中国门户网站有哪些网站制作软件下载安装
Selenium 介绍
概述
Selenium是一款功能强大的自动化Web浏览器交互工具。它可以模拟真实用户在网页上的操作,例如点击、滚动、输入等等。Selenium可以爬取其他库难以爬取的网站,特别是那些需要登录或使用JavaScript的网站。Selenium可以自动地从Web页面中提取数据,例如价格、评论、评分等等。Selenium是一款非常实用的工具,可以帮助用户更好地利用Web技术,提高工作效率和数据质量。
优点
- 强大的自动化Web浏览器交互工具
- 可用于爬取其他框架难以爬取的网站
- 多浏览器支持:FireFox、Chrome、IE、Opera、Edge;
- 多平台支持:Linux、Windows、MAC;
- 多语言支持:Java、Python、Ruby、C#、JavaScript、C++;
缺点
- 使用起来可能比较复杂
- 不如某些其他框架快速
适用场景
- 爬取其他框架难以爬取的网站
- 爬取大量数据
和jsoup比较
jsoup很大程度是处理一些静态的网页,而Selenium很大程度上用作复杂动态交互的网页
Selenium 使用步骤
1:下载浏览器和驱动-以eage为例
因为使用Selenium 需要安装谷歌浏览器,以及程序中使用的驱动包。并且这两个必须保持版本一致;
chrome驱动包下载地址:
http://chromedriver.storage.googleapis.com/index.html
或者
https://registry.npmmirror.com/binary.html?path=chromedriver/
Edge浏览器驱动:
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Firefox浏览器驱动:
https://github.com/mozilla/geckodriver/releases
1:查看eage浏览器版本:

2:下载对应驱动包-确保版本一致
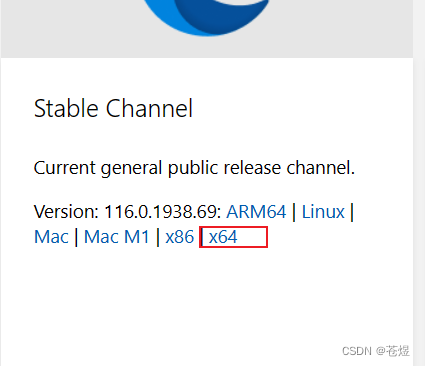
3:设置驱动,以下三种选项
3-1:将eage驱动包放入jdk的bin文件夹中
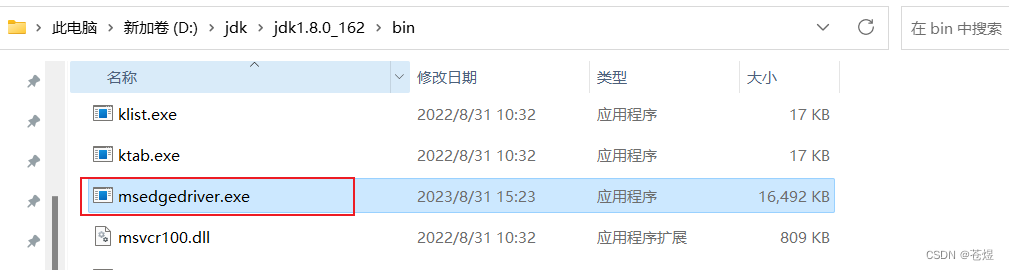
3-2:设置浏览器驱动
设置浏览器的地址非常简单。 我们可以手动创建一个存放浏览器驱动的目录,如: D:\tools\HuanjingVariable\chromedriver , 将下载的浏览器驱动文件(例如:chromedriver、geckodriver)丢到该目录下。
我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path,将“D:\tools\HuanjingVariable\chromedriver”目录添加到Path的值中。
3-3:环境变量没设置好可以指定磁盘地址去访问浏览器驱动
//设置系统属性指定谷歌驱动地址
System.setProperty("webdriver.chrome.driver", "D:/tools/HuanjingVariable/chromedriver/chromedriver.exe");2:导包
<!-- selenium 依赖 --><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.5.0</version></dependency>
3:简单示例
案例:打开百度页面,输入“java” 然后打印出页面的文本信息
package com.example.seleniumdemo;import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.edge.EdgeDriver;
import org.openqa.selenium.edge.EdgeOptions;public class EageMain {public static void main(String[] args) {//引入eage驱动EdgeOptions options = new EdgeOptions();//允许所有请求options.addArguments("--remote-allow-origins=*");EdgeDriver driver = new EdgeDriver(options);//打开网页driver.get("http://www.baidu.com");//输入框中输入搜索词driver.findElement(By.id("kw")).sendKeys("java");//点击百度一下按钮driver.findElement(By.id("su")).click();//获取元素文本信息String data = driver.findElement(By.className("s_tab_inner_81iSw")).getText();System.out.println(data);}}Selenium API
1:定位元素-得到WebElement 对象
| 方法 | 描述 | 参数 | 示例 |
|---|---|---|---|
| findElement(By.id()) | 通过元素的 id 属性值来定位元素 | 通过元素标签对之间的部分文本信息来定位元素 | findElement(By.id(“kw”)) |
| findElement(By.name()) | 通过元素的 id 属性值来定位元素 | 通过元素标签对之间的部分文本信息来定位元素 | findElement(By.name(“user”)) |
| findElement(By.className()) | 通过元素的 class 名来定位元素 | 对应的class类名 | findElement(By.className(“passworld”)) |
| findElement(By.tagName()) | 通过元素的 class 名来定位元素 | 对应的class类名 | findElement(By.className(“passworld”)) |
| findElement(By.linkText()) | 通过元素的 class 名来定位元素 | 文本内容 | findElement(By.linkText(“登录”)) |
| findElement(By.partialLinkText()) | 通过元素标签对之间的部分文本信息来定位元素 | 部分文本内容 | findElement(By.partialLinkText(“百度”)) |
| findElement(By.xpath()) | 通过元素标签对之间的部分文本信息来定位元素 | xpath表达式 | findElement(By.xpath(“//input[@id=‘kw’]”)) |
| findElement(By.cssSelector()) | 通过元素标签对之间的部分文本信息来定位元素 | css元素选择器 | findElement(By.cssSelector(“#kw”)) |
2:WebDriver 常用 API
WebDriver 提供了一系列的 API 来和浏览器进行交互
| 方法 | 描述 |
|---|---|
| get(String url) | 访问目标 url 地址,打开网页 |
| getCurrentUrl() | 获取当前页面 url 地址 |
| getTitle() | 获取页面标题 |
| getPageSource() | 获取页面源代码 |
| close() | 关闭浏览器当前打开的窗口 |
| quit() | 关闭浏览器所有的窗口 |
| findElement(by) | 查找单个元素 |
| findElements(by) | 查到元素列表,返回一个集合 |
| getWindowHandle() | 获取当前窗口句柄 |
| getWindowHandles() | 获取所有窗口的句柄 |
3:WebElement 常用 API
通过 WebElement 实现与网站页面上元素的交互,这些元素包含文本框、文本域、按钮、单选框、div等,WebElement提供了一系列的方法对这些元素进行操作
| click() | 对元素进行点击 |
|---|---|
| clear() | 清空内容(如文本框内容) |
| sendKeys(…) | 写入内容与模拟按键操作 |
| isDisplayed() | 元素是否可见(true:可见,false:不可见) |
| isEnabled() | 元素是否启用 |
| isSelected() | 元素是否已选择 |
| getTagName() | 获取元素标签名 |
| getAttribute(attributeName) | 获取元素对应的属性值 |
| getText() | 获取元素文本值(元素可见状态下才能获取到,isDisplayed为false的元素得到的值为空) |
| submit() | 表单提交 |
4:元素等待机制
在对元素进行定位时,有时候网页加载时间比较长,元素还没有加载出来,这个时候去查找这个元素的话程序中就会抛出异常,所以我们在编写代码时需要考虑延时问题,在selenium中有几种延时机制可以使用如下:
1.硬性等待
硬性等待就是不管你浏览器元素是否加载完成,都要进行等待设置好的时间,利用 java 语言中的线程类 Thread 中的 sleep 方法,进行强制等待。
Thread.sleep(long millis) 该方法会让线程进行休眠。
如:Thread.sleep(3000) 表示程序执行的线程暂停 3 秒钟。
这种方法在一定的程度上是可以解决元素加载过慢的情况,但是不建议使用该方法,因为一般情况下我们无法判断网页到底需要多长时间加载完成,如果我们设置的时间过长,非常影响效率。
2.隐式等待
隐式等待的理解,就是我们通过代码设置一个等待时间,如果在这个等待时间内,网页加载完成后就执行下一步,否则一直等待到时间截止。
代码表示:
driver.manage.timeouts.implicitlyWait(long time, TimeUtil unit);
这种方法相对于硬性等待显的会灵活一点,但是隐式等待也有个弊端,因为这个设置是全局的,程序需要等待整个页面加载完成,直到超时,有时候我需要找的那个元素早就加载完成了,只是页面上有个别其他元素加载比较慢,程序还是会一直等待下去。直到所有的元素加载完成在执行下一步。
3.显式等待
显示等待是等待指定元素设置的等待时间,在设置时间内,默认每隔0.5s检测一次当前的页面这个元素是否存在,如果在规定的时间内找到了元素则执行相关操作,如果超过设置时间检测不到则抛出异常。默认抛出异常为:NoSuchElementException。推荐使用显示等待。
代码表示:
WebDriberWait wait = new WebDriverWait(dirver, timeOutInSeconds);
wait.nutil(expectCondition);
具体使用案例:
1.查找元素是否已经加载出来
WebDriverWait wait = new WebDriverWait(driver, 5);
// 查找id为“kw"的元素是否加载出来了(已经在页面DOM中存在)
wait.until(ExpectedConditions.presenceOfElementLocated(By.id("kw")));// 在设定时间内找到后就返回,超时直接抛异常
2.查找元素是否可见
WebDriverWait wait = new WebDriverWait(driver, 5);
// 查找id为"kw"的元素是否可见
wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("kw")));
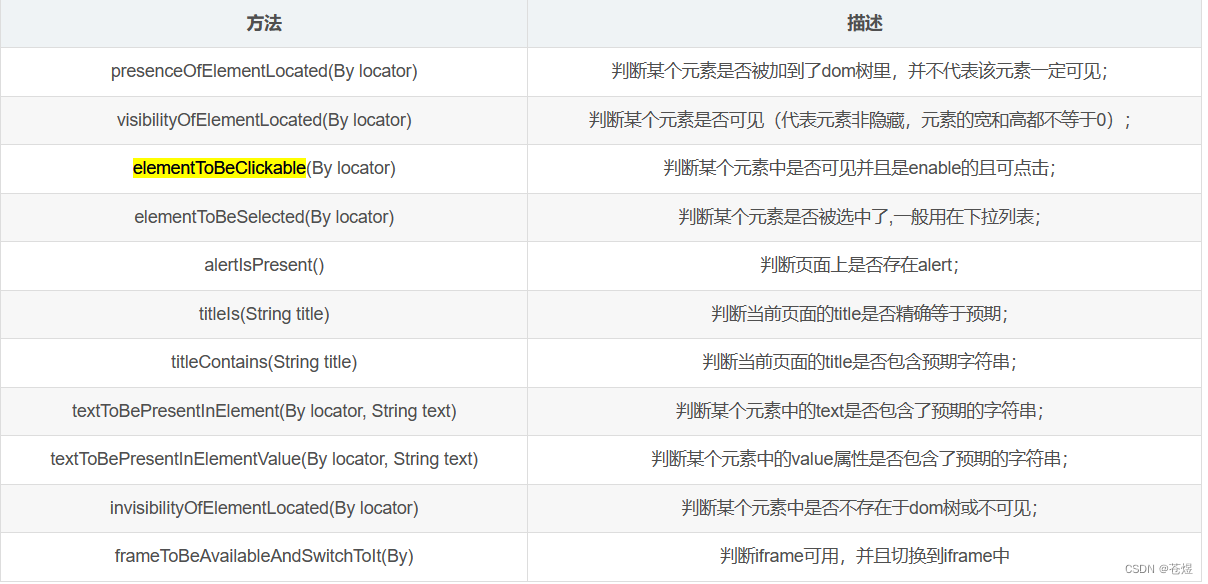
4. ExpectedConditions类中常用方法
5. 页面加载超时设置
通过TimeOuts 对象进行全局页面加载超时的设置,该设置必须放置get 方法之前。如下代码:
driver.manage().timeouts().pageLoadTimeout(5, TimeUnit.SECONDS);
driver.get("https://www.baidu.com");
5:模拟鼠标键盘操作
1:模拟鼠标
在WebDriver中,关于鼠标的操作我们可以通过 Actions 类来模拟鼠标右击、双击、悬停、拖动等操作。
Actions 类中鼠标操作常用方法:
| 方法 | 描述 |
|---|---|
| contextClick() | 鼠标右击 |
| clickAndHold(WebElement) | 点击并控制(模拟悬停) |
| doubleClick(WebElement) | 鼠标双击 |
| dragAndDrop(webElement1,webElement2) | 鼠标拖动 |
| moveToElement(WebElement) | 鼠标移动到某个元素上 |
| perform() | 执行所有Actions中存储的行为 |
| click() | 鼠标单击(左击) |
示例:百度首页设置悬停下拉菜单
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.interactions.Actions;public class MouseDemo {public static void main(String[] args) {WebDriver driver = new ChromeDriver();driver.get("https://www.baidu.com/");// 定位元素WebElement search_setting = driver.findElement(By.linkText("设置"));// 创建actions对象Actions action = new Actions(driver);// 模拟鼠标悬停action.clickAndHold(search_setting).perform();driver.quit();}
}2: 模拟键盘
在 selenium 中有个 Keys() 类(枚举类),提供了几乎键盘上所有按键的方法,在使用的过程中,我们可以通过 sendKeys() 方法来模拟键盘的输入,除此之外,我们还可以用它来输入键盘上的按键, 甚至是组合键, 如 Ctrl+A、 Ctrl+C 等。
-
sendKeys(Keys.BACK_SPACE) 回格键(BackSpace)
-
sendKeys(Keys.SPACE) 空格键 (Space)
-
sendKeys(Keys.TAB) 制表键 (Tab)
-
sendKeys(Keys.ESCAPE) 回退键(Esc)
-
sendKeys(Keys.ENTER) 回车键(Enter)
-
sendKeys(Keys.CONTROL,‘a’) 全选(Ctrl+A)
-
sendKeys(Keys.CONTROL,‘c’) 复制(Ctrl+C)
-
sendKeys(Keys.CONTROL,‘x’) 剪切(Ctrl+X)
-
sendKeys(Keys.CONTROL,‘v’) 粘贴(Ctrl+V)
-
sendKeys(Keys.F1) 键盘 F1
…… -
sendKeys(Keys.F12) 键盘 F12
import org.openqa.selenium.WebElement;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;public class Keyboard {public static void main(String[] args)throws InterruptedException {WebDriver driver = new ChromeDriver();driver.get("https://www.baidu.com");// 定位到对应的元素WebElement input = driver.findElement(By.id("kw"));//输入框输入内容input.sendKeys("seleniumm");Thread.sleep(2000);//删除多输入的一个 minput.sendKeys(Keys.BACK_SPACE);Thread.sleep(2000);//输入空格键+“教程”input.sendKeys(Keys.SPACE);input.sendKeys("教程");Thread.sleep(2000);//ctrl+a 全选输入框内容input.sendKeys(Keys.CONTROL,"a");Thread.sleep(2000);//ctrl+x 剪切输入框内容input.sendKeys(Keys.CONTROL,"x");Thread.sleep(2000);//ctrl+v 粘贴内容到输入框input.sendKeys(Keys.CONTROL,"v");Thread.sleep(2000);//通过回车键盘来代替点击操作input.sendKeys(Keys.ENTER);Thread.sleep(2000);driver.quit();}
}6:控制浏览器操作
浏览器窗口操作
WebDriver 给我们提供了一个 Window 对象,专门用于对窗口的设置。
对象获取方法:
Window window = driver.manage().window();
Window 对象的方法有:
| 方法 | 描述 |
|---|---|
| window.maximize() | 将浏览器窗口最大化。 |
| window.getPosition() | 获取窗口的位置,返回 Point 对象,包含浏览器左上角的坐标位置。通过point.x 和point.y 来获取到。 |
| window.setPosition(Point) | 指定浏览器窗口左上角的坐标位置,创建一个Point 对象,设置对象的 x 和 y 坐标即可。 |
| window.getSize() | 获取窗口尺寸(宽和高),返回一个 Dimension 对象,通过该对象调用 getHeight() 和 getWidth() 来获取 高度和宽度。 |
| window.setSize(Dimension) | 设置窗口大小,创建一个 Dimension 对象,设置对象的高度和宽度。 |
浏览器导航操作
WebDriver 提供了 Navigation 对象来对浏览器进行导航操作,如:前进、后退、刷新等。
Navigation 对象获取:
Navigation navigate = driver.navigate();
Navigation 对象提供的方法:
| 方法 | 描述 |
|---|---|
| navigate.to(url) | 跳转到指定url,和 webdriver 使用 get 方法是一样的。 |
| navigate.refresh() | 刷新当前页面。 |
| navigate.back() | 浏览器回退操作。 |
| navigate.forward() | 浏览器前进操作。 |
7:弹出框/警告框处理
操作alert、confirm弹出框,可以通过Alert 对象来进行操作,Alert类包含了确认、取消、输入和获取弹出窗内容。
Alert对应属性和方法:

// 首先需要切换到弹出框中,获取Alert对象。
Alert alert = driver.switchTo().alert();
// 获取弹窗文本内容
alert.getText();
// 点击确定按钮
alert.accept();
// 点击取消按钮
alert.dismiss();注:如果弹出框不是 js 原生的 alert 弹窗,我们还是按照原来的获取元素的方法。
8:iframe 切换/多表单切换
有时候我们定位元素的时候,发现怎么都定位不了。 这时候你需要查一查你要定位的元素是否在iframe里面。
什么是iframe?
iframe 就是HTML 中,用于网页嵌套网页的。 一个网页可以嵌套到另一个网页中,可以嵌套很多层。
例如:
main.html
<html>
<head><title>FrameTest</title>
</head>
<body><div id="id1">this is main page's div!</div><input type="text" id="maininput" /><br/><iframe id="frameA" frameborder="0" scrolling="no" style="left:0;position:absolute;" src="frame.html"></iframe>
</body>
</html>frame.html
<html>
<head><title>this is a frame!</title>
</head>
<body><div id="div1">this is iframes div,</div><input id="iframeinput"></input>
</body>
</html>使用selenium 操作浏览器时,如果需要操作iframe中的元素,首先需要切换到对应的内联框架中。
selenium 给我们提供了三个重载的方法,进行操作iframe;
// 方法一:通过 iframe的索引值,在页面中的位置
driver.switchTo().frame(index);
// 方法二:通过 iframe 的name 或者id
driver.switchTo().frame(nameOrId);
// 方法三:通过iframe 对应的webElement
driver.switchTo().frame(frameElement);
代码:
public static void testIframe(WebDriver driver){// 在 主窗口的时候driver.findElement(By.id("maininput")).sendKeys("main input");// 此时 没有进入到iframe, 以下语句会报错//driver.findElement(By.id("iframeinput")).sendKeys("iframe input");driver.switchTo().frame("frameA");driver.findElement(By.id("iframeinput")).sendKeys("iframe input");// 此时没有在主窗口,下面语句会报错//driver.findElement(By.id("maininput")).sendKeys("main input");// 回到主窗口driver.switchTo().defaultContent();driver.findElement(By.id("maininput")).sendKeys("main input");
}注:如果已经切换进入了其中的一个 iframe 中,再想对 iframe 外的元素进行操作,需要切换回到默认的页面中,否则会找不到元素。
// 切换到默认内容页面
driver.switchTo().defaultContent();9:浏览器窗口的切换/多窗口切换
有时候后在操作浏览器,可能打开了一个新的窗口,这个时候如果要对新窗口的元素进行操作,需要切换到新窗口中去,怎么去切换呢?在 selenium 中有个叫句柄的概念。
什么是句柄,简单理解就是浏览器窗口的一个标识,浏览器打开的每个窗口都有唯一的一个标识,也就是句柄,我们可以通过句柄来进行窗口之间的切换,从而来达到我们操作不同窗口的元素。
WebDriver 中提供了两个 API 来获取窗口的相关句柄:
// 获取当前窗口的句柄
String handle = driver.getWindowHandle();
// 获取所有窗口的句柄,返回一个集合
Set<String> handles = driver.getWindowHandles();获取到句柄后,通过对应的方法进行切换:
// 切换到窗口
driver.switchTo.windwo(String handle);
示例代码:
/**
* 切换窗口的方法
* 通过传入一个标题来找到我们需要的窗口。
* @param title 窗口的标题
*/
public void switchWindow(String title){Set<String> handles = driver.getWindowHandles();// 切换窗口的方式--循环遍历handles集合for (String handle : handles) {//判断是哪一个页面的句柄??--根据什么来判断???titleif(driver.getTitle().equals(title)){break;}else{//切换窗口--根据窗口标识来切换driver.switchTo().window(handle);}
}10:select 下拉框处理
如果一个页面元素是一个下拉框(select),对应下拉框的操作,selenium有专门的类 Select 进行处理。其中包含了单选和多选下拉框的各种操作,如获得所有的选项、选择某一项、取消选中某一项、是否是多选下拉框等。
Select类常用的一些方法:
| 方法 | 说明 |
|---|---|
| void deselectAll() | 取消所有选择项,仅对下拉框的多选模式有效,若下拉不支持多选模式,则会抛出异常 UnsupportedOperationException(不支持的操作) |
| void deselectByIndex(int index) | 取消指定index的选择,index从零开始,仅对多选模式有效,否则抛出异常 UnsupportedOperationException(不支持的操作) |
| void deselectByValue(String value) | 取消Select标签中,value为指定值的选择,仅对多选模式有效,否则抛出异常 UnsupportedOperationException(不支持的操作) |
| void deselectByVisibleText(String Text) | 取消项的文字为指定值的项,例如指定值为Bar,项的html为,仅对多选模式有效,单选模式无效,但不会抛出异常 |
| ListgetAllSelectedOptions() | 获得所有选中项,单选多选模式均有效,但没有一个被选中时,返回空列表,不会抛出异常 |
| WebElement getFirstSelectedOption() | 获得第一个被选中的项,单选多选模式均有效,当多选模式下,没有一个被选中时,会抛出NoSuchElementException异常 |
| ListgetOptions() | 获得下拉框的所有项,单选多选模式均有效,当下拉框没有任何项时,返回空列表,不会抛出异常 |
| boolean isMultiple() | 判断下拉框是否多选模式 |
| void selectByIndex(int index) | 选中指定index的项,单选多选均有效,当index超出范围时,抛出NoSuchElementException异常 |
| void selectByValue(String value) | 选中所有Select标签中,value为指定值的所有项,单选多选均有效,当没有适合的项时,抛出NoSuchElementException异常 |
| void selectByVisibleText(String text) | 选中所有项的文字为指定值的项,与deselectByValue相反,但单选多选模式均有效,当没有适合的项时,抛出NoSuchElementException异常 |
示例代码:
// 创建驱动WebDriver driver = new ChromeDriver();// 打开2345网站driver.get("https://www.2345.com");// 切换城市driver.findElement(By.linkText("切换")).click();// 切换到iframe内联框架中driver.switchTo().frame("city_set_ifr");// 定位到省份下拉框WebElement province = driver.findElement(By.id("province"));province.click();// 创建Select对象Select select = new Select(province);// 根据文本来获取下拉值select.selectByVisibleText("B 北京");driver.quit();11:日期控件操作
对于页面中出现时间控件选择时,一般分为两种:
(1)控件没有限制手动填写的,我们直接使用 sendKeys() 方法进行赋值即可。
Copydriver.findElement(By).sendKeys("2020-03-30");
(2)控件限制了手动输入的,只能通过点击控件时间进行输入的,我们就需要使用 js 脚本进行操作了。
Copy// 获取js执行器
JavaScriptExecutor js = (JavaScriptExecutor)driver;
// 对时间输入框进入赋值
String script = "document.getElementById('xxx').value='2020-03-30';";
// 执行
js.executeScript(script);注:需要注意的是,不管使用哪种方式进行时间的赋值,一点要注意输入时间的格式是否符合系统的要求;
12:文件上传
对于通过input标签实现的上传功能,可以将其看作是一个输入框,即通过sendKeys()指定本地文件路径的方式实现文件上传。
创建upfile.html文件,代码如下:
接下来通过sendKeys()方法来实现文件上传。
import java.io.File;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;public class UpFileDemo {public static void main(String[] args) throws InterruptedException {WebDriver driver = new ChromeDriver();File file = new File("./HTMLFile/upfile.html");String filePath = file.getAbsolutePath();driver.get(filePath);//定位上传按钮, 添加本地文件driver.findElement(By.name("file")).sendKeys("D:\\upload_file.txt");Thread.sleep(5000);driver.quit();}
}13:调用js
虽然WebDriver提供了操作浏览器的前进和后退方法,但对于浏览器滚动条并没有提供相应的操作方法。在这种情况下,就可以借助JavaScript来控制浏览器的滚动条。WebDriver提供了executeScript()方法来执行JavaScript代码。
用于调整浏览器滚动条位置的JavaScript代码如下:
<!-- window.scrollTo(左边距,上边距); -->
window.scrollTo(0,450);
window.scrollTo() 方法用于设置浏览器窗口滚动条的水平和垂直位置。方法的第一个参数表示水平的左间距,第二个参数表示垂直的上边距。其代码如下:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.Dimension;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.JavascriptExecutor;public class JSDemo {public static void main(String[] args) throws InterruptedException{WebDriver driver = new ChromeDriver();//设置浏览器窗口大小driver.manage().window().setSize(new Dimension(700, 600));driver.get("https://www.baidu.com");//进行百度搜索driver.findElement(By.id("kw")).sendKeys("webdriver api");driver.findElement(By.id("su")).click();Thread.sleep(2000);//将页面滚动条拖到底部((JavascriptExecutor)driver).executeScript("window.scrollTo(100,450);");Thread.sleep(3000);driver.quit();}
}通过浏览器打开百度进行搜索,并且提前通过 window().setSize() 方法将浏览器窗口设置为固定宽高显示,目的是让窗口出现水平和垂直滚动条。然后通过 executeScript() 方法执行JavaScripts代码来移动滚动条的位置。
将滚动条滚动到某个区域后停止(页面元素全部加载完成),如下:
//滚动到某一区域
//scrollIntoView(0); 让元素滚动到可视区域的最下方
//scrollIntoView(); 让元素滚动到可视区域的最上方
//JavascriptExecutor javascriptExecutor = (JavascriptExecutor)BrowserUtil.driver;
//javascriptExecutor.executeScript("document.getElementById('index_ads').scrollIntoView(0);");
//JavaScript的参数传递-selenium和js的交互
//1、先去找到这个元素
WebElement webElement = driver.findElement(By.xpath("element"));
//2、找到的元素作为参数传入到Js代码中
JavascriptExecutor javascriptExecutor = (JavascriptExecutor)driver;
javascriptExecutor.executeScript("arguments[0].scrollIntoView(0)",webElement);页面元素是通过懒加载方式,需要一直进行滚动的
/**
* 滑动列表找元素并且进行点击(懒加载)
* @param selectedText 选中元素文本
* @param by 正在加载类似元素的定位表达式
*/
public static void clickElementInList(String selectedText, By by) {// 滑动之前的页面源代码信息String beforeSource = "";// 滑动之后的页面源代码信息String afterSource = "";// 循环条件// 1、找到了元素,跳出循环// 2、如果没有找到元素???怎么跳出循环while (true) {WebElement webElement = driver.findElement(by);// 获取页面源代码beforeSource = driver.getPageSource();// 获取js执行器JavascriptExecutor javascriptExecutor = (JavascriptExecutor)driver;// 执行jsjavascriptExecutor.executeScript("arguments[0].scrollIntoView(0);", webElement);// 如果当前页面有想要的元素,怎么判断是否有??--getPageSourceif (driver.getPageSource().contains(selectedText)) {driver.findElement(By.linkText(selectedText)).click();// 找到元素退出循环,不再滚动。break;}afterSource = driver.getPageSource();// 页面元素没有变化---滑动到了最底部if (afterSource.equals(beforeSource)) {// 到达底部,退出。break;}}
}Selenium 常见问题
1.css选择器和xpath选择器你觉得哪个更好?
答:css选择器效率更高
2.quit 和 close的区别
quit 关闭了整个浏览器,close只是关闭了当前的页面;
quit会清空缓存,close则不会
3:在springboot中Selenium 版本变为了3.141.59
在maven中查看依赖:
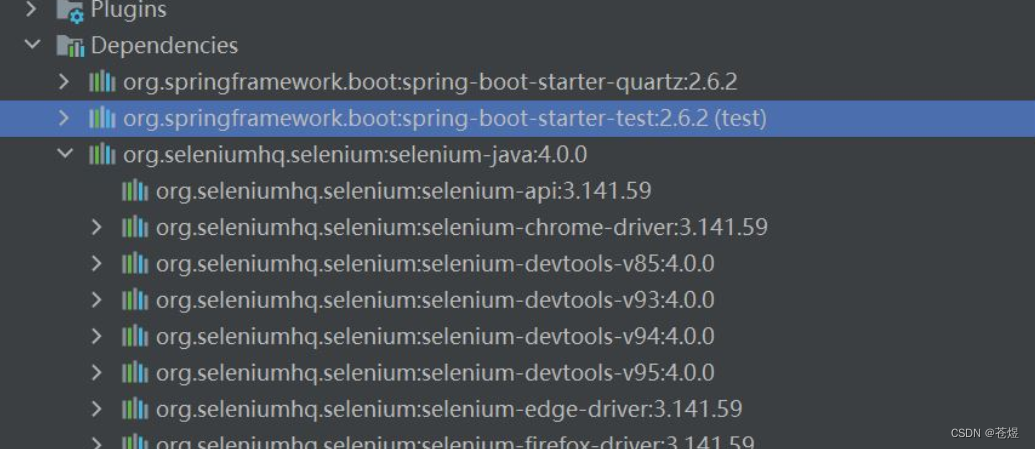
分析原因:
在引用的spring-boot-starter-parent -> spring-boot-dependencies的pom文件依赖中看到:
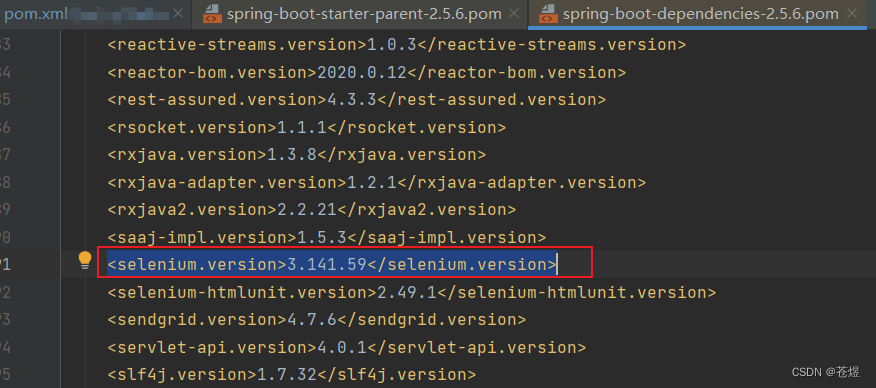
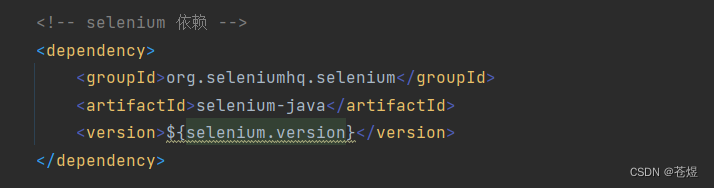
看来是spring-boot-dependencies的版本覆盖了我们的版本,那么让自己的坐标覆盖默认的坐标

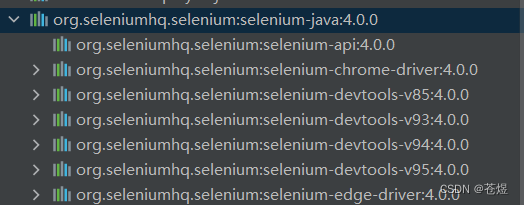
改动后,发现正常了:
4:使用edge驱动报错

应该增加EdgeOptions配置
public static void main(String[] args) {//引入eage驱动System.setProperty("webdriver.edge.driver", "D:\\driver\\msedgedriver.exe");EdgeOptions options = new EdgeOptions();
// //允许所有请求options.addArguments("--remote-allow-origins=*");EdgeDriver driver = new EdgeDriver(options);
// EdgeDriver driver = new EdgeDriver();//打开网页driver.get("http://www.baidu.com");//输入框中输入搜索词driver.findElement(By.id("kw")).sendKeys("java");//点击百度一下按钮driver.findElement(By.id("su")).click();//获取元素文本信息String data = driver.findElement(By.className("s_tab_inner_81iSw")).getText();System.out.println(data);}