access 数据库做网站中国建设银行网站查询
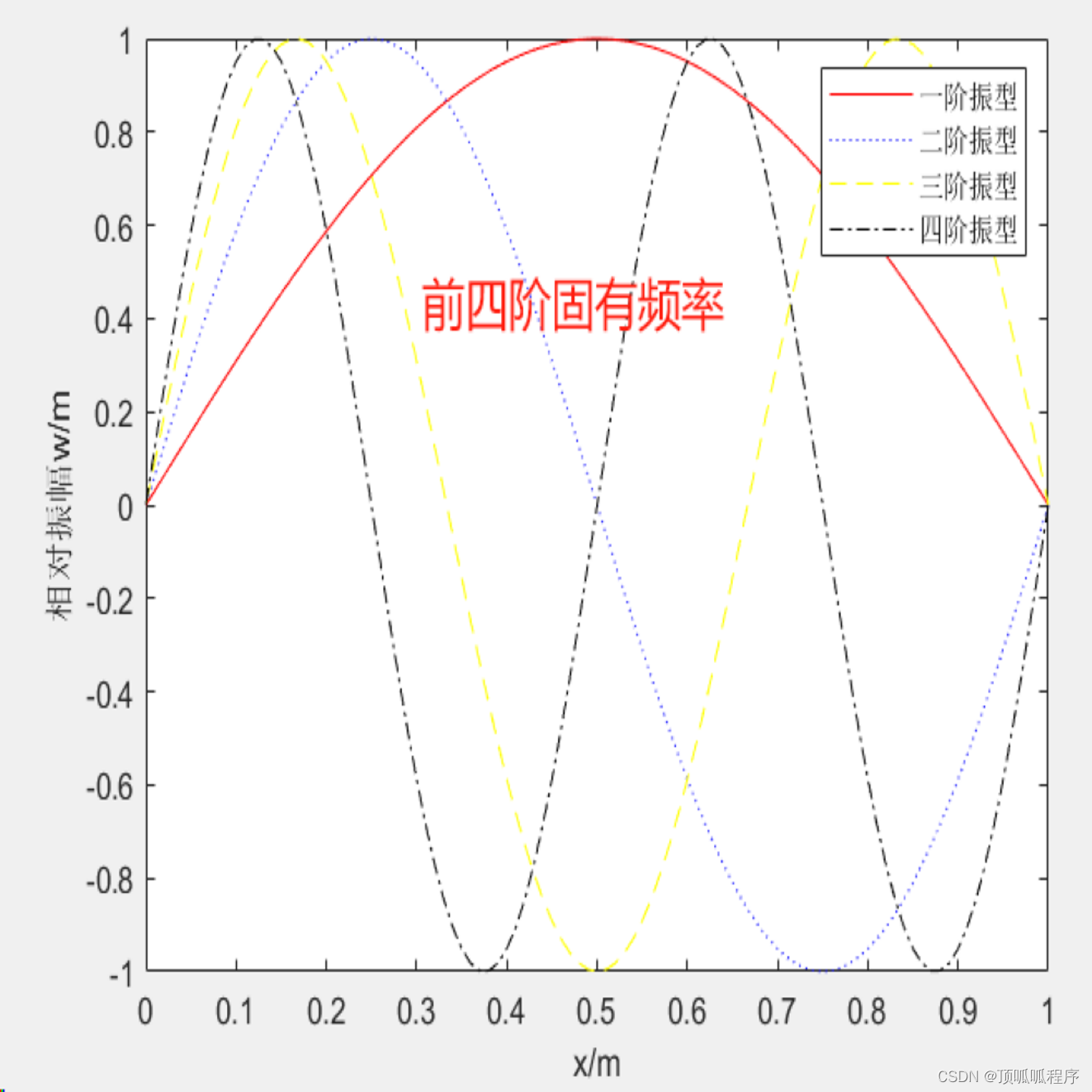
基于matlab的动载荷简支梁模态分析程序,可调节简支梁参数,包括截面宽、截面高、梁长度、截面惯性矩、弹性模量、密度。输出前四阶固有频率,任意时刻、位置的响应结果。程序已调通,可直接运行。
2-16 matlab 动载荷简支梁模态分析 - 小红书 (xiaohongshu.com)
基于matlab的动载荷简支梁模态分析程序,可调节简支梁参数,包括截面宽、截面高、梁长度、截面惯性矩、弹性模量、密度。输出前四阶固有频率,任意时刻、位置的响应结果。程序已调通,可直接运行。
2-16 matlab 动载荷简支梁模态分析 - 小红书 (xiaohongshu.com)