电商公司网站怎么优化推广自己的网站
一.函数介绍
gets函数:
该函数就是读取字符串,遇到空格不会停止,直到遇到换行字符,但是也会读取最后的换行字符(这也就是我在写代码的时候遇到的一个问题)
getchar函数:
和gets函数类似,也会有读取换行字符的效果。
二.缓存区
在说明这个问题之前不得不说明一下内存中缓存区的问题,如下图:
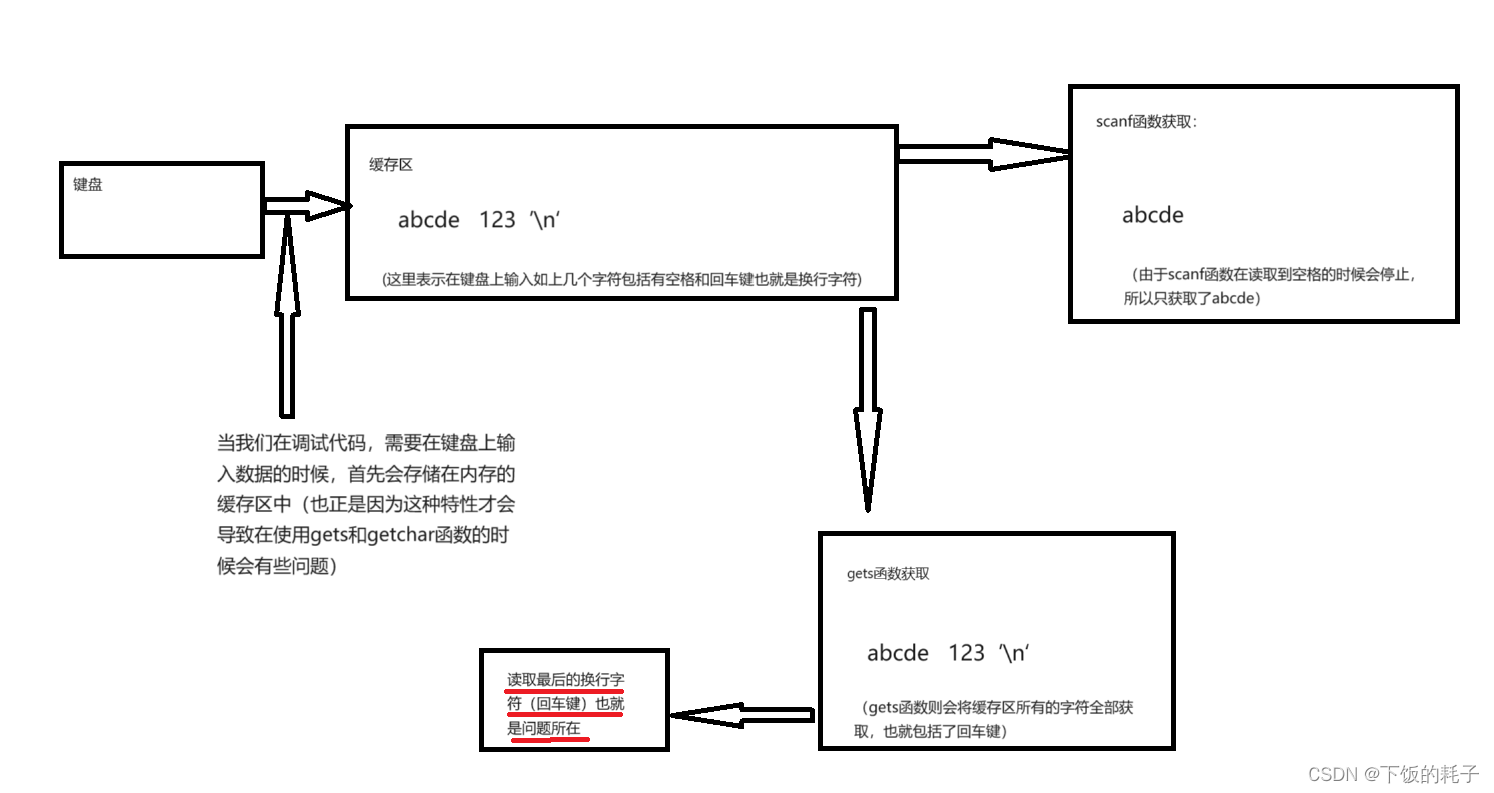
所以基于上述理论,在使用gets和getchar的时候要万分小心 换行字符(回车键)。
三.具体使用
先看下面的一串代码:
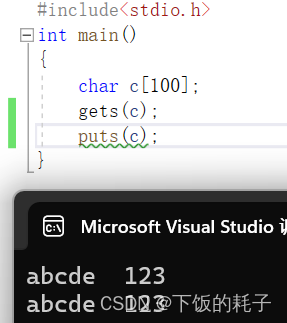
这样看似乎是没有问题的,警告也只是因为没有加终止字符,但是请看下图!!!

嘶,这里则么会出现警告呢?而且显示出如下的错误

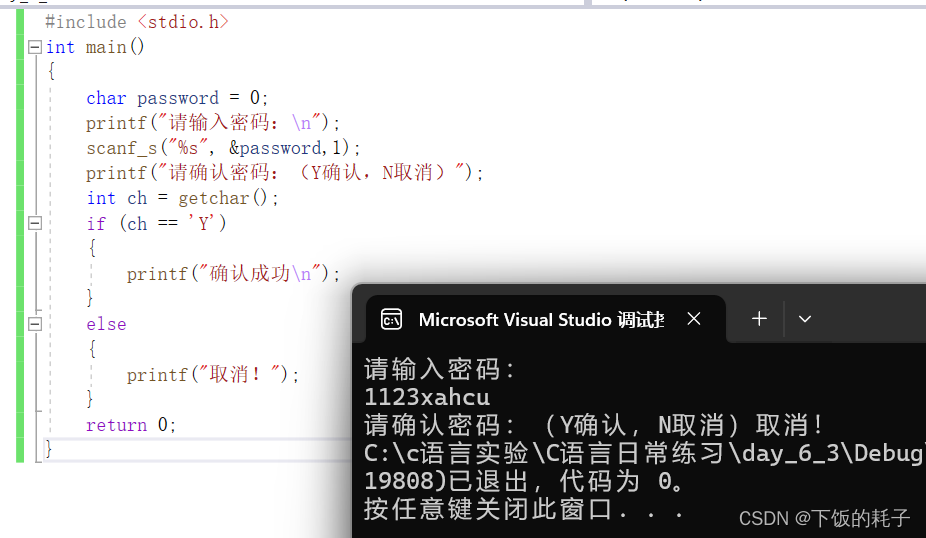
可以看出这里显示缺少“scanf_s”的整型参数,那么如何去解决这个问题呢?
其实我们平时使用 scanf_s 函数的时候不会注意这个问题,但是在使用该函数的时候最好加上一个数字来确定最多读取多少字节,比如这里定义了一个char类型的字符,所以也就是加上数字一,具体格式如下
这样我们就解决了上述问题!!
接下来,我们回归原问题!对于上图显示无法确认密码的问题。
根据之前所说的理论由于getchar函数会读取掉换行字符,所以我们在 输入密码 之后继续在键盘上输入的回车键(也就是换行字符)会直接被getchar读取,从而相当于输入了一个换行字符,也就是执行了else语句里面的语句!
改进!!如图:
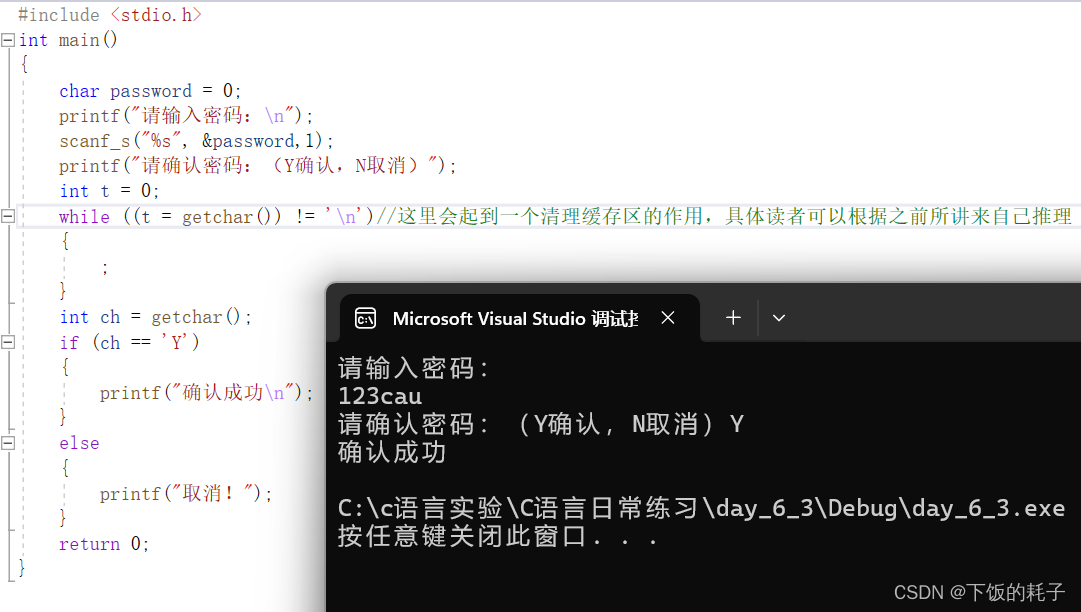
具体改进原理相信只要理解了缓存区和getchar类型函数特点的你们也可以理解!(加油,你是最棒的)