东莞网站建设 少儿托管wordpress页面加载慢
前言:
windows和linux的目录路径斜杆是相反的,在ssh或者其他什么工具在win和ubuntu传文件时候经常需要用到两边的路径,有这个工具就不用手动去修改斜杆反斜杠了。之前有个在线网站,后来挂了,就想着自己搞一个脚本来用。先看效果,代码放后面了,或者直接下载脚本也行。
效果:
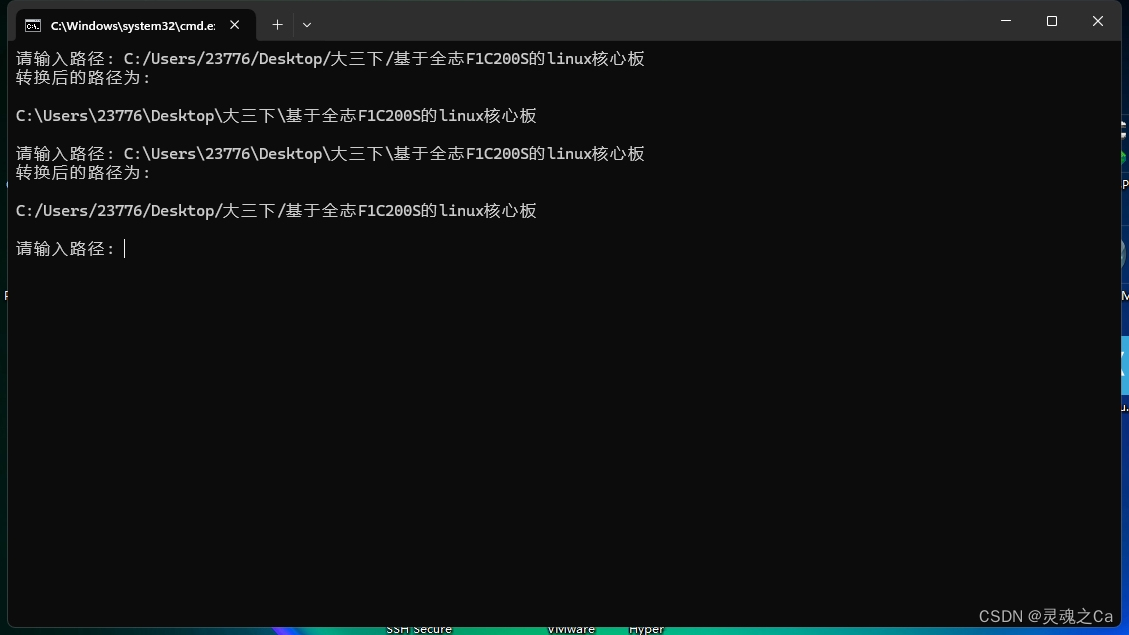
输入路径之后回车,它会自动识别是/或者\,并且转换成另外一种格式的路径。
编写方式:
新建一个.bat结尾的脚本,名字任意;

编辑,写入代码:
@echo off
chcp 65001 > nul
setlocal enabledelayedexpansion:input
set /p "input_path=请输入路径: "
if "%input_path%"=="" goto :eofset "output_path="
set "temp_path=%input_path%"
:process_path
if not defined temp_path (echo 转换后的路径为: echo.echo !output_path!echo.goto :input
)set "char=!temp_path:~0,1!"
if "%char%"=="\" (set "output_path=!output_path!/!"
) else if "%char%"=="/" (set "output_path=!output_path!\!"
) else (set "output_path=!output_path!!char!"
)set "temp_path=!temp_path:~1!"
goto :process_path
脚本下载:
资源那