自学网站建设需要什么学历wordpress安装到子目录下
上门服务其实就是本地生活服务的升级,上门服务包含很多行业可以做的。例如:厨师上门、上门家电维修、跑腿等等。如今各类本地化生活服务越来越受大家的喜爱。基于此市场愿景,我们来谈谈上门服务系统功能。
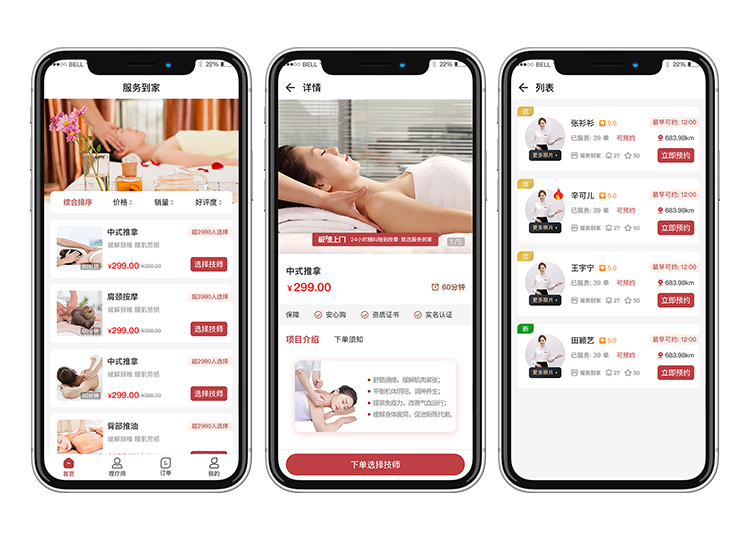
一、上门服务系统功能
1、预约服务:用户可以在平台上选择需要的服务项目,并预约服务时间。
2、上门安装:平台派遣专业的技术人员上门安装服务。
3、维修保养:提供家电、设备等维修保养服务。
4、订单管理:平台对用户订单进行统一管理,方便用户查询订单状态及进度。
5、客户服务:为用户提供咨询服务、退换货服务等。
6、评价反馈:用户可以对服务进行评价,为平台提供反馈意见。
二、上门服务平台的特色功能
1、远程控制:用户可以通过平台远程控制家中设备,方便快捷。
2、定时提醒:平台可以设置定时提醒,帮助用户更好地管理生活。
3、智能家居管理:平台提供智能家居管理功能,让用户轻松掌控家庭设备。
4、个性化定制:根据用户需求,提供个性化定制服务。
三、技术支持
1、APP支持:开发精美的应用程序,让用户在手机上轻松预约服务。
2、云端存储:数据存储在云端,保证数据安全可靠。
3、智能语音交互:提供智能语音交互功能,让用户操作更便捷。
4、OTA升级:提供OTA升级服务,让用户随时更新平台享受功能。
对于企业来说,将线下客户引流到企业线上的业务,打通线上线下服务一体化,通过上门服务小成系统接单,大大提升服务效率,轻松获取精准客户,真正做好服务到家。