呼伦贝尔建设网站微信小游戏
开发版,体验版,用此方法都可以正确获取定位,但是在小程序的线上,总是获取失败
参考:uni-app微信小程序uni.getLocation获取位置;authorize scope.userLocation需要在app.json中声明permission;小程序用户拒绝授权后重新授权-CSDN博客
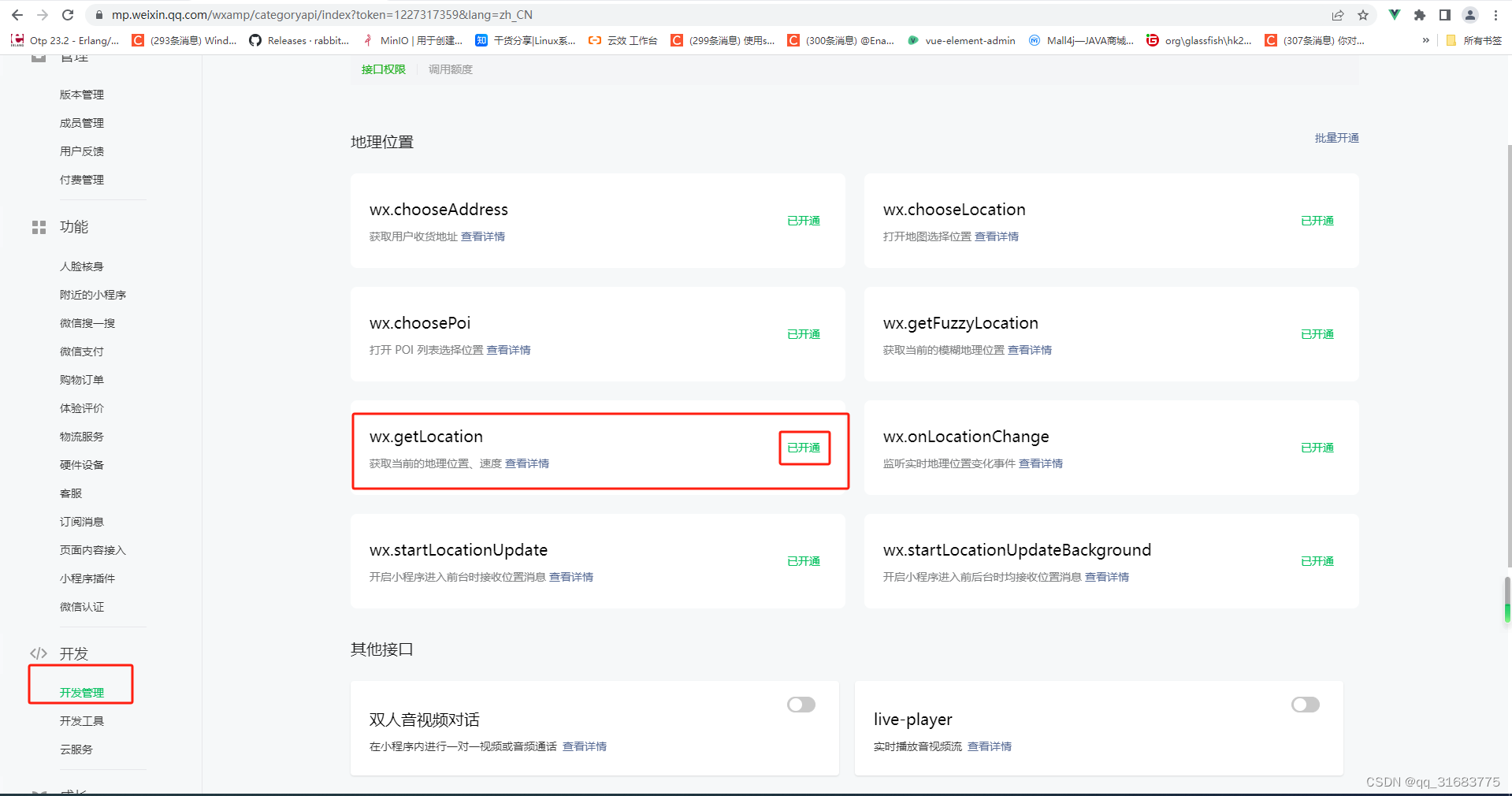
uniapp 中的 uni.getLocation()方法,打包为小程序后,可能调用的是wx.getLocation()方法,所以,我们需要确定wx.getLocation()的权限是否开通