做研学的企业网站科技资讯网站有哪些
文章目录
- 一、choices参数
- choices参数的用法
- choices 参数用法总结
- 二、MVC与MTV模式
- 1.MVC
- 2.MTV
- 三、多对多的三种创建方式
- 1.全自动创建
- 2.纯手动创建
- 半自动创建
- 四、Django与Ajax
- 1.什么是Ajax
- 常见的场景
- Ajax案例
一、choices参数
在没有用到choices参数之前,我们在Django ORM创建表类中的字段是不是下面这样的
# 举例这是一张用户基本信息表
class UserInfo(models.Model):username = CharField(max_length=32)age = IntegerField() # 整型字段不要传max_length参数哦----特别注意gender = CharField(max_length=2)# 用户性别
通过上面的userinfo表,我们是否可以想一下,在用户性别字段中,人类的性别好像只有两种表示方式,男/女,那这样,我们如果有100万条用户信息,而这100万条用户的性别分别有50万男性和50万女性。
这个时候,就造成了问题,既然我们这个字段的描述信息,只需要两种描述就能完成这个用户字段在性别的描述,我们为什么不想一种方便简洁的形式去描述每一个用户的性别呢?
这时候就可以用到choices参数
我们依然使用数字来记录gender这个用户性别字段的描述,大家学过数据库就知道,能用整型存储的信息,为什么要用字符型呢?很明显,是因为整型比字符型占的空间小。注意:并不是所有的这种仅仅用几个描述就能完成队大量数据的描述,都去用数字的,此处只是用gender字段为例!!
choices参数的概念:它是一种以列表 / 元组的型式,里面嵌套着少数几个小元组的方式,表示一种对应关系
choices参数的用法
针对上述的用户信息表我们做以下修改:将用户性别用整型去记录
# 创建userinfo表
class UserInfo(models.Model):username = models.CharField(max_length=32)age = models.IntegerField()# 在此处我们用到choices参数# 先定义一个chocies参数的对应关系/其是就相当于是代表数字的说明与介绍choices_gender = ((1, '男'),(2, '女'),)# 以上定义的choices列表就是下面gender字段的choices参数对应的一个对应关系,此处choices这个列表,也可以写成元组的形式,根据个人爱好# 在我们将性别字设置成IntegerField类对象的时候,将它的choices参数设置为我们上面定义的choices列表gender = models.IntegerField(max_length=2,choices = choices_gender)
提问:如果我们向这个表中的gender字段存的值不在我们定义的choices列表中会怎么样呢?
# 向表中插入几条数据
models.UserInfo.objects.create(username='jack',age=18,gender=1)
models.UserInfo.objects.create(username='jerry',age=18,gender=2)
models.UserInfo.objects.create(username='tank',age=18,gender=3)

总结:如果存的数字是choices列表中的数字可以存进userinfo表,存的数字不在choices列表中对应关系中,也可以存
# 现在我们来查一下这张表中用户对应的gender字段的值。
user_obj_list = models.UserInfo.objects.all()for user_obj in user_obj_list:print(f'{user_obj.username}---{user_obj.age}---{user_obj.get_gender_display}')
choices 参数用法总结
- 在定义choices这个对应关系的时候,可以用列表套元组,可以用字典套元组,随意,看自己心情
- 自定义的这个对应关系的变量名(choices可以换别的)看你心情
- 在往表中存数据时,不管是不是对应关系中的内容,都可以往表中存
- 在查询使用choces参数的这个字段时,想要查询这个字段的值必须用get_字段名_display()才能获取到正确的对应内容
- 固定句式 数据对象.get_字段名_display() 当没有对应关系的时候 该句式获取到的还是数字
二、MVC与MTV模式
1.MVC
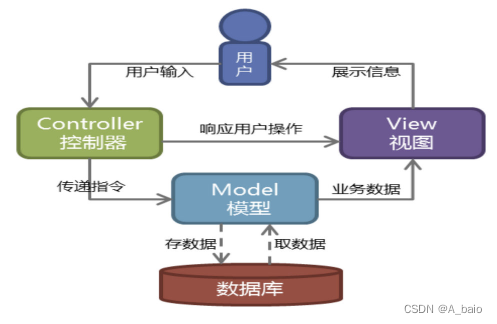
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器©和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示:
2.MTV
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
● M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。
● T 代表模板 (Template):负责如何把页面展示给用户(html)。
● V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示:
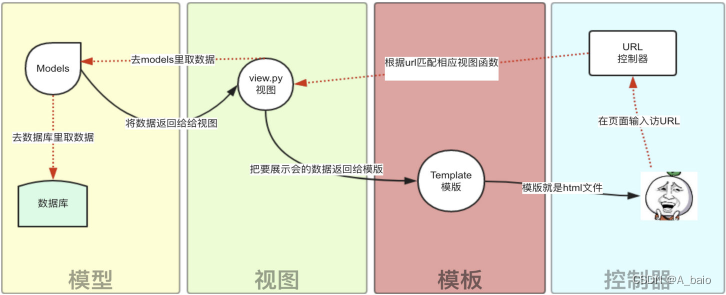
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
三、多对多的三种创建方式
注意:多对多关系这种虚拟外键才有add、set、clear、remove,一对一和一对多的表是无法使用的
1.全自动创建
class Book(models.Model):title = models.CharField(max_length=32)authors=models.ManyToManyField(to='Author')
class Author(models.Model):name = models.CharField(max_length=32)
优势:自动创建第三张表,并且提供了add、remove、set、clear四种操作
劣势:第三张表无法创建更多的字段,扩展性较差。如果我们有一些业务逻辑就是在关系表上,我们就无法通过第三张表完成了。
2.纯手动创建
class Book(models.Model):title = models.CharField(max_length=32)
class Author(models.Model):name = models.CharField(max_length=32)
class Book2Author(models.Model):book=models.ForeignKey(to='Book')author= models.ForeigKey(to='Author')others=models.CharField(max_length=32)join_time = models.DataField(auto_now_add=True)
优势:第三张表完全由自己创建,扩展性强
劣势:编写繁琐,并不支持add、remove、set、clear以及正反向概念
半自动创建
class Book(models.Model):title = models.CharField(max_length=32)authors = models.ManyToManyField(to='Author',through='Book2Author',through_fields=('book','author')# 外键在哪个表就把book表放前面)
class Author(models.Model):name = models.CharField(max_length=32)
class Book2Author(models.Model):book = models.ForeignKey(to='Book', on_delete=models.CASCADE)author = models.ForeignKey(to='Author', on_delete=models.CASCADE)others = models.CharField(max_length=32)join_time = models.DateField(auto_now_add=True)
优势:第三张表完全由自己创建的,扩展性强,正反向概念依然可以使用
劣势:编写繁琐不再支持add、remove、set、clear
四、Django与Ajax
1.什么是Ajax
AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步的Javascript和XML”。即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML)。ajax不是一门新的技术,而是一种使用现有标准的新方法。它本身又很多版本,我们目前学习的是jQuery版本(版本无所谓,本质一样就可以)。
功能介绍:异步提交、局部刷新
优点:
不重新加载整个页面的情况下,可以跟服务器交换数据并更新部分网页内容。(客户是感觉不到的),只需要用户允许JavaScript在浏览器上执行。
1.AJAX使用JavaScript技术向服务器发送异步请求;
2.AJAX请求无需刷新整个页面
3.因为服务器响应内容不再是整个页面,而是页面中的部分内容,所以AJAX性能高;
4.两个关键点:异步请求,局部刷新
常见的场景
搜索引擎会根据用户输入的关键字,自动提示检索关键字。其实这里就使用了AJAX技术!当文件框发生了输入变化时,使用AJAX技术向服务器发送一个请求,然后服务器会把查询到的结果响应给浏览器,最后再把后端返回的结果展示出来。
这注册过程页面时没有刷新的,只是刷新页面中我们鼠标点击的局部位置,当请求发出后,浏览器还可以进行其他操作,无需等待服务器的响应。
Ajax案例
我们来做一个计算的例子
ajax.html
<body>
<input type="text" id="inp1">+
<input type="text" id="inp2">=
<input type="text" id="inp3">
<button class="btn">提交</button><script>$('.btn').click(function () { //把提交按钮绑定一个点击事件var inp1 = $("#inp1").val();var inp2 = $("#inp2").val();//把获取到的两个值提交到后端,让python来计算两个值,然后返回$.ajax({url: "", //默认不写是当前地址type: 'post', //提交方式,默认是getdata: {inp1: inp1, inp2: inp2}, //朝后端提交的数据,KV键值对形式//回调函数success用来接受后端返回的数据success:function (res){console.log(res) //打印后端返回的数据$('#inp3').val(res) //将接受到的数据返回到inp3中}})})
</script>
</body>
views.py
from django.shortcuts import render, HttpResponse
import json# Create your views here.def ajax(request):if request.method == 'POST':'''接受ajax提交过来的数据'''d1 = request.POST.get('inp1')d2 = request.POST.get('inp2')d3 = int(d1) + int(d2) # 转为整型,计算值print(request.POST) # <QueryDict: {'inp1': ['1'], 'inp2': ['1']}>return HttpResponse(json.dumps(d3)) # 序列化并返回给前端return render(request, 'ajax.html')
这个时候需要拿到后端字典里的数据要怎么做
ajax.html
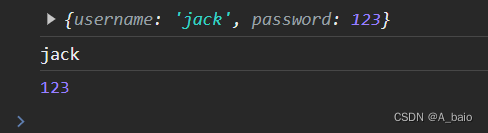
<script>$('.btn').click(function () { //把提交按钮绑定一个点击事件var inp1 = $("#inp1").val();var inp2 = $("#inp2").val();//把获取到的两个值提交到后端,让python来计算两个值,然后返回$.ajax({url: "", //默认不写是当前地址type: 'post', //提交方式,默认是getdata: {inp1: inp1, inp2: inp2}, //朝后端提交的数据,KV键值对形式//回调函数success用来接受后端返回的数据success:function (res){console.log(res) //打印后端返回的数据{#res=JSON.parse(res) //反序列化json格式数据,如果后端是用JsonResponse返回数据就不需要前端反序列化#}console.log(res.username)console.log(res.password) //前度想要拿到某个值就需要反序列化,后端别忘了序列化}})})
</script>
views.py
from django.shortcuts import render, HttpResponse
import json
from django.http import JsonResponse# Create your views here.def ajax(request):if request.method == 'POST':'''接受ajax提交过来的数据'''user_dic = {'username':'jack','password':123}return JsonResponse(user_dic) # 序列化并返回给前端return render(request, 'ajax.html')