班级网站怎么做ppt模板沈阳市城乡建设网站
BeanFactory是接口,提供了IOC容器最基本的形式,给具体的IOC容器的实现提供了规范。BeanFactory是spring的“心脏”,核心容器,它也是Applicationcontext的父接口。
BeanFactory实质上并未提供过多的方法,spring容器的IOC,依赖注入等功能都由它的子类去实现。
关系类图:
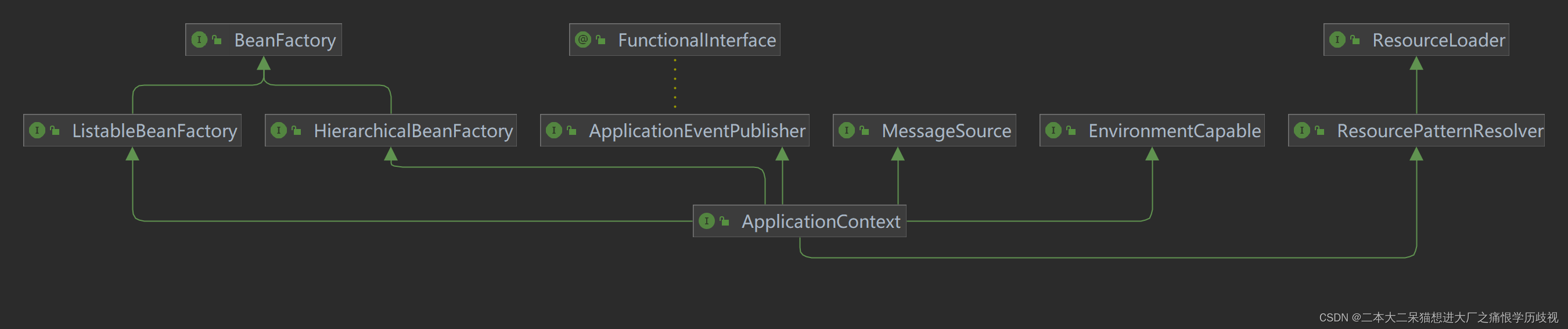
BeanFactory
提供了getBean()方法,其他功能由子类实现
关系类图:
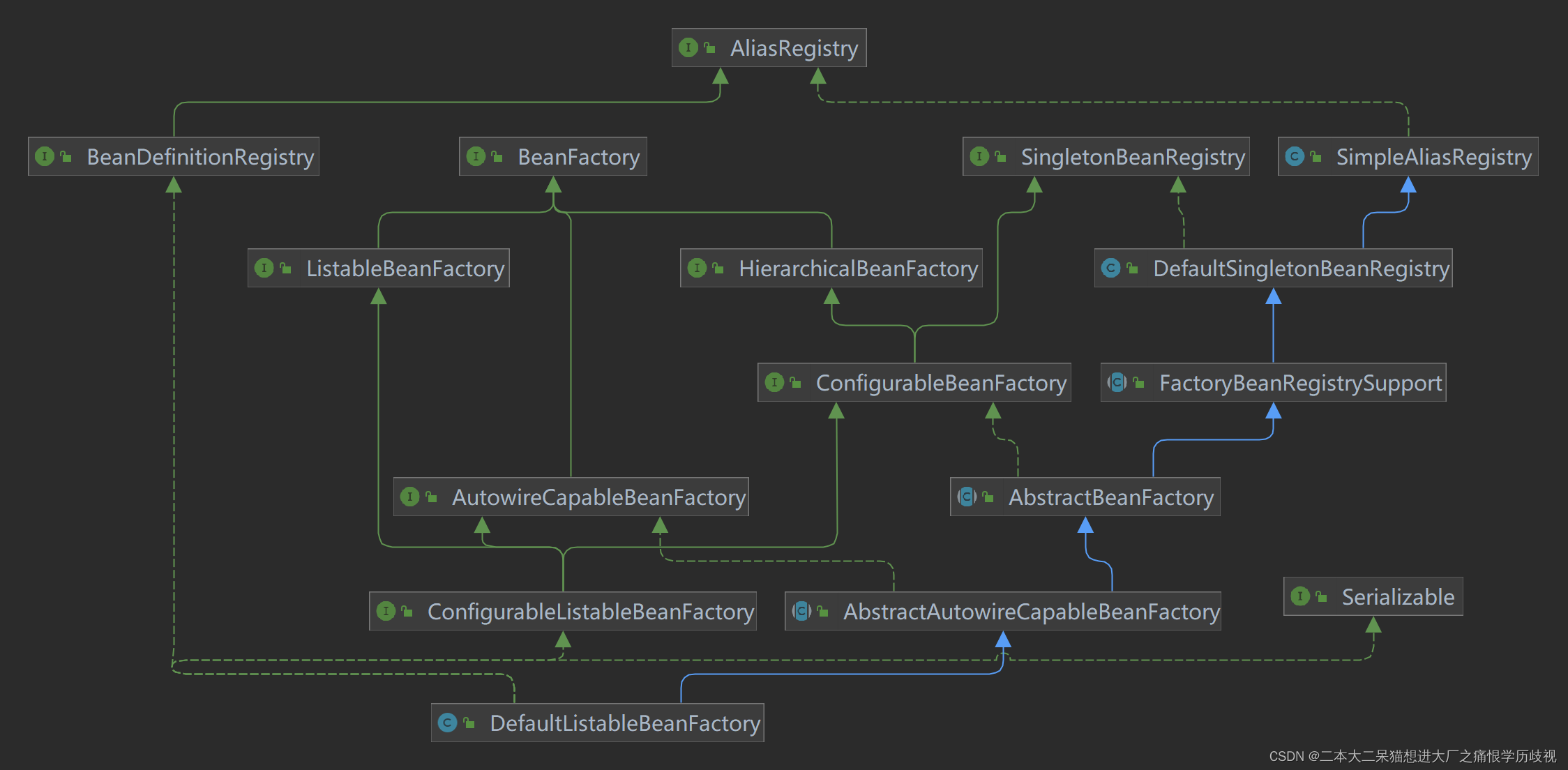
DefaultListableBeanFactory
BeanFactory的重要实现类,其中继承的DefaultSingletonBeanRegistry类存储了一系列作用域为Singleton的Bean。
后处理器
BeanFactory后处理器
BeanFactoryPostProcessor是BeanFactory后处理器,补充添加了一些Bean的定义。
Bean后处理器
可以通过registerAnnotationConfigProcessors()将Bean后处理器添加到Bean工厂里,在通过调用addBeanPostProcessor方法将Bean工厂和后处理器建立起联系。
Bean的后置处理器,一般在Bean的初始化前后执行。Bean实例化之后,填充到单例池singletonObjects之前执行,会进行Bean的初始化。
Applicationcontext
ApplicationEventPublisher
事件发布器,可以发送接收事件,拥有解耦的能力,类似于消息队列(个人觉得)
MessageSource
提供了语言翻译的功能
EnvironmentCapable
获得系统的环境资源环境变量和一些配置文件的信息
ResourcePatternResolver
通过通配符去匹配资源