营销网站是什么意思郑州高端建站公司
基于架构的软件开发方法
基于架构的软件开发方法是由架构驱动的,即指由构成体系结构的商业、质量和功能需求的组合驱动的。使用ABSD 方法,设计活动可以从项目总体功能框架明确就开始,这意味着需求抽取和分析还没有完成(甚至远远没有完成),就开始了软件设计。设计活动的开始并不意味着需求抽取和分析活动就可以终止,而是应该与设计活动并行。特别是在不可能预先决定所有需求时(例如,产品线系统或长期运行的系统),快速开始设计是至关重要的。

基于架构的软件开发过程
基于架构的软件开发方法的三个基础
ABSD 方法有3 个基础。第1个基础是功能的分解。在功能分解中,ABSD 方法使用已有的基于模块的内聚和耦合技术。第 2个基础是通过选择体系结构风格来实现质量和商业需求,第3个基础是软件模板的使用,软件模板利用了一些软件系统的结构。
ABSD 方法是递归的,且迭代的每一个步骤都是清晰定义的。因此,不管设计是否完成,体系结构总是清晰的,这有助于降低体系结构设计的随意性。
功能分解
基于架构的软件开发方法(ABSD)的第一个基础是功能的分解,ABSD方法使用已有的基于模块的内聚和耦合技术 。在功能分解中,ABSD方法将复杂系统简化为更小、更易于管理和可理解的部分。功能分解使设计、分析和实现复杂系统变得容易。
选择体系结构风格
基于架构的软件开发方法(ABSD)在选择架构风格时,应该考虑商业、质量和功能需求的组合。ABSD方法强调由商业、质量和功能需求的组合驱动软件架构设计。ABSD是一个自顶向下,递归细化的软件开发方法,它以软件系统功能的分解为基础,通过选择架构风格实现质量和商业需求 。
在候选的分布式架构中,低级别的事件驱动或微服务架构与大多数架构特性相匹配。在这两者中,微服务更好地支持不同的操作架构特性,纯粹的事件驱动架构通常不会因为这些操作架构特性而获得优势。
选择架构模版
在ABSD方法中,软件模板是一个重要的概念。软件模板利用了一些软件系统的结构,但是它们并不是一个完整的解决方案。相反,它们提供了一些可重用的元素,这些元素可以在多个项目中使用。在使用软件模板时,应该根据项目的需求进行适当的修改和扩展。
基于架构的软件开发方法的六个步骤
架构需求
重点是标识构件的三步

架构设计
将需求阶段的标识构件映射为构件进行分析
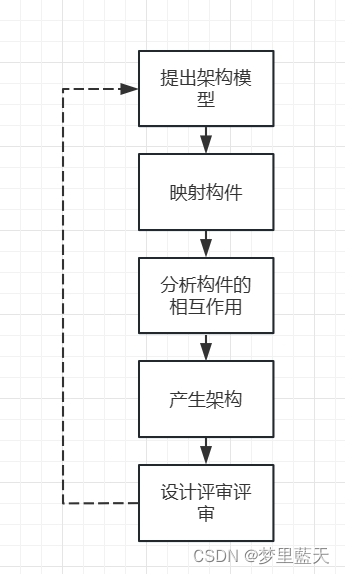
架构文档化
架构文档化主要产生2种文档,架构规格说明书,测设架构需求的质量设计说明书,文档至关重要,关系到开发的成败。
架构评审
由外部人员 (独立于开发组织之外的人,如用户代表和领域专家等)参加的复审,复审架构是否满足需求,质量问题,构件划分合理性等。若复审不过,则返回架构设计阶段进行重新设计、文档化,再复审。
架构实现
用实体来显示出架构。实现构件,构件组装成系统
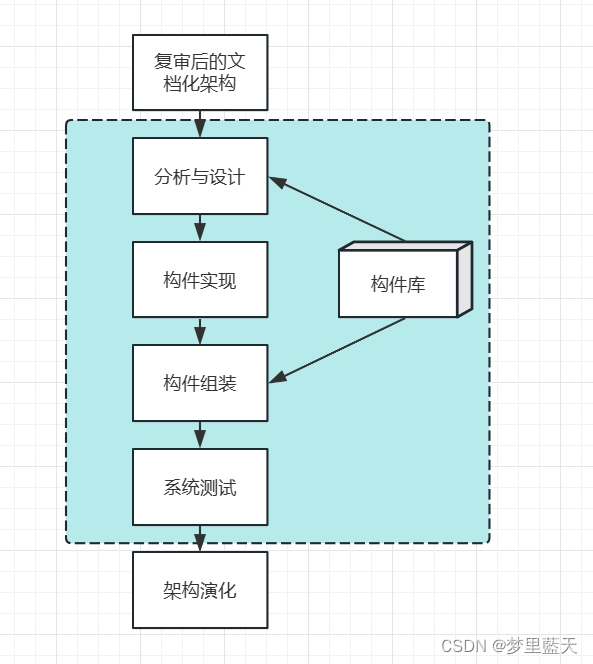
架构演化
对架构进行改变,按需求增删构件,使架构可复