江门网站设计价格wordpress商城插件主题
前言
首先,请教大家几个小小问题,你清楚:
- 什么是TJA1145吗?
- 你知道休眠唤醒控制基本逻辑是怎么样的吗?
- TJA1145又是如何控制ECU进行休眠唤醒的呢?
- 使用TJA1145时有哪些注意事项呢?
今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:
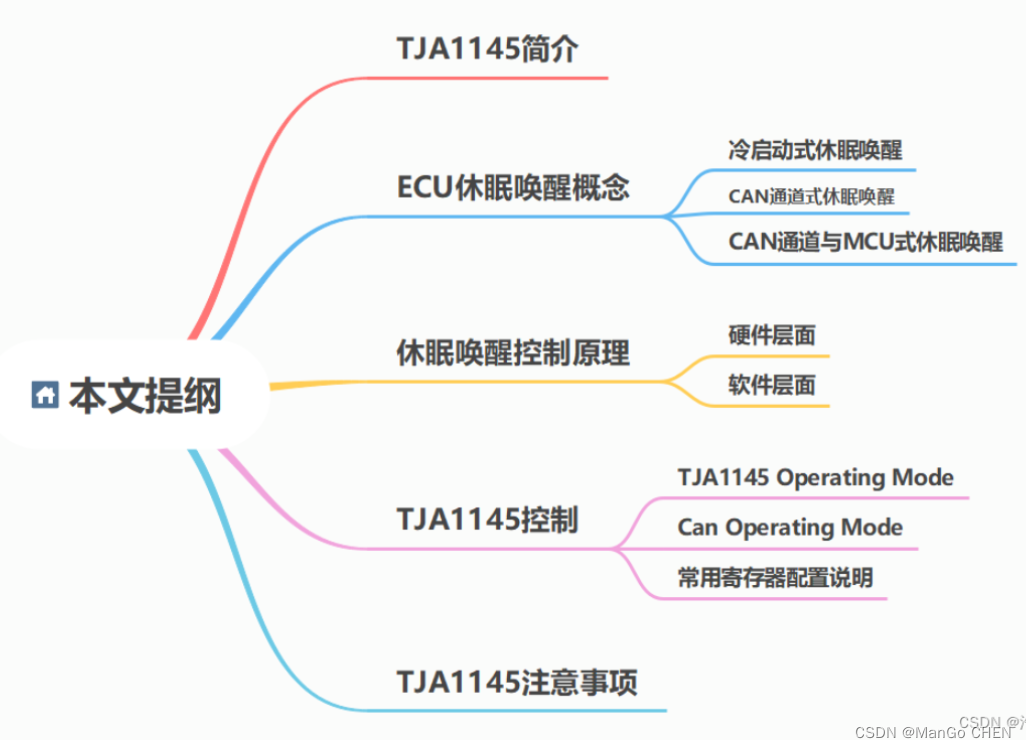
正文
TJA1145简介
TJA1145是NXP公司为汽车电子领域量身定做的高速CAN收发器,提供了CAN控制器与物理CAN双绞线之间的接口,相比其他CAN收发器,它具备如下几个特点:
- 在Standby与Sleep状态下能保持极低功耗,其中Sleep状态下功耗比Standy状态下更低;
- 可通过选择性唤醒功能支持符合ISO11898-2:2016标准的CAN部分网络;
- 针对TJA1145T/FD与TJA1145TK/FD这两种TJA1145/FD变种而言,支持CANFD-Passive功能,能够实现在CANFD与CAN网络共存的前提下保证节点正常休眠不会被总线CANFD总选错误唤醒;
- TJA1145提供接口与3.3V或者5V微控制器相连,通过SPI可用来控制CAN收发器控制以及状态获取;
- TJA1145物理层实现满足了ISO11898-2:2016与SAE J2284标准,且能够实现CANFD 2M通讯速率的稳定通信;
TJA1145上述这些特性使得其能够作为控制ECU整个供电系统的关键利器,通过休眠特性最大可能地降低ECU整体电流消耗,仅在应用层存在需求时才会被唤醒。
如下图1所示为TJA1145的基本功能框图,各个引脚的基本功能解释如下:

图1 TJA1145 基本功能框图
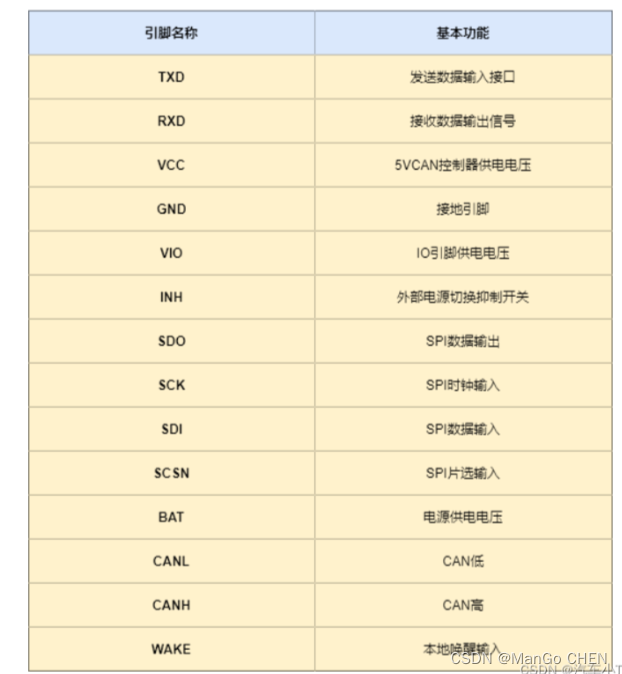
图2 TJA1145功能引脚定义
如下图3所示为TJA1145内部三大供电细节详解:
- BAT: 该电源用于给TJA1145系统状态维护进行供电,只要BAT一直有点,那么TJA1145相关状态寄存器值就不会丢失,且CAN接收器由BAT供电;
- VCC: 该电源一方面作为5V电源输入给到TJA1145系统模块进行监控是否过压或欠压,另一方面则给到CAN总线供电,且CAN发送器由VCC供电;
- VIO: 该电源一方面作为电源输入到TJA1145系统模块进行监控是否过压或欠压,另一方面则作为SPI通信的电平转换;

图3 TJA1145内部供电详解图
ECU休眠唤醒概念
为了让大家更好的了解休眠唤醒控制原理,小T将按照AUTOSAR文档中针对休眠唤醒的定义给大家做个总结,可分为如下三种场景:
冷启动式休眠唤醒
冷启动式休眠唤醒具备如下几个特点:
- MCU处于掉电状态;
- ECU的部分外围电路如CAN发器处于供电状态(如KL30供电);
- 唤醒事件能够被CAN收发器识别;
- CAN收发器能够根据唤醒源决定是否唤醒MCU,给到MCU供电;
CAN通道式休眠唤醒
CAN通道式休眠唤醒具备如下几个特点:
- MCU始终处于正常供电状态;
- 至少ECU的部分外围电路如CAN收发器处于供电状态;
- CAN收发器处于Standby状态;
- 唤醒事件能够被CAN收发器识别;
- CAN收发器识别到有效唤醒源后能够产生一个软中断唤醒MCU或者MCU周期性的去检查是否存在有效唤醒源;
CAN通道与MCU式休眠唤醒
CAN通道与MCU式休眠唤醒具备如下几个特点:
- MCU处于低功耗状态;
- 至少ECU的部分外围电路如CAN收发器处于供电状态;
- CAN收发器处于Standby状态;
- 唤醒事件能够被CAN收发器识别;
- CAN收发器识别到有效唤醒源后能够产生一个软中断唤醒MCU;
休眠唤醒控制原理
通过上述对休眠唤醒类型的总结,想必大家都可以集合自己工作中碰到的休眠场景一一对应起来,小T就结合最为常见的冷启动式休眠唤醒从硬件与软件两个层面跟大家一起交流休眠唤醒控制基本原理。
硬件层面:
如下图4所示,小T将从MCU芯片供电以及TJA1145状态获取控制两方面来讲解硬件层面的休眠唤
醒控制原理:
- S1:MCU满足休眠条件时,通过发送SPI相应指令让TJA1145进入Sleep状态;
- S2:TJA1145进入到Sleep状态后,INH引脚就会拉低,控制5V或者3V关闭电源输出,间接导致MCU整个系统处理掉电状态,此时TJA1145始终处于供电状态(由于BAT始终有电),整个ECU成功进入到休眠状态;
- S3:TJA1145虽然处于Sleep状态,属于极低功耗状态,同步也检测着网络是否存在有效唤醒源;
- S4:当TJA1145发现有效唤醒源之后,就会自动从Sleep状态切换成Standby状态,在Standby状态下INH引脚拉高,此时5V与3V便会正常输出,从而MCU被正常供电,程序开启正常运行;
-
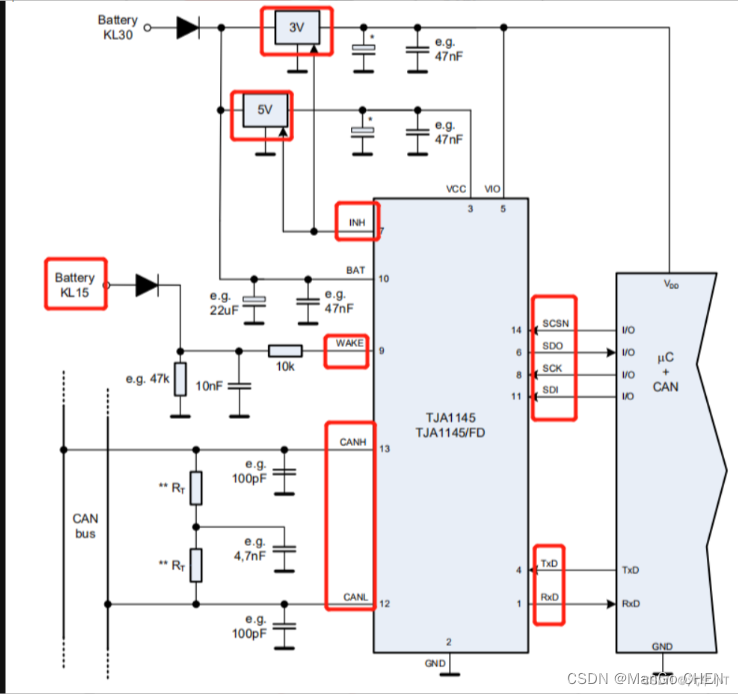
图4 TJA1145休眠唤醒机制硬件实现
软件层面:
基于AUTOSAR软件架构,休眠唤醒的检测处理机制统一有EcuM模块来实现,有关EcuM的详细介绍可参考文章(EcuM)。关于通讯模块的开启则是由ComM模块来负责,BswM在此阶段可实现一些自定义的控制行为来满足各个项目的特别要求。
本文不会过多阐述细节,仅在说明整个休眠唤醒过程在软件逻辑层面具体如何来实现,参考如下图5所示:

图5 休眠唤醒软件控制逻辑
- S1:当MCU Power ON之后由EcuM模块便会检查唤醒源是否有效,若有效,则通知ComM模块开启通信,进而通过SPI通信控制TJA1145进入Normal状态,同时通知BswM模块开启其他BSW模块的控制以及让EcuM进入到RUN模式;
- S2:当MCU PowerON之后由EcuM模块识别唤醒源无效,便会直接走下电流程,最终控制TJA1145进入到Sleep状态;
- S3:在系统正常工作后如果满足休眠条件(如外界没有NM报文),MCU便会控制TJA1145进入到Sleep状态;
- S4:当TJA1145处于Sleep状态下会检测休眠前设定的唤醒源,如果唤醒源满足条件,TJA1145切换至Standby状态,从而Power ON MCU,最终走向EcuM唤醒源检测验证流程;
TJA1145控制
如上述过程MCU通过SPI总线接口实现了针对TJA1145状态的控制与获取。针对TJA1145的控制过程可分为TJA1145 Operating Mode的控制以及内部CAN Operating Mode两种类型。
TJA1145 Operating Mode
在TJA1145内部存在一系统控制器包含如下五种运行状态机:Normal,Standby,Sleep,Overtemp,Off状态。接下来将针对这五种状态进行一一讲解每个状态的基本特征以及相应的SPI控制指令。
Normal: 该模式下TJA1145处于全功能模式下,所有功能均可用,可通过MC=111从Standby或者Sleep状态切换至Normal状态;
Standby: 该模式下TJA1145处于低功耗状态,不过不能够正常收发数据,但是INH引脚可以始终保持拉高状态;
如果此时寄存器CWE=1,那么此时receiver会持续监控总线电平状态,如果寄存器CPNC = PNCOK =1,那么就开启了特定帧唤醒,否则就是标准CAN唤醒(010101切换就可唤醒,即所说的任意帧唤醒);
当电压满足特定下限时便会自动从Off状态切换至Standby状态;
当监测到温度没有再次发生过温便会自动从Overtemp状态切换至Standby状态;
在Sleep状态下检测下唤醒源便会自动切换至Standby状态;
通过SPI指令MC=100将状态从Normal或者Sleep状态切换至Standby状态;
在Normal状态下发送指令MC=001准备切换至Sleep状态,但此时存在唤醒源或者所有的唤醒源检测全部关闭,该特性从一定程度上避免了死锁;
Sleep: 该模式下TJA1145处于最低功耗状态下,且不能正常收发数据,同时INH引脚处于高阻状态,电源供电一般会通过该引脚进行拉低关闭输出。同时其状态变化存在如下几种可能:
- 一个有效唤醒源或者中断事件(除去SPIF事件)或者**SPI指令(SPI通讯速率不能过高)**则可以唤醒TJA1145从Sleep状态切换至Standby状态;
- 在Normal或者Standby状态下通过发送MC=001便可以进入到Sleep状态,同步须确保至少存在一个唤醒源使能(如CAN唤醒或者Wake pin唤醒)且没有pending状态下的唤醒源;
- 如果VCC或者VIO持续一段事件低于某个阈值,那么该低电压事件将会强制让TJA1145进入到Sleep状态,与此同时所有的Peding的唤醒源将会被清除,CWE=1以及WPFE=WPRE=1使能同时特定帧唤醒功能将会被Disable(CPNC=0);
该强制进入到Sleep状态可通过TJA1145主状态寄存器(03h)中的FSMS状态位来获取,如果FSMS为1表示最近一次进入到Sleep状态是由于低电压进入到Sleep状态,否则是通过SPI指令完成的状态切换。
Overtemp:该状态是由于TJA1145放置温度过高导致被损坏的一个功能,一旦在Normal状态下温度超出一定阈值就会自动切换至OverTemp保护状态;
为了放置数据的丢失,TJA1145在温度超过预警阈值时会主动触发一个Warning,该Warning发生时就会触发OTWS置位,中断产生(即OTW=1)如果OTWE使能的前提下;
在该模式下,CAN收发器将不能正常工作,CAN pin脚始终处于高阻状态,唤醒源将不会被检测,但是如果存在Pending的唤醒源,那么RXD引脚就会被拉低;
当温度低于特定阈值时,那么该状态便会自动切换至Standby状态;
如果Bat电压引脚低于某个特定阈值,则会自动从该状态切换至OFF状态;
Off: 在该状态下电压由于低于特定阈值导致供电不足,当Bat首次连接时这是TJA1145的初始状态,只要Bat电压低于某特定阈值,那么TJA1145将会从任意状态直接切换至Off状态。在Off状态下,CAN pin脚以及INH引脚始终处于高阻状态;
当电压高于某个特定阈值时,TJA1145便会重新启动触发初始化过程,从而经历特定时候后进入到Standby状态;

图6 TJA1145 Operating Mode状态迁移图
如下图7所示,展示了TJA1145 Operation Mode与SPI通信,INH引脚,内部CAN模块状态以及RXD引脚的之间的关系。从中特别值得关注的有以下几点:
Standby状态下INH引脚可以拉高控制MCU各级电源输入,CAN无法正常收发通信;
Normal状态下SPI可正常通信,INH引脚拉高,CAN模块的状态取决于CMC值,仅在Active状态下才能够开启正常通信,且仅在CMC=01/10/11下才能够正常收发;
Sleep状态下INH引脚处于高阻状态,此时MCU各级电源可关闭,CAN始终处于Offline状态,无法正常收发通信;
在Off状态与Overtemp状态下SPI都无法正常通信,在Sleep状态仅在VIO供电正常的情况下才可以,且通信速率不能太高;
仅在Standby与Sleep状态下才检测唤醒事件,即仅在CAN处于Offline模式下才能够开启唤醒事件的检测;

图7 TJA1145各模式状态关系
Can Operating Mode
TJA1145内部集成的CAN收发器存在四种状态:Active,Listen-Only,Offline,Offile Bias状态。存在如下两种基本组合:
当TJA1145处于Normal状态时,CAN收发器状态取决于CMC值,如进入Offline或者Active或者Listen-only等;
当TJA1145处于Standby或者Sleep状态,则CAN收发器始终处于Offline状态;

图8 TJA1145内部CAN收发器状态迁移图
CAN Active Mode
CAN收发器在此模式下能够正常发送或接收数据;
当CMC=0x01时,CAN收发器处于Active状态,VCC低压检测使能,如果出现VCC电压,就会直接切换到CAN Offline或者Offline Bias状态;
当CMC=0x10时,CAN收发器处于Active状态,且VCC电压检测被抑制,如果出现VCC电压异常,不会影响到CAN Active正常切换;(实际应用过程中优先统一配置成CMC=0x10,以降低状态不断反复切换)
CAN Listen-only Mode
该模式下CAN发送器被关闭,当TJA1145处于Normal状态且CMC=0x11时,CAN收发器状态就会处于Listen-only状态;
在该模式下如果TJA1145处于Normal状态且CMC=0x1,同时VCC电压低于90%,那么就会始终在这个Listen-Only状态;
CAN Offline与Offline Bias Mode
在CAN Offline模式下CAN收发器便会检测CAN总线以查看是否存在唤醒事件,同时CWE=1,CAN H与CAN L始终偏置接地;
在CAN Offline Bias Mode下也会检测CAN总线是否存在唤醒事件,只不过CAN H与CAN L会偏置2.5V,当超过一段事件总线没有活动,便会回归至CAN Offline模式下;
当TJA1145切换至Standby或者Sleep状态则会直接切换成此状态;
当TJA1145状态为Normal且CMC=0x0,则会将状态切换成CAN Offline模式;
当TJA1145状态为Normal且CMC=01同时VCC<90%,则也会将状态切换成CAN Offline模式;
CAN Off Mode
当TJA1145状态为Off状态或者Overtemp状态时;
当Bat电压低于CAN接收器某个特定阈值电压时,当BAT电压回升至某个特定阈值时,便会进入到CAN Offline模式下;
常见寄存器配置说明
在对TJA1145进行正常使用时,无论是初始化过程还是正常对其进行控制,我们都需要针对常见的TJA1145寄存器进行控制,因此小T结合项目实战需要给大家列举了常用寄存器以及相关功能,如下图9所示:
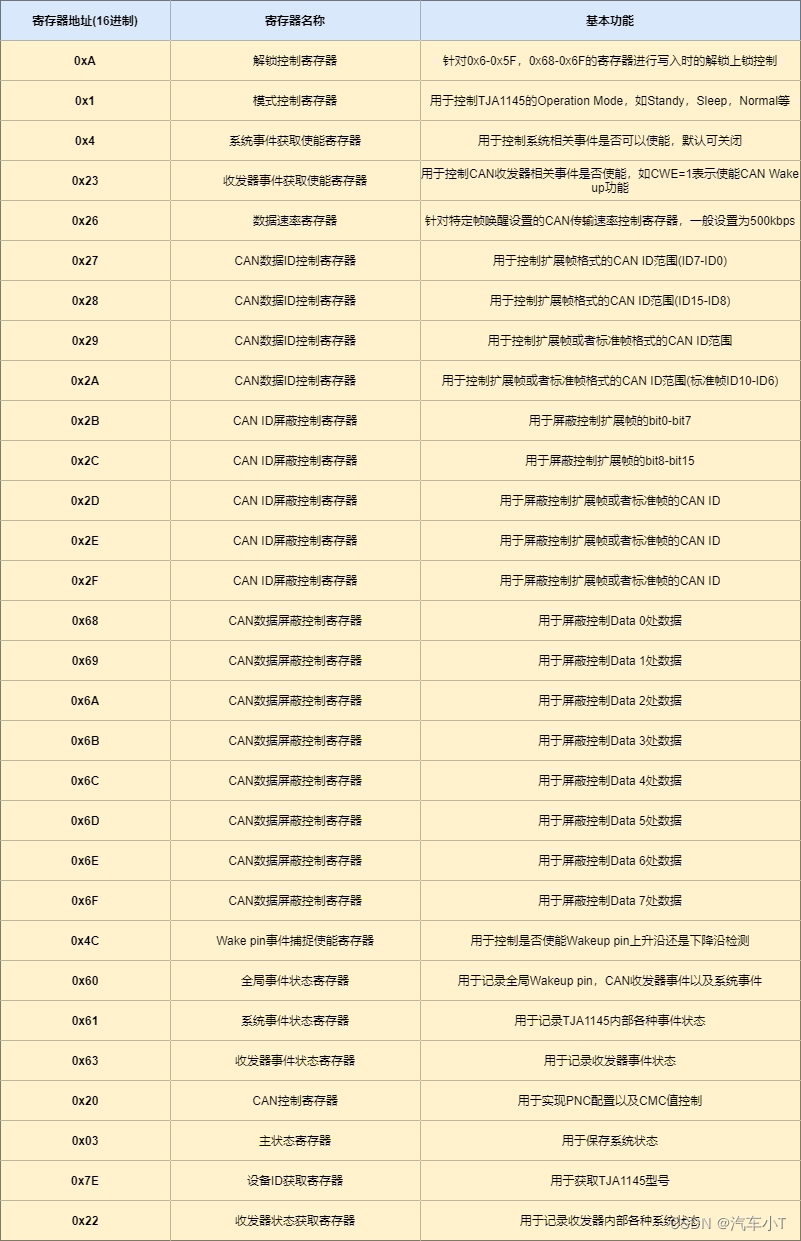
图9 常见寄存器配置说明
TJA1145使用注意事项
- 使用TJA1145时,如果需要使用其CAN FD Passive功能(0x2F寄存器设置 CFDC=1),那么需要选用型号TJA1145/FD才具备;
- TJA1145默认仅支持CAN帧格式的特定帧唤醒;
- 如果使能了VCC/VIO电压欠压监控,如出现在缓升缓降的过程中,就会导致TJA1145状态直接切换成sleep状态,因此一般优先选择CMC=0x10,则抑制了电压欠压检测。