而不会调用派生类的析构函数。这种情况下,派生类对象的资源不会被正确释放,可能导致内存泄漏或其他问题。因此,当基类指针指向派生类对象时,使用虚析构函数是非常重要的,以确保能够正确调用派生类的析构函数并释放对象的资源。
虚构造函数(Virtual Constructor):
首先我们需要知道一个概念:虚函数表是在对象的构造过程中创建的,它存储了类的虚函数的地址,并用于实现动态绑定。
虚构造函数是一种概念,实际上在C++中并没有直接支持虚构造函数的语法。虚构造函数的概念是指通过基类指针或引用创建派生类对象时,能够根据实际对象的类型来调用相应的构造函数。
在C++中,构造函数不能被声明为虚函数,因为在对象创建时,编译器需要准确地知道要调用的构造函数。虚函数的特性是在运行时根据对象的实际类型进行动态绑定,而构造函数在对象创建时就需要确定。(对象创建是在编译的时候)
从虚函数表的角度来看:
在构造对象的过程中,首先会调用基类的构造函数来初始化基类的成员变量和执行基类的构造逻辑。只有在基类的构造函数完成后,才会调用派生类的构造函数。
如果构造函数是虚函数,那么在调用派生类的构造函数时,派生类的虚函数表尚未创建。这意味着无法通过虚函数表来调用派生类的虚函数,从而破坏了动态绑定的机制。
此外,构造函数的目的是创建对象并初始化其状态,而不是通过虚函数来实现多态性。构造函数的调用是在对象创建时确定的,不需要动态绑定的机制。
虚构造函数的功能可以通过虚析构函数和工厂模式来实现。工厂模式是一种设计模式,通过基类的静态成员函数或全局函数来创建对象,并返回基类指针或引用。通过这种方式,可以根据实际对象的类型来调用相应的构造函数。
除了构造函数,还有哪些函数不能设置为虚函数?
除了构造函数,还有以下几种情况下的函数不能设置为虚函数:
静态成员函数:静态成员函数属于类本身,而不是类的对象,因此它们不涉及动态绑定的概念,无法被声明为虚函数。
内联函数:内联函数在编译时会被直接插入到调用处,而不是通过函数调用的方式执行。虚函数的调用是通过虚函数表来实现的,无法在编译时确定调用的具体函数,因此无法将内联函数声明为虚函数。(内联函数在编译的时候就寄了)
非成员函数:虚函数是用于实现多态性的成员函数,它们必须属于类的成员。非成员函数无法被声明为虚函数。
什么是菱形继承问题?
菱形继承问题(Diamond Inheritance Problem)是指在多继承中,当一个派生类从两个或多个基类继承,而这些基类又共同继承自同一个基类时,就会形成一个菱形的继承结构。
例如,假设有一个基类Animal,然后有两个派生类:Bird和Fish,它们都直接继承自Animal。接着,有一个派生类Penguin,它同时从Bird和Fish这两个派生类继承。这样就形成了一个菱形继承结构:
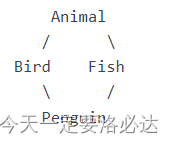
在这个菱形继承结构中,Penguin继承了Bird和Fish的成员变量和成员函数。然而,由于Bird和Fish都继承自Animal,因此Penguin在继承过程中会得到两份Animal的成员变量和成员函数。
这就导致了以下问题:
二义性(Ambiguity):由于Penguin继承了两个Animal的成员,当在Penguin中访问这些成员时,编译器无法确定应该使用哪个Animal的成员,从而导致二义性错误。
冗余(Redundancy):Penguin在继承过程中得到了两份Animal的成员,这种冗余会占用额外的内存空间,造成资源浪费。
为了解决菱形继承问题,C++引入了虚继承(virtual inheritance)机制,通过在继承关系中使用关键字"virtual"来声明虚基类,确保在派生类中只有一个共同的基类子对象,从而避免了二义性和冗余。
讲一下虚继承
虚继承是一种用于解决多继承中的菱形继承问题的机制。在多继承中,如果一个派生类从多个基类继承同一个共同的基类,就会导致菱形继承问题,即派生类中会包含两个或多个相同的基类子对象,这可能引发二义性和冗余的问题。
为了解决这个问题,C++引入了虚继承。虚继承通过在继承关系中使用关键字"virtual"来声明虚基类,从而确保在派生类中只有一个共同的基类子对象。
具体来说,虚继承的特点如下:
虚基类在继承链中只有一个实例:当一个派生类通过虚继承继承一个虚基类时,这个虚基类在整个继承体系中只会有一个实例。
最远派生类负责初始化虚基类:虚基类的构造函数由最远派生类负责调用,确保虚基类只被初始化一次。
虚基类子对象在派生类中的位置由编译器决定:编译器会根据派生类的继承关系和布局规则来决定虚基类子对象在派生类对象中的位置。
虚继承可以有效解决菱形继承问题,避免了二义性和冗余。它在多继承中的应用场景主要是在需要共享基类子对象的情况下,通过虚继承来确保只有一个共享实例。
在派生类中使用virtual关键字来声明虚基类。例如:
class Animal {
public:virtual ~Animal() {}
};class Bird : virtual public Animal {// ...
};class Fish : virtual public Animal {// ...
};
下面是一个示例,演示了虚继承的用法和效果:
#include <iostream>class Animal {
public:Animal() {std::cout << "Animal constructor called." << std::endl;}virtual ~Animal() {std::cout << "Animal destructor called." << std::endl;}
};class Bird : virtual public Animal {
public:Bird() {std::cout << "Bird constructor called." << std::endl;}~Bird() {std::cout << "Bird destructor called." << std::endl;}
};class Fish : virtual public Animal {
public:Fish() {std::cout << "Fish constructor called." << std::endl;}~Fish() {std::cout << "Fish destructor called." << std::endl;}
};class Penguin : public Bird, public Fish {
public:Penguin() {std::cout << "Penguin constructor called." << std::endl;}~Penguin() {std::cout << "Penguin destructor called." << std::endl;}
};int main() {Penguin p;return 0;
}
输出结果:
Animal constructor called.
Bird constructor called.
Fish constructor called.
Penguin constructor called.
Penguin destructor called.
Fish destructor called.
Bird destructor called.
Animal destructor called.
在这个例子中,Animal是虚基类,Bird和Fish都通过虚继承方式继承自Animal。然后,Penguin通过多继承同时继承了Bird和Fish。
由于虚继承的存在,Penguin中只有一个Animal的实例,避免了菱形继承问题。在构造和析构过程中,可以看到Animal的构造和析构只被调用了一次,确保了只有一个Animal实例。
这个例子展示了虚继承的用法和效果,通过使用虚继承,我们可以解决菱形继承问题,避免了二义性和冗余。
讲一下typeid 函数在多态下的用法
typeid 在多态情况下特别有用,因为它可以在运行时确定对象的动态类型,从而进行基类和派生类之间的类型比较。在多态中,基类的指针或引用可以指向派生类的对象,因此我们可以利用 typeid 来判断实际对象的类型。
下面是一个使用多态和 typeid 的简单示例:
#include <iostream>
#include <typeinfo>class Animal {
public:virtual void sound() const {std::cout << "Animal makes a sound." << std::endl;}
};class Dog : public Animal {
public:void sound() const override {std::cout << "Dog barks." << std::endl;}
};class Cat : public Animal {
public:void sound() const override {std::cout << "Cat meows." << std::endl;}
};int main() {Animal* animal1 = new Dog();Animal* animal2 = new Cat();animal1->sound(); // 输出:Dog barks.animal2->sound(); // 输出:Cat meows.if (typeid(*animal1) == typeid(Dog)) {std::cout << "animal1指向的是Dog对象" << std::endl;} else if (typeid(*animal1) == typeid(Cat)) {std::cout << "animal1指向的是Cat对象" << std::endl;}if (typeid(*animal2) == typeid(Dog)) {std::cout << "animal2指向的是Dog对象" << std::endl;} else if (typeid(*animal2) == typeid(Cat)) {std::cout << "animal2指向的是Cat对象" << std::endl;}delete animal1;delete animal2;return 0;
}
在这个示例中,我们有一个基类 Animal 和两个派生类 Dog 和 Cat。通过基类指针 Animal* 来指向不同的派生类对象,我们可以实现多态。然后,使用 typeid 来比较实际对象的类型,我们能够确定这些对象的动态类型。
输出结果将是:
Dog barks.
Cat meows.
animal1指向的是Dog对象
animal2指向的是Cat对象
这个例子展示了 typeid 在多态情况下的使用,它可以帮助我们确定对象的实际类型并进行相应的处理。
使用函数模板有哪两种方式进行类型传递?
C++中使用函数模板时,有两种方式来传递类型信息:自动类型推导和显式指定类型。
1)自动类型推导:
在使用函数模板时,如果不显式指定函数模板的参数类型,编译器会尝试自动推导函数模板参数的类型。这意味着你可以调用函数模板,而无需显式地指定类型,编译器会根据传入的参数类型自动推断并实例化对应的模板函数。
例如:
template <typename T>
T add(T a, T b) {return a + b;
}int result1 = add(3, 5); // 编译器自动推导为add<int>(3, 5)
double result2 = add(1.5, 2.3); // 编译器自动推导为add<double>(1.5, 2.3)
2)显式指定类型:
如果你希望显式指定函数模板的参数类型,可以使用模板名称后面的尖括号来显式地传递类型信息。
例如:
template <typename T>
T multiply(T a, T b) {return a * b;
}int result1 = multiply<int>(3, 5); // 显式指定类型为int
double result2 = multiply<double>(1.5, 2.3); // 显式指定类型为double
无论是自动类型推导还是显式指定类型,函数模板都可以根据传入的参数类型生成对应的函数实例,从而实现对不同类型的支持和通用性。通常情况下,推荐使用自动类型推导,因为它更简洁,代码更具可读性。只有在特定情况下需要强制指定类型时,才会使用显式指定类型的方式。
讲一下普通函数与函数模板在类型转换时的区别
普通函数和函数模板在类型转换时的区别主要在于类型推导和隐式类型转换的处理。
1)普通函数:
普通函数是针对特定类型的函数,其参数类型在编译时已经确定。
普通函数在调用时可以发生自动类型转换(隐式类型转换)。
普通函数可以接受不同类型的参数,并在需要时进行隐式类型转换以匹配参数类型。
示例:
// 普通函数add接受两个int类型的参数,并返回它们的和
int add(int a, int b) {return a + b;
}int main() {int num1 = 3;double num2 = 2.5;int result1 = add(num1, num2); // 隐式类型转换:num2(double)隐式转换为int,结果为5return 0;
}
2)函数模板:
函数模板是一种通用函数,它可以接受不同类型的参数。
如果使用自动类型推导,函数模板不会发生隐式类型转换,因为模板参数类型在编译时已经确定。
如果使用显示指定类型的方式,函数模板调用时可以发生隐式类型转换,因为此时参数类型由程序员明确指定。
示例:
// 函数模板multiply接受两个相同类型的参数,并返回它们的乘积
template <typename T>
T multiply(T a, T b) {return a * b;
}int main() {int num1 = 3;double num2 = 2.5;int result2 = multiply(num1, num2); // 自动类型推导,不发生隐式类型转换,编译错误double result3 = multiply<double>(num1, num2); // 显式指定类型,隐式类型转换:num1(int)隐式转换为double,结果为7.5return 0;
}
在上面的示例中,multiply函数模板接受两个相同类型的参数,并返回它们的乘积。当使用自动类型推导时(multiply(num1, num2)),由于num1是int类型,而num2是double类型,不会发生隐式类型转换,导致编译错误。而当显式指定类型(multiply(num1, num2))时,num1会隐式转换为double类型,然后执行乘法运算,得到结果7.5。
这表明在函数模板中,如果要进行隐式类型转换,需要通过显式指定模板参数的方式来实现。当然,也可以根据实际需求对函数模板进行重载,以支持不同类型的参数和类型转换。
普通函数的自动类型转换是什么?
当调用普通函数时,如果传递的参数类型与函数声明的参数类型不匹配,编译器会尝试进行隐式类型转换以使其匹配。这样可以使函数调用更加灵活,而无需显式地进行类型转换。下面是一个示例:
#include <iostream>// 普通函数add接受两个int类型的参数,并返回它们的和
int add(int a, int b) {return a + b;
}int main() {int num1 = 3;double num2 = 2.5;int result1 = add(num1, num2); // 隐式类型转换:num2(double)隐式转换为int,结果为5std::cout << "result1: " << result1 << std::endl; // 输出: "result1: 5"return 0;
}
在上面的示例中,add函数声明的参数类型是int,但在main函数中传递的第二个参数num2是double类型。由于C++允许隐式类型转换,编译器会将num2的double类型隐式转换为int类型,然后执行加法运算得到结果5。
类模板中成员函数和普通类中成员函数在实例化时机上的区别
1)类模板中的成员函数:类模板中的成员函数并不是在定义类模板时立即生成代码,而是在使用类模板创建对象并调用成员函数时才会根据模板参数进行实例化。这种实例化是在编译器在需要的时候进行的。
2)普通类中的成员函数:普通类中的成员函数在类定义时就已经确定了,无论是否使用这些函数,它们都会在编译时被实例化。
template<class NameType, class AgeType = int> 后面Int是在干啥
在这个类模板的定义中,AgeType 后面的 int 是用于指定 AgeType 类型的默认参数。当使用这个类模板时,如果没有为 AgeType 提供具体的类型参数,编译器会自动使用 int 作为默认类型参数。
类模板对象做函数参数有哪些方式?
1)指定传入的类型:直接显示对象的数据类型。
template<class T>
class MyClass {
public:T data;MyClass(T value) : data(value) {}
};// 传入的类型是 int
void functionWithTypeSpecified(MyClass<int> obj) {// 使用 MyClass<int> 的实例化版本// ...
}int main() {MyClass<int> obj(42);functionWithTypeSpecified(obj);return 0;
}
2)参数模板化:将对象中的参数变为模板进行传递。
template<class T>
class MyClass {
public:T data;MyClass(T value) : data(value) {}
};// 使用模板参数作为函数参数类型
template<class T>
void functionWithParameterTemplate(MyClass<T> obj) {// 使用 MyClass<T> 的实例化版本// ...
}int main() {MyClass<double> obj(3.14);functionWithParameterTemplate(obj);return 0;
}
3)整个类模板化:将这个对象类型模板化进行传递。
template<class T>
class MyClass {
public:T data;MyClass(T value) : data(value) {}
};// 使用函数模板,传入整个类模板
template<class T>
void functionWithClassTemplate(T & p) {// 使用 MyClass<T> 的实例化版本// ...
}int main() {MyClass<std::string> obj("Hello");functionWithClassTemplate(obj);return 0;
}
这些例子展示了不同的传入方式,分别使用了指定传入的类型、参数模板化和整个类模板化来传递类模板对象。每种方式在不同的情况下可能更加方便和合适,取决于具体的需求。