网站配色与布局 教材最常用的网站推广方式
近日,盖雅工场成功举办物业行业人效提升专场交流,来自广深地区央企和民营的领先物业企业和现场服务业的多位代表齐聚深圳招商积余大厦,共同研讨行业人效提升的挑战和实践。
本次闭门交流会聚焦于人效提升,讨论话题包括各自企业在人效提升方面的实践经验和挑战应对,并针对如何更好利用灵活用工深入研讨。

与会的领先企业代表们就如何提升企业人效进行了深入讨论。他们提出了以下几点观点和建议:
确认人效指标,统一衡量标准:人效提升是组织行为,不是单个部门的任务,企业应明确认识,并选择合适指标为突破点。同时做好数据治理,统一数据收集口径和动作指令要求,确保使用一套衡量标准来评估人效指标。
优化业务流程,更新技术手段:根据不同公司的情况和项目规模,控制费用标准。基于费用标准调整业务流程,以及更新相应技术手段。例如利用自动化门岗和监控数字化系统、利用排班系统等。
岗位合并管理,实现一岗多能:根据人力和业务需求优化岗位技能要求,让员工一岗多能,可通过智能排班工具将多技能员工共享至不同岗位,让员工在不同时段做不同的事情,充分发挥员工潜力。
业务模式变革,灵活用工管理:根据实际业务量,尝试采用兼职或零工人员,通过派单的方式来灵活管理员工,从业务的角度来寻求用工模式的变革方法,确保用工合规的同时,人员配置也能充分满足业务需求。
 △
盖雅工场利事事业部副总裁 刘
建鑫
△
盖雅工场利事事业部副总裁 刘
建鑫
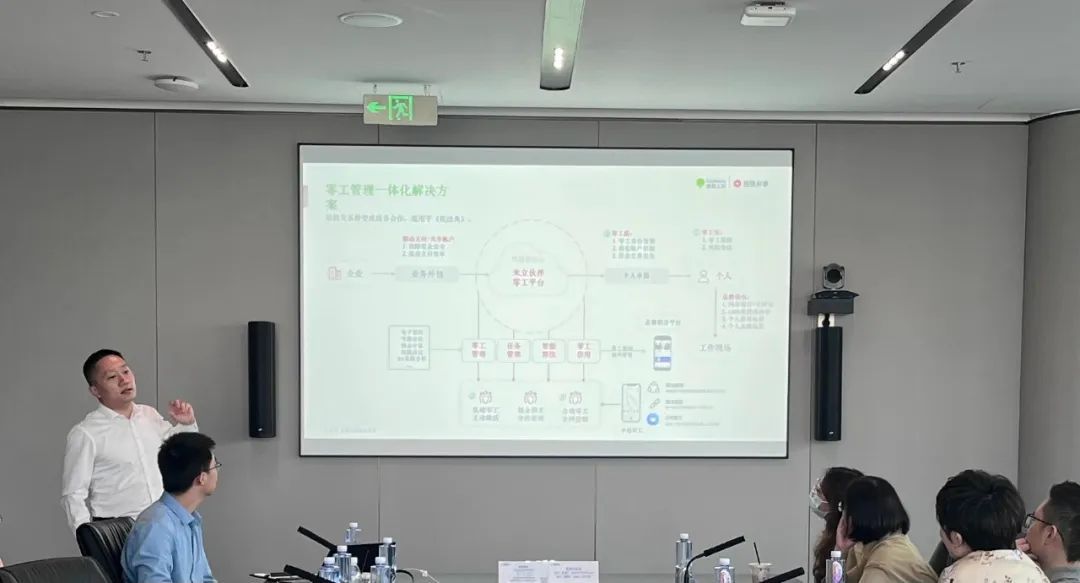
在针对如何通过灵活用工实现降本增效时,盖雅工场利事事业部副总裁刘建鑫分享了以下场景及建议:
全职员工兼职化,兼职员工共享化:通过零工平台实现不同子品牌和不同区域人员共享,也可以通过业务外包的方式将任务分包给个人。例如,某企业会通过零工平台定期给离职员工推送任务,如该离职员工感兴趣,也可以以零工身份接受该任务。
零工合法合规,用工安全有保障:零工盾可根据零工身份证号校验零工是否存在违法记录,还可识别高危账户帮助企业保障账户安全。零工接单后,零工保险会自动购买,确保零工的用工安全。
业务高峰期,快速匹配零工资源:企业私域零工,可通过盖雅零工平台线上统一管理,激活私域零工资源。社会公域零工,盖雅拥有大量招聘渠道及资源,帮助企业快速找寻合适人选。
工时实时分析,工资当日到账:零工平台可帮助企业了解零工的计划工时和实际工时利用率,从各个维度进行人效数据分析,企业可基于零工实际的工时,实现日薪发放,让员工可当日领取到自己的薪资,从而提升员工积极性。
本次人效提升专场沙龙提供了一个广泛交流和分享经验的平台,与会企业代表深入交流了彼此人效提升的实践,总结了人效提升方法论和关键指标对标,为下一步各自企业人效提升计划查漏补缺。盖雅将继续与行业领先企业合办更多类似活动,共同促进行业进步与创新,推动人效提升。