赣榆哪里有做网站的wordpress保存帖子数据库
创建一个脚本
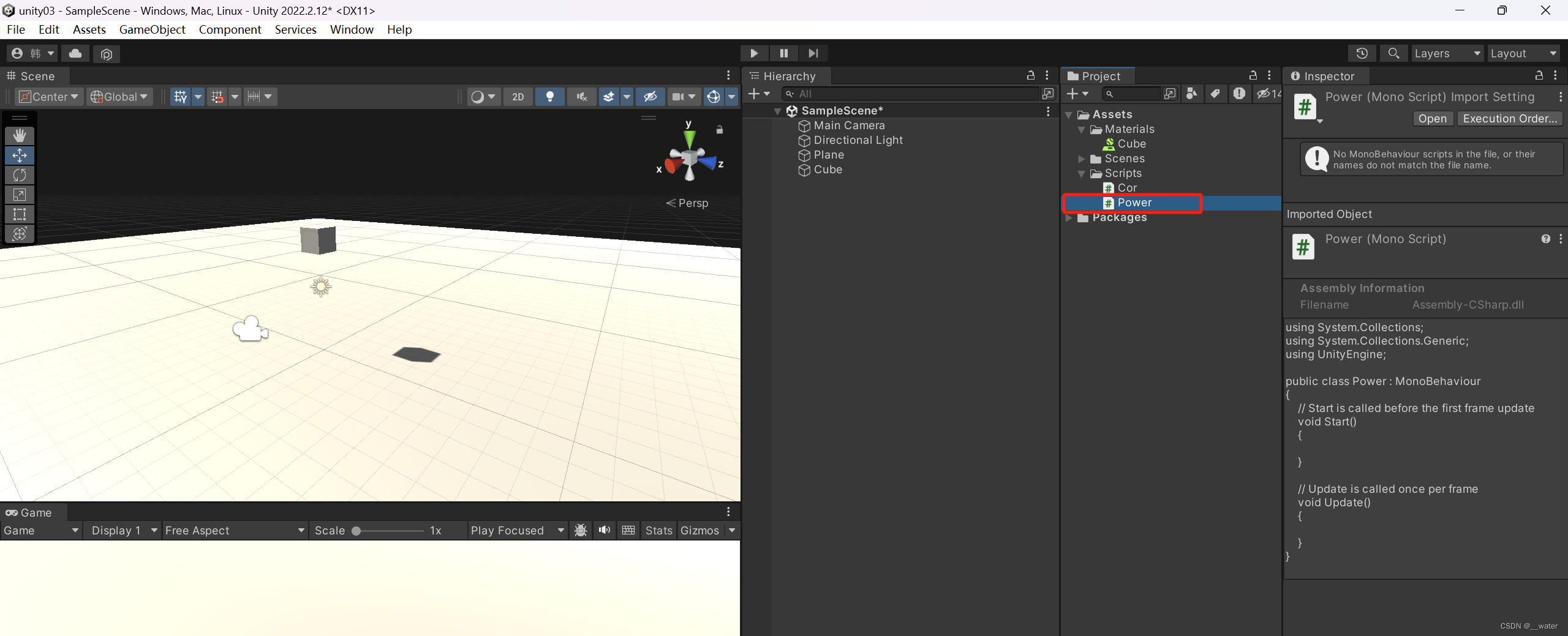
将代码挂载到物体上
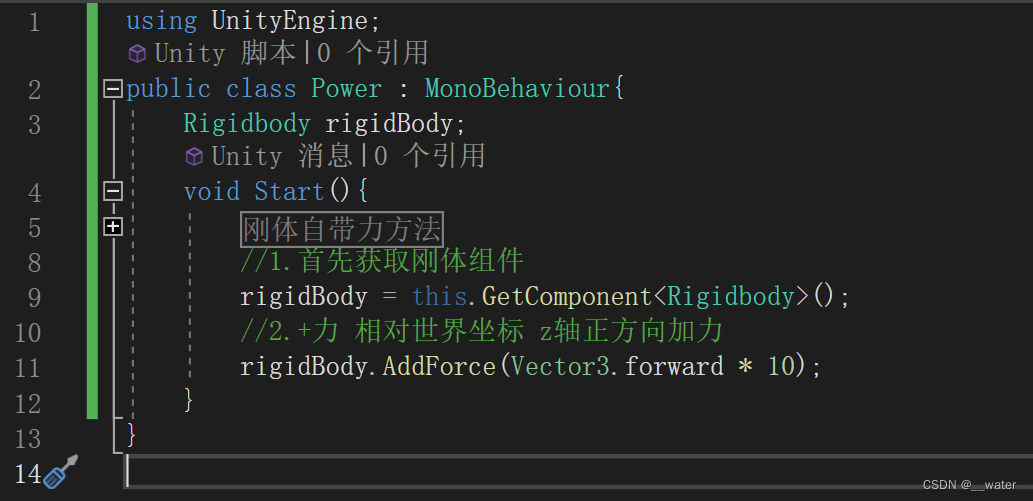
取消物体的重力
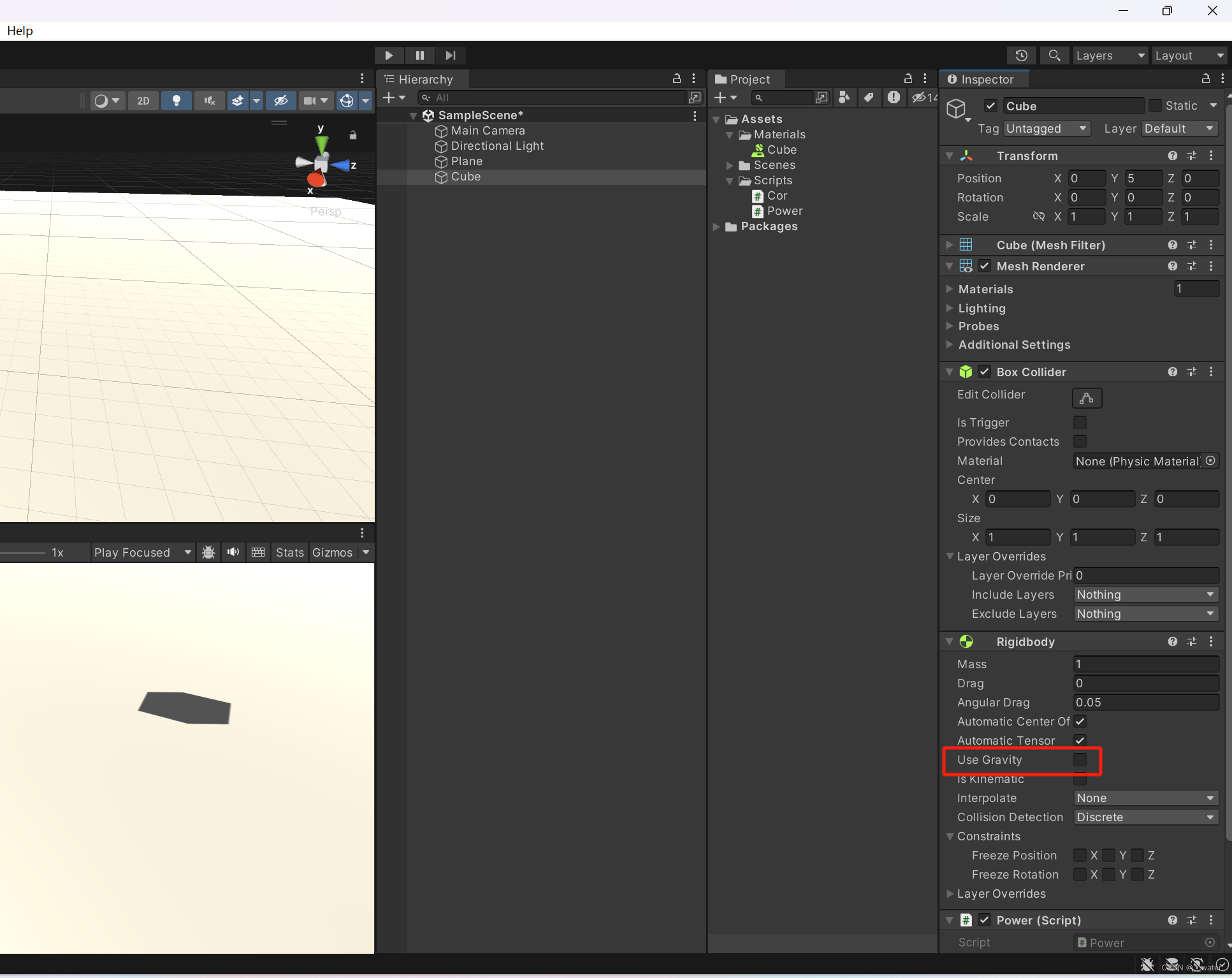
运行即向z轴运动
加力之后 是否停止是由阻力影响 如果阻力为零 则会一直运动
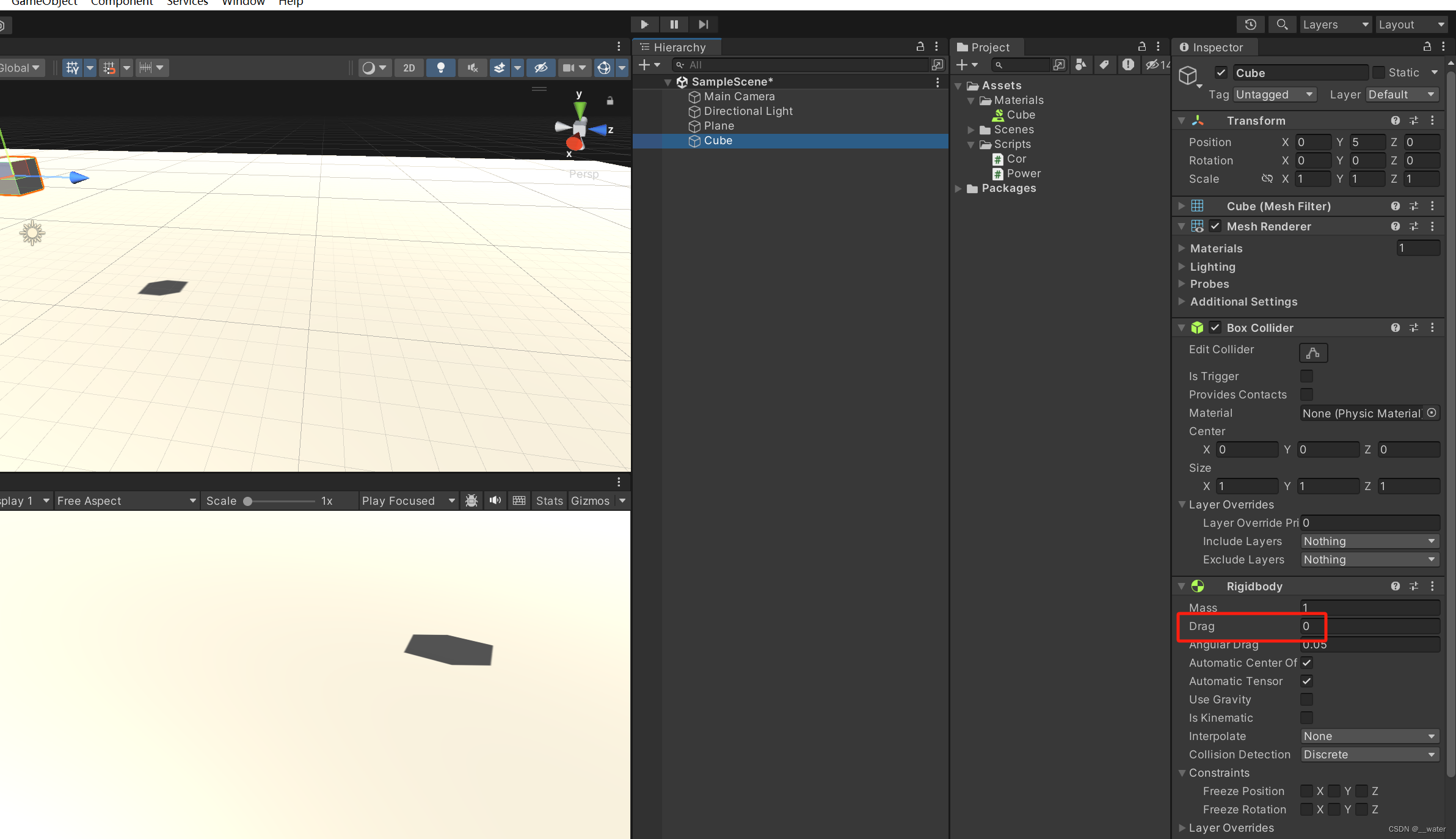
如果希望就算有阻力也让物体一直动就将加力代码放在Update函数里
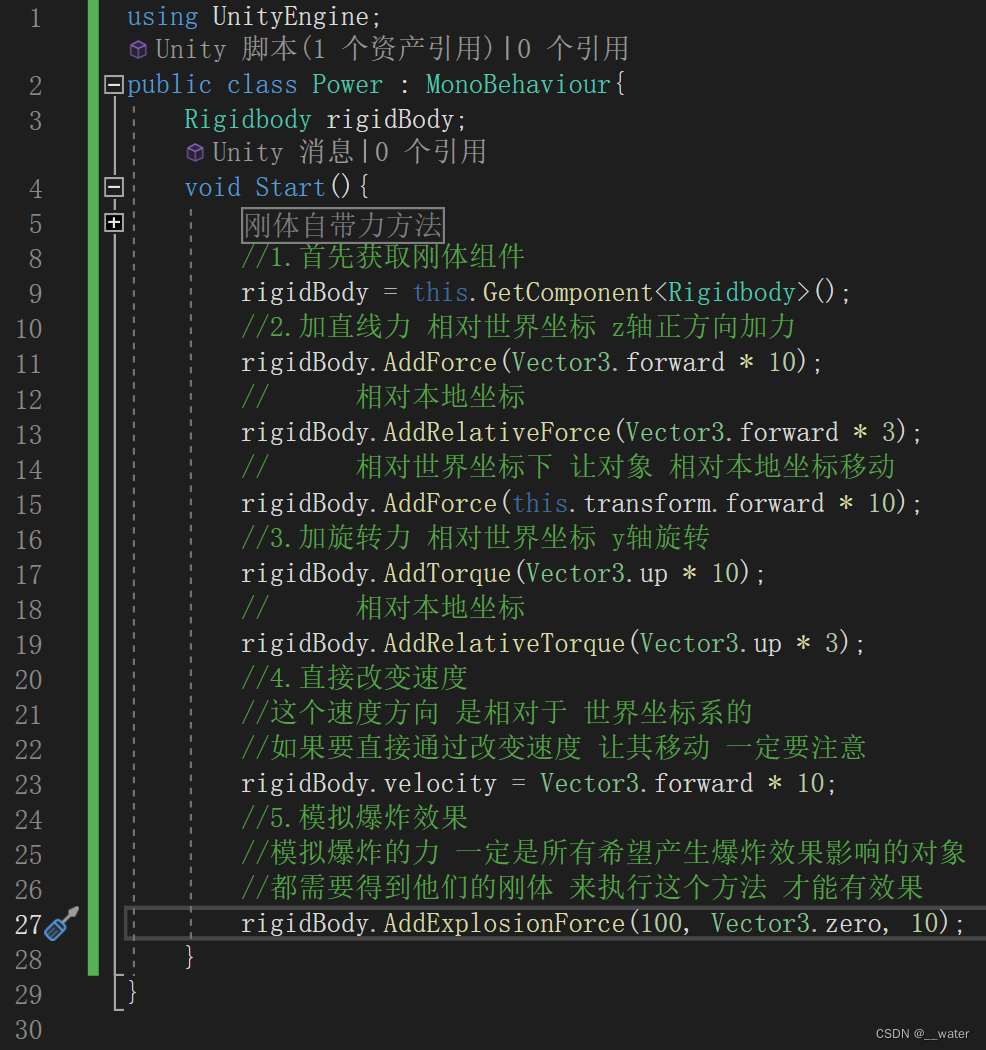
using UnityEngine;
public class Power : MonoBehaviour{
Rigidbody rigidBody;
void Start(){
#region 刚体自带力方法
#endregion
//1.首先获取刚体组件
rigidBody = this.GetComponent<Rigidbody>();
//2.加直线力 相对世界坐标 z轴正方向加力
rigidBody.AddForce(Vector3.forward * 10);
// 相对本地坐标
rigidBody.AddRelativeForce(Vector3.forward * 3);
// 相对世界坐标下 让对象 相对本地坐标移动
rigidBody.AddForce(this.transform.forward * 10);
//3.加旋转力 相对世界坐标 y轴旋转
rigidBody.AddTorque(Vector3.up * 10);
// 相对本地坐标
rigidBody.AddRelativeTorque(Vector3.up * 3);
//4.直接改变速度
//这个速度方向 是相对于 世界坐标系的
//如果要直接通过改变速度 让其移动 一定要注意
rigidBody.velocity = Vector3.forward * 10;
//5.模拟爆炸效果
//模拟爆炸的力 一定是所有希望产生爆炸效果影响的对象
//都需要得到他们的刚体 来执行这个方法 才能有效果
rigidBody.AddExplosionForce(100, Vector3.zero, 10);
}
}
运行即可在中心(0,0)受到一爆炸力被弹开然后自己受到旋转和向z轴移动的力

【力组件】:在场景物体上添加一个常量力的组件
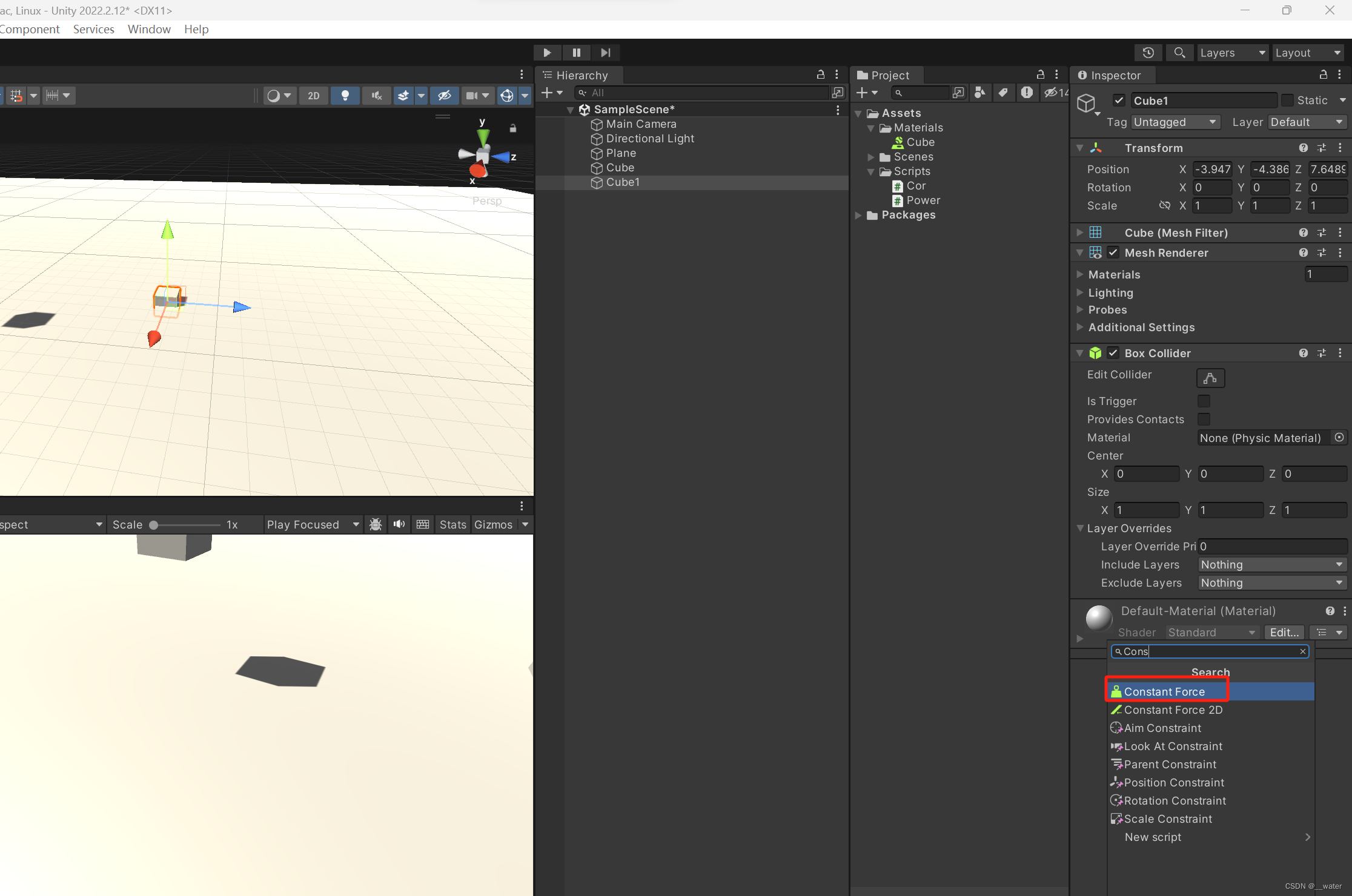
如果这个物体没有刚体 会自动添加一个带重力的刚体 我们可以取消重力 改变它的旋转力让其旋转
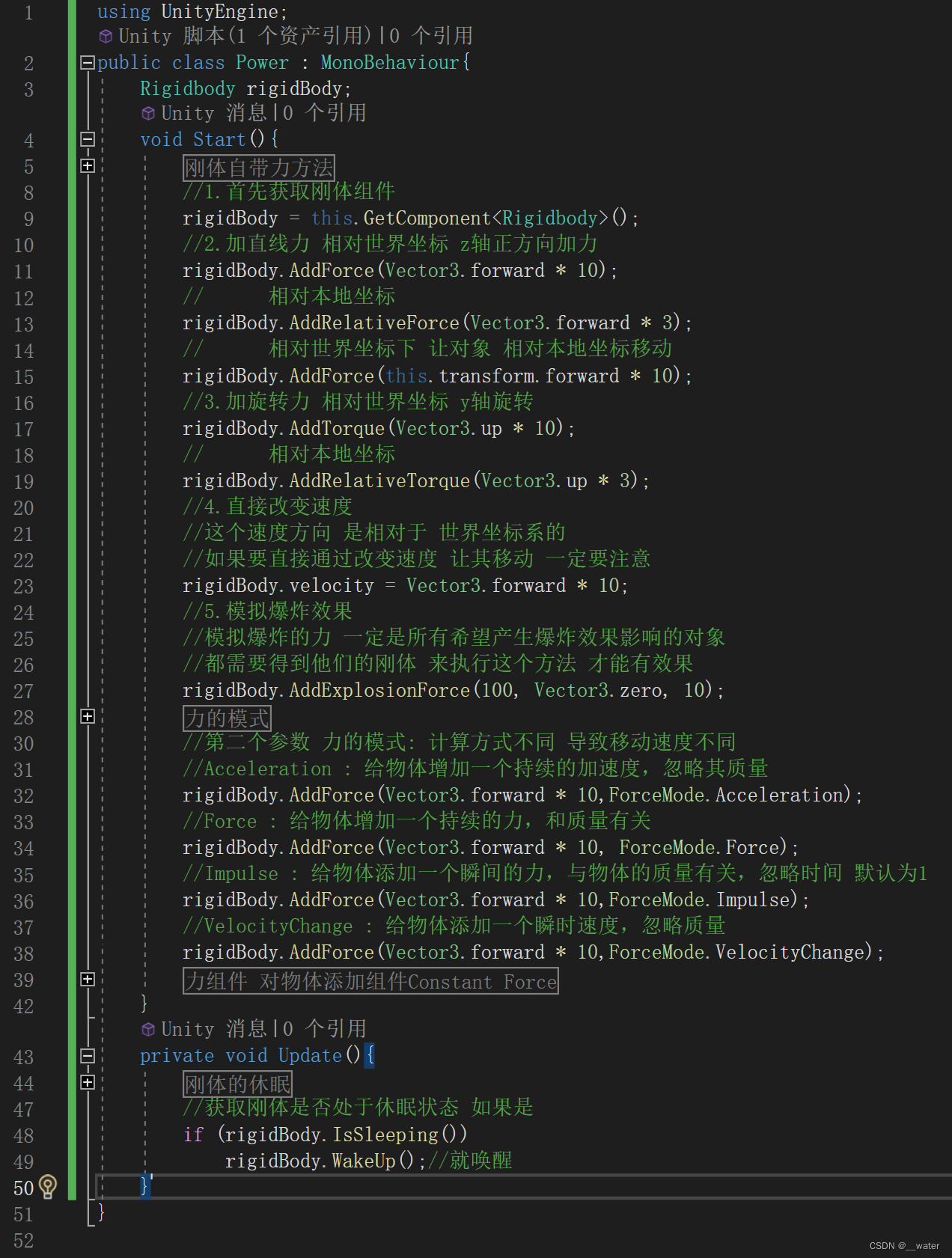
using UnityEngine;
public class Power : MonoBehaviour{
Rigidbody rigidBody;
void Start(){
#region 刚体自带力方法
#endregion
//1.首先获取刚体组件
rigidBody = this.GetComponent<Rigidbody>();
//2.加直线力 相对世界坐标 z轴正方向加力
rigidBody.AddForce(Vector3.forward * 10);
// 相对本地坐标
rigidBody.AddRelativeForce(Vector3.forward * 3);
// 相对世界坐标下 让对象 相对本地坐标移动
rigidBody.AddForce(this.transform.forward * 10);
//3.加旋转力 相对世界坐标 y轴旋转
rigidBody.AddTorque(Vector3.up * 10);
// 相对本地坐标
rigidBody.AddRelativeTorque(Vector3.up * 3);
//4.直接改变速度
//这个速度方向 是相对于 世界坐标系的
//如果要直接通过改变速度 让其移动 一定要注意
rigidBody.velocity = Vector3.forward * 10;
//5.模拟爆炸效果
//模拟爆炸的力 一定是所有希望产生爆炸效果影响的对象
//都需要得到他们的刚体 来执行这个方法 才能有效果
rigidBody.AddExplosionForce(100, Vector3.zero, 10);
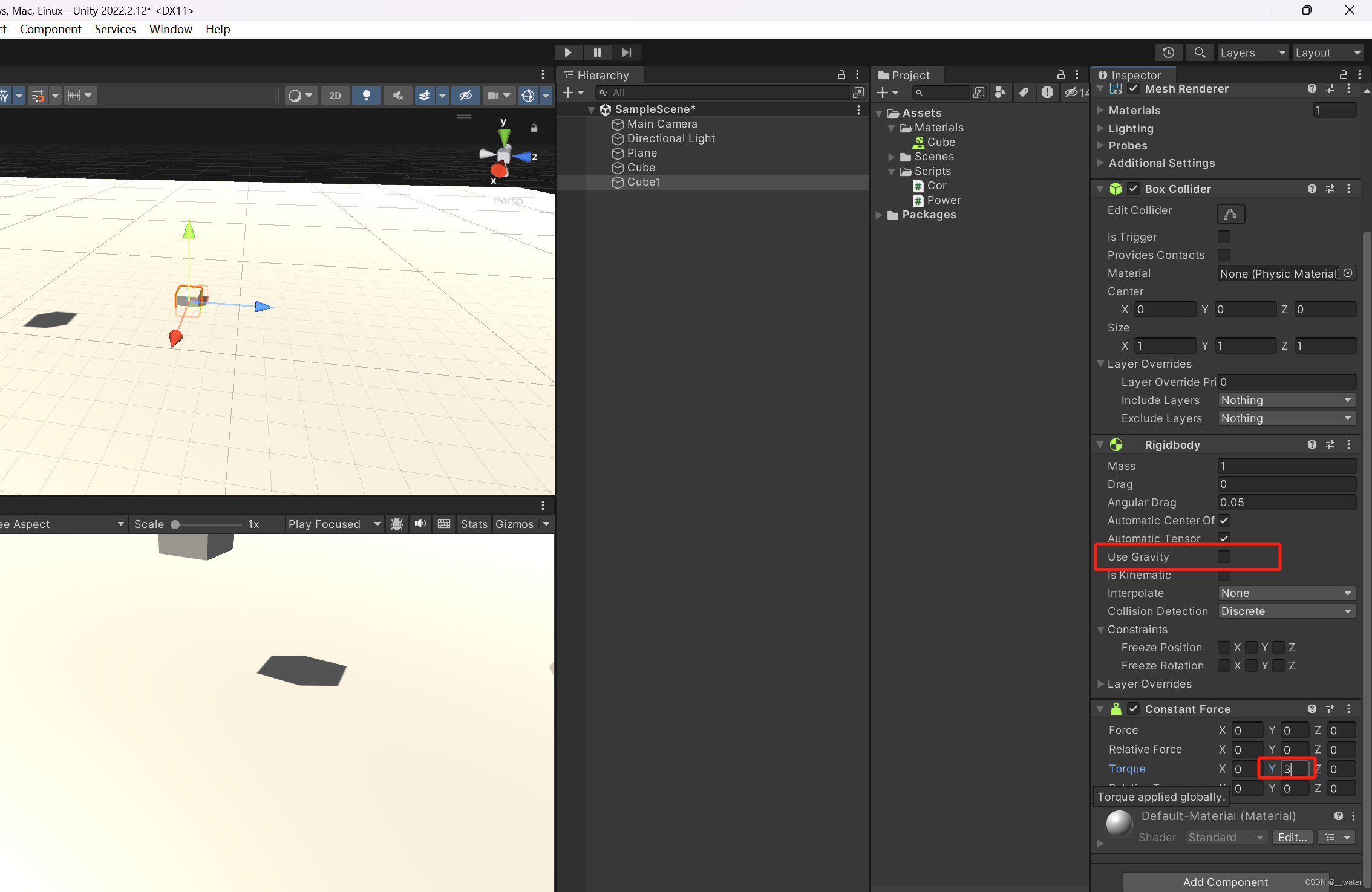
#region 力的模式
#endregion
//第二个参数 力的模式: 计算方式不同 导致移动速度不同
//Acceleration : 给物体增加一个持续的加速度,忽略其质量
rigidBody.AddForce(Vector3.forward * 10,ForceMode.Acceleration);
//Force : 给物体增加一个持续的力,和质量有关
rigidBody.AddForce(Vector3.forward * 10, ForceMode.Force);
//Impulse : 给物体添加一个瞬间的力,与物体的质量有关,忽略时间 默认为1
rigidBody.AddForce(Vector3.forward * 10,ForceMode.Impulse);
//VelocityChange : 给物体添加一个瞬时速度,忽略质量
rigidBody.AddForce(Vector3.forward * 10,ForceMode.VelocityChange);
#region 力组件 对物体添加组件Constant Force
#endregion
}
private void Update(){
#region 刚体的休眠
#endregion
//获取刚体是否处于休眠状态 如果是
if (rigidBody.IsSleeping())
rigidBody.WakeUp();//就唤醒
}
}