爱有声小说网站捡个校花做老婆网站建设策划内容
(接上篇)
面试题(MySQL篇)
3. 如何提高MySQL的查询速度?
考点解析:
考察面试者对MySQL查询优化的理解
参考答案:
(因为这个问题如果回答的详细一点可以写上一整篇,但是该篇暂不打算这么描述。这里简单提几个点,后面会专门开一篇讲MySQL查询优化的问题)
(1). 当使用SELECT...WHERE...查询的时候,添加索引给指定列;
(2). 当查询大表的时候,尽量避免全表扫描(即SELECT * FROM TABLE_A...)
(3). 当要对同一批数据进行重复查询的时候,利用好缓存策略(比如InnoDB的buffer pool(缓冲池)、MyISAM的Key(键)缓存和 MySQL 查询缓存);
(4). 当查询语句含有LIKE表达式的时候,避免使用前置通配符(比如LIKE '%xxx'这样);
(5). 通过定期使用 ANALYZE TABLE语句保持表的统计信息最新;
(6). …
面试总结:
此题难度中等偏上,需要面试者对MySQL的查询原理足够了解才能回答全面,建议在工作中多对MySQL查询语句进行优化才能更好的理解掌握。
考点延伸:了解MySQL的EXPLAIN 计划吗?简单谈一下你的理解。
(下一篇更新Excel相关面试题,尽请期待)
补充回答上一篇考点延伸的两个问题参考答案
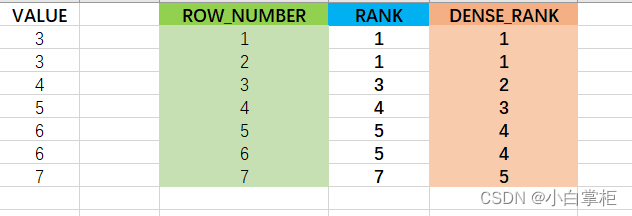
考点延伸1:ROW_NUMBER() VS RANK() VS DENSE_RANK()三者的区别?
参考答案:
简单来说,三者都可以用来做排名,不同点在于ROW_NUMBER()会给每个排名赋予一个唯一的数值;而RANK()与DENSE_RANK()都会给相同值赋予同一个排名,不同点又在于RANK()会给下一个值排名的时候跳过之前连续的排名;DENSE_RANK()则不会。可以看下面这个示例就很清楚展示了三者的区别:
考点延伸2:MySQL中是否存在NATURAL JOIN ?
参考答案:
MySQL中是存在NATURAL JOIN的。
NATURAL JOIN 是一种 JOIN 类型,它不需要指定 JOIN 条件,而是基于两个表之间存在相同列名的列自动进行 JOIN 操作。NATURAL JOIN 会返回两个表中列名相同的列的交集,这些列通常用作 JOIN 条件。
基础语法如下:
SELECT *
FROM table1
NATURAL JOIN table2;
MySQL会自动查找 table1 和 table2 中列名相同的列,并将它们用作 JOIN 条件。
需要注意的是,使用 NATURAL JOIN 可能会导致不必要的 JOIN,因为如果两个表中有多个列名相同的列,则所有这些列都将用作 JOIN 条件,可能会导致 JOIN 条件过于宽松。
因此,对复杂查询进行优化时,应谨慎使用 NATURAL JOIN。
PS: 本篇探讨的情况都是基于MySQL8.0版本及以上的,谢谢。
参考资料:
MySQL官方文档