宿迁市建设局投诉网站首页鄂州网格员招聘
一、AI创作系统
SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统,支持OpenAI GPT全模型+国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!SparkAi程序使用Nestjs和Vue3框架技术,持续集成AI能力到AIGC系统。
AI模型提问:
大模型开关:
AI绘画:
1.1 程序核心功能
支持OpenAI GPT全模型+国内AI全模型(已上线!)
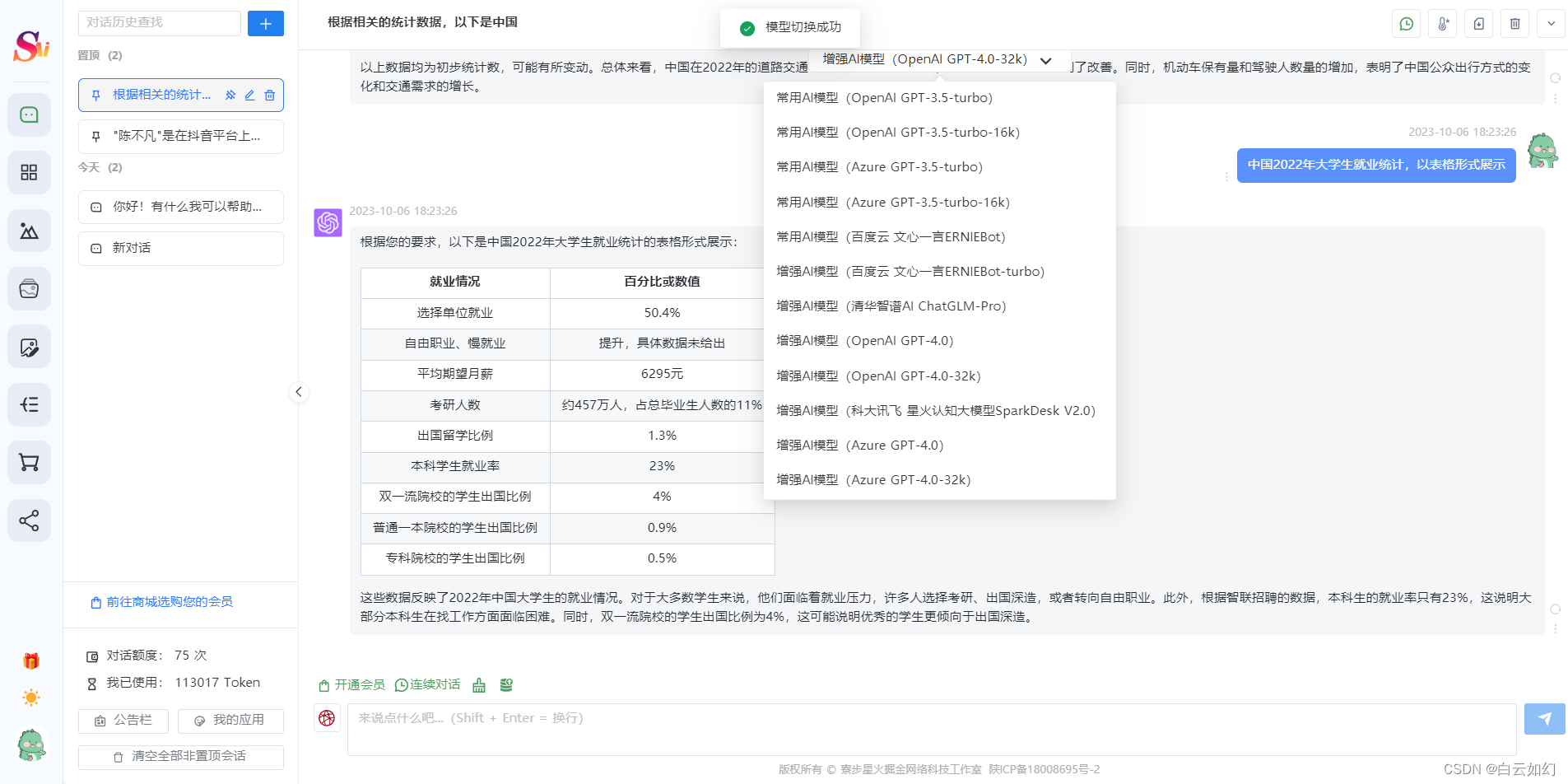
- AI提问:程序已支持GPT3.5,GPT4.0提问、OpenAIGPT全模型+国内AI全模型、支持GPT联网提问
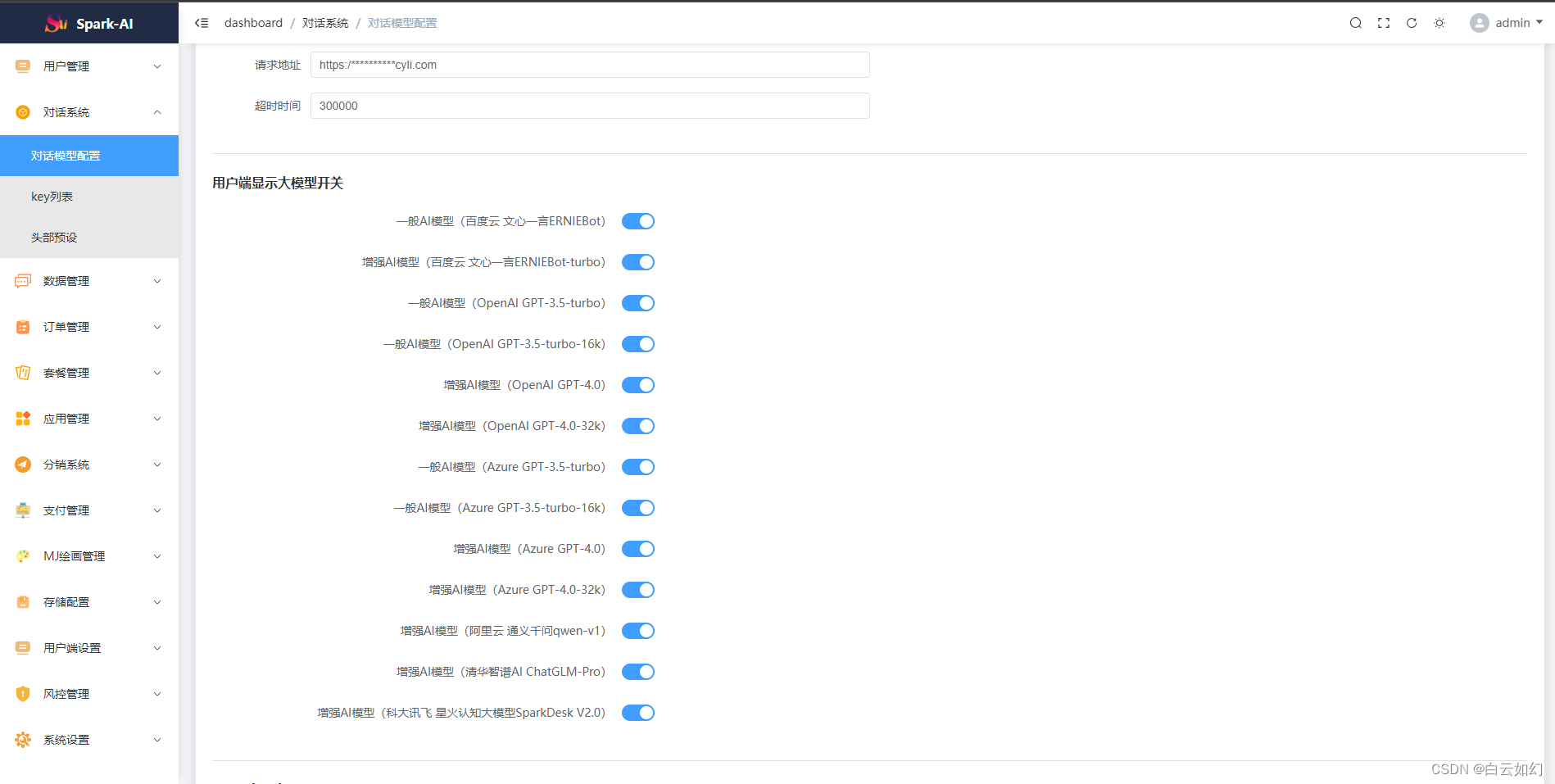
- 已支持OpenAIGPT全模型+国内AI全模型,已支持国内AI模型 百度文心一言、微软Azure、阿里云通义千问模型、清华智谱AIChatGLM、科大讯飞星火大模型等!
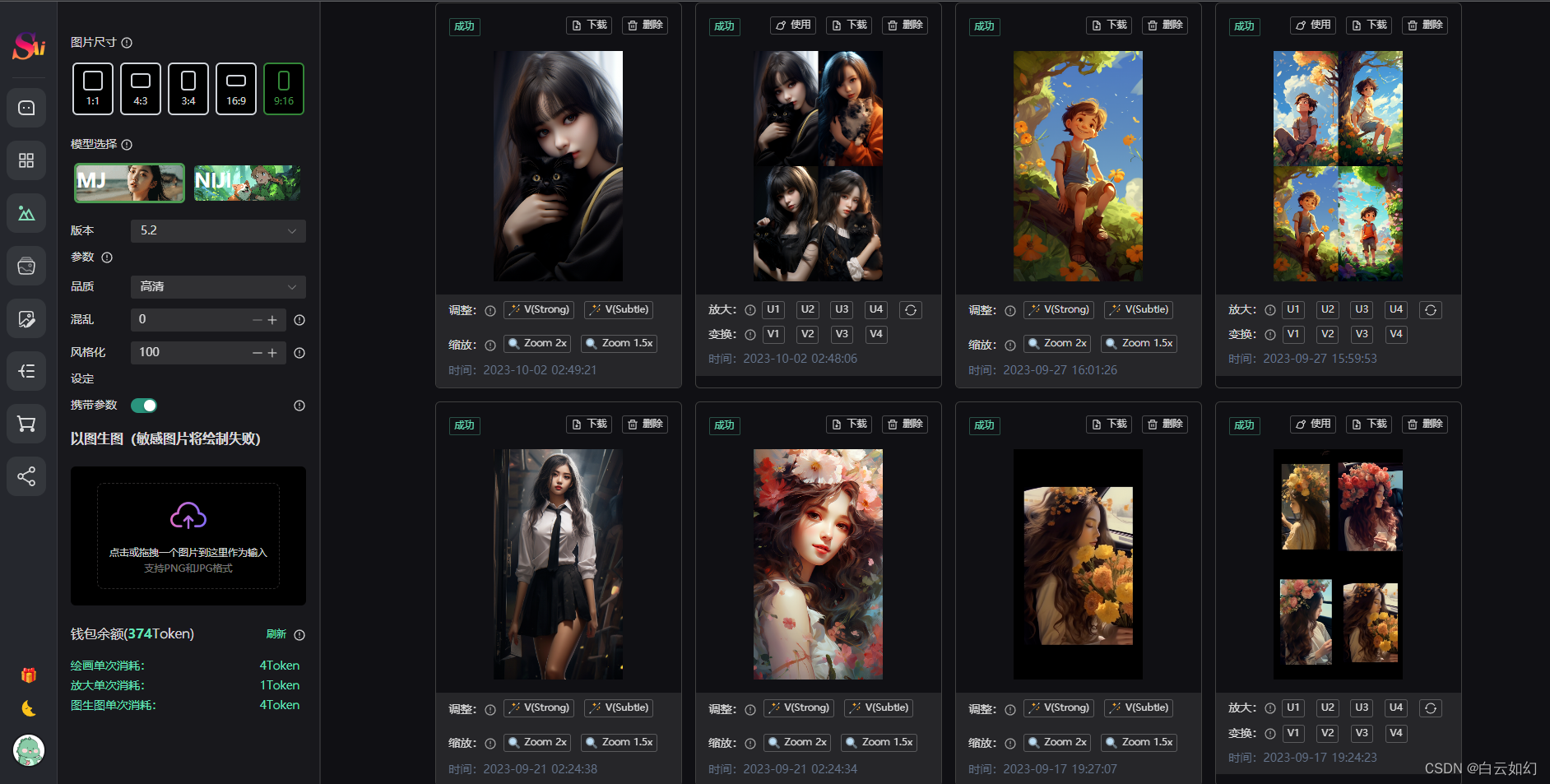
- AI绘画:Midjourney绘画(全自定义调参)、Midjourney以图生图、Dall-E2绘画
- 微信公众号+邮箱+手机号注册登录
- 一键智能思维导图生成
- 应用广场知识库,支持用户前台自定义添加私密或共享
- AI绘画广场(画廊)
- 邀请+代理分销模式
- 用户每日签到功能
- 会话记录同步保存
- 支持对接微信官方支付、易支付、码支付、虎皮椒支付等
- 自定义聚合会员套餐
- 其他核心功能
- 后续其他免费版本功能更新
1.2 更新日志
SparkAi系统大版本更新日志:
【V2.6.3】更新功能(10.6号更新)
重写AI对话系统:新增 国内AI全模型,已支持OpenAI GPT全模型+国内AI全模型,已支持国内AI模型 百度文心一言、微软Azure、阿里云通义千问模型、清华智谱AIChatGLM、科大讯飞星火大模型等!
新增 AI提问框工具插件:开通会员、连续对话、一键清屏、导出对话功能
分销代理新增银行卡提现渠道(微信、支付宝、银行卡)
新增Midjourney专业绘画提示词参考功能
去除游客功能:修复游客指纹ID导致后台账户明细变动查询失败和购买套餐导致一系列BUG
修复不是超级管理员(Super)可以删除订单记录的问题,即管理员(Admin)删除订单记录
UI更新等其他优化
【V2.6.2】9月核心功能更新日志
新增MJ提交绘画,中文自动翻译英文功能
优化思维导图生成逻辑,防止只生成两级大纲
修复后台关闭签到功能,手机端仍然显示bug
【V2.6.1】9月核心功能更新日志
增加访客体验功能、可配置每日未登录使用额度、注册账号可同步访客使用数据
增加后台底部自定义配置版权信息
增加虎皮椒支付自定义网关
违规敏感词检测记录功能
【V2.6.0】8月核心功能更新日志
优化key池额度耗尽锁定逻辑
优化MJ绘画连接、优化CSS、部分页面样式修改
增加手机端签到领取免费次数功能、优化后台总计绘画数量逻辑
新增 MJ 官方图片重新生成指令功能
同步官方 Vary 指令 单张图片对比加强 Vary(Strong) | Vary(Subtle)
同步官方 Zoom 指令 单张图片无限缩放 Zoom out 2x | Zoom out 1.5x
二、系统模块演示
https://ai.idcyli.com
三、系统功能模块
3.1 AI模型提问
支持GPT联网提问
3.2 Prompt应用
3.2.1 Prompt应用广场
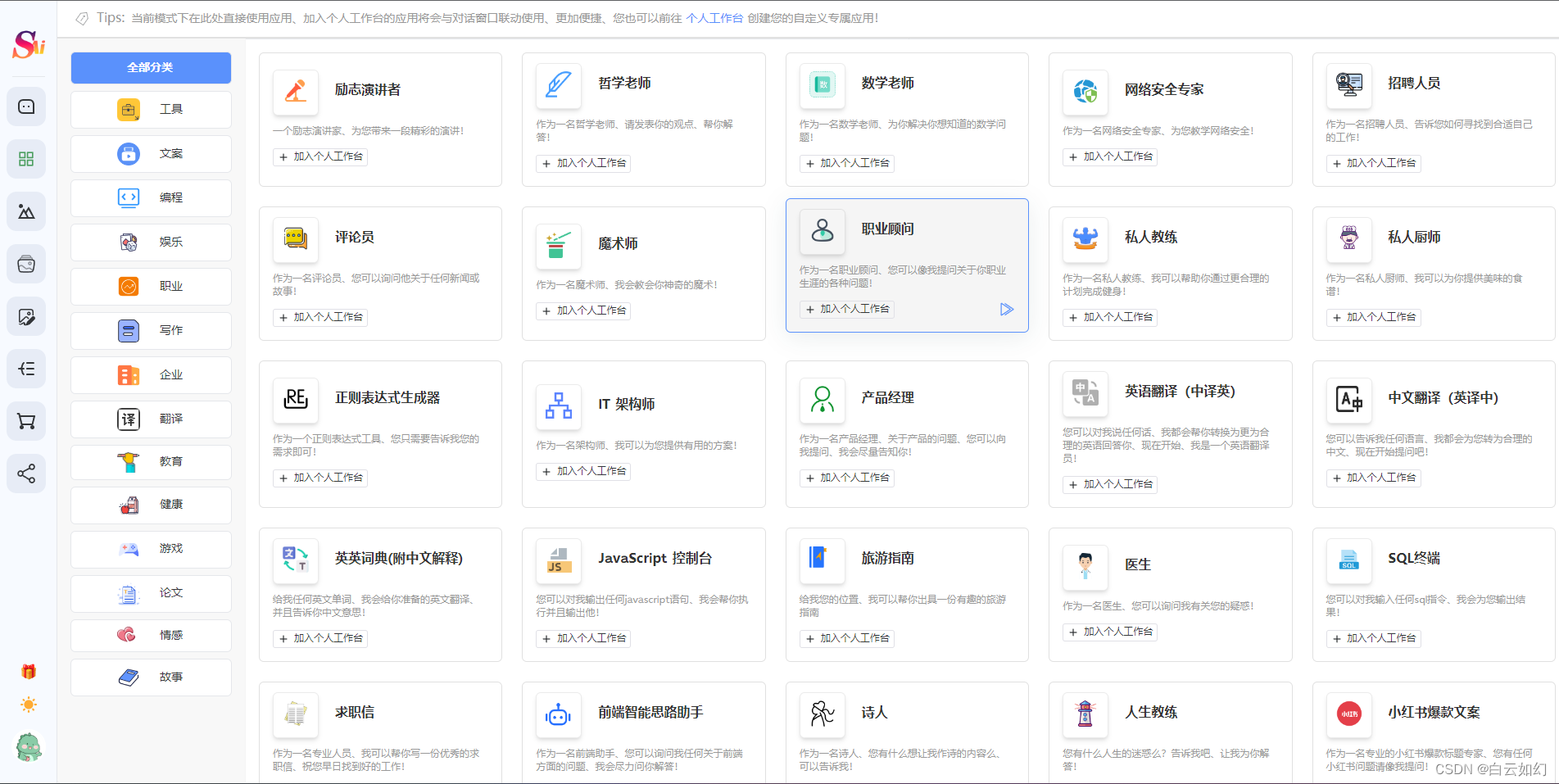
3.2.2 支持用户自定义Prompt
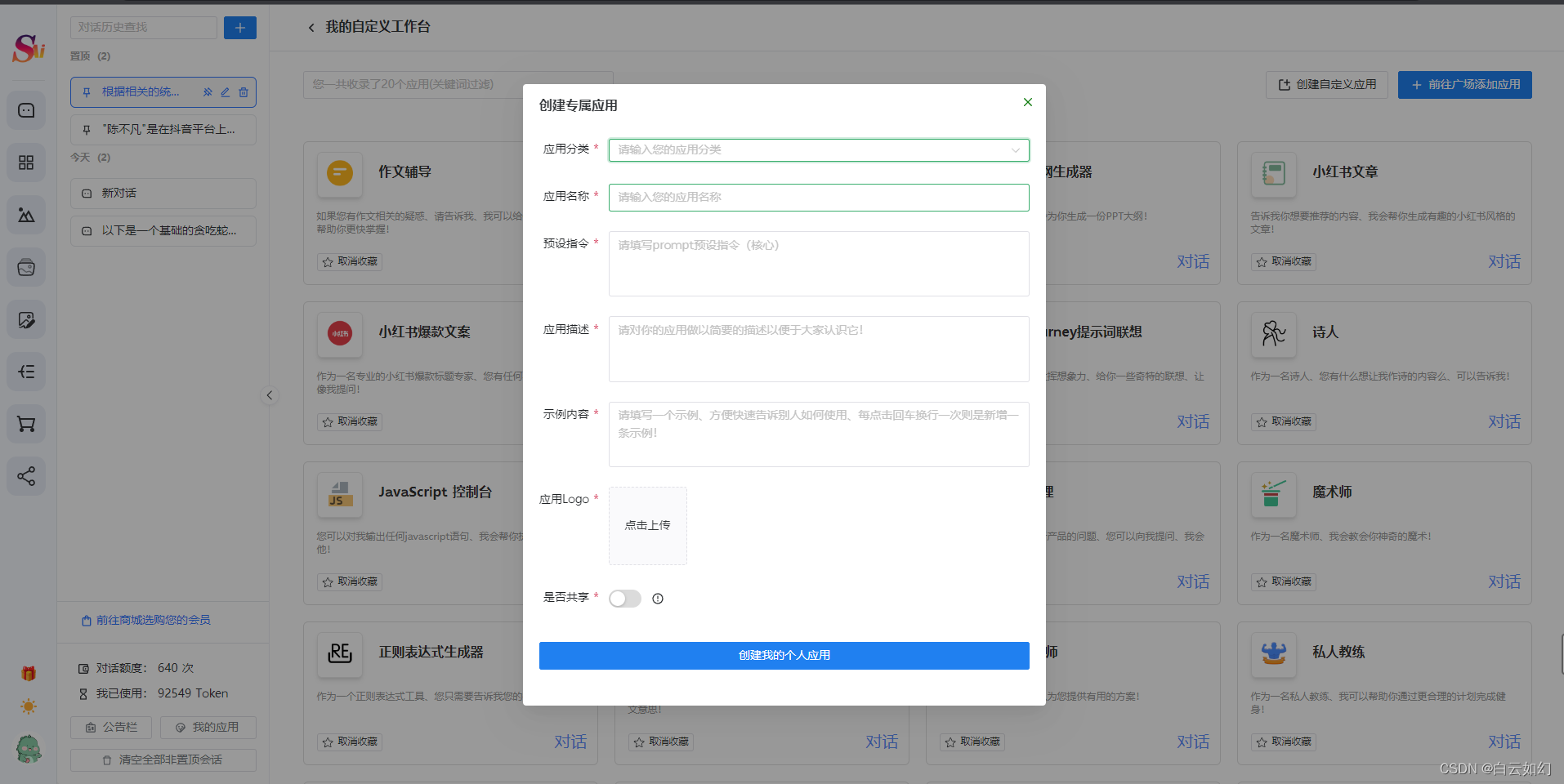
3.3 Midjourney专业绘画
-
支持同步官方图片重新生成指令
-
同步官方 Vary 指令 单张图片对比加强 Vary(Strong) | Vary(Subtle)
-
同步官方 Zoom 指令 单张图片无限缩放 Zoom out 2x | Zoom out 1.5x
3.3.1 文生图
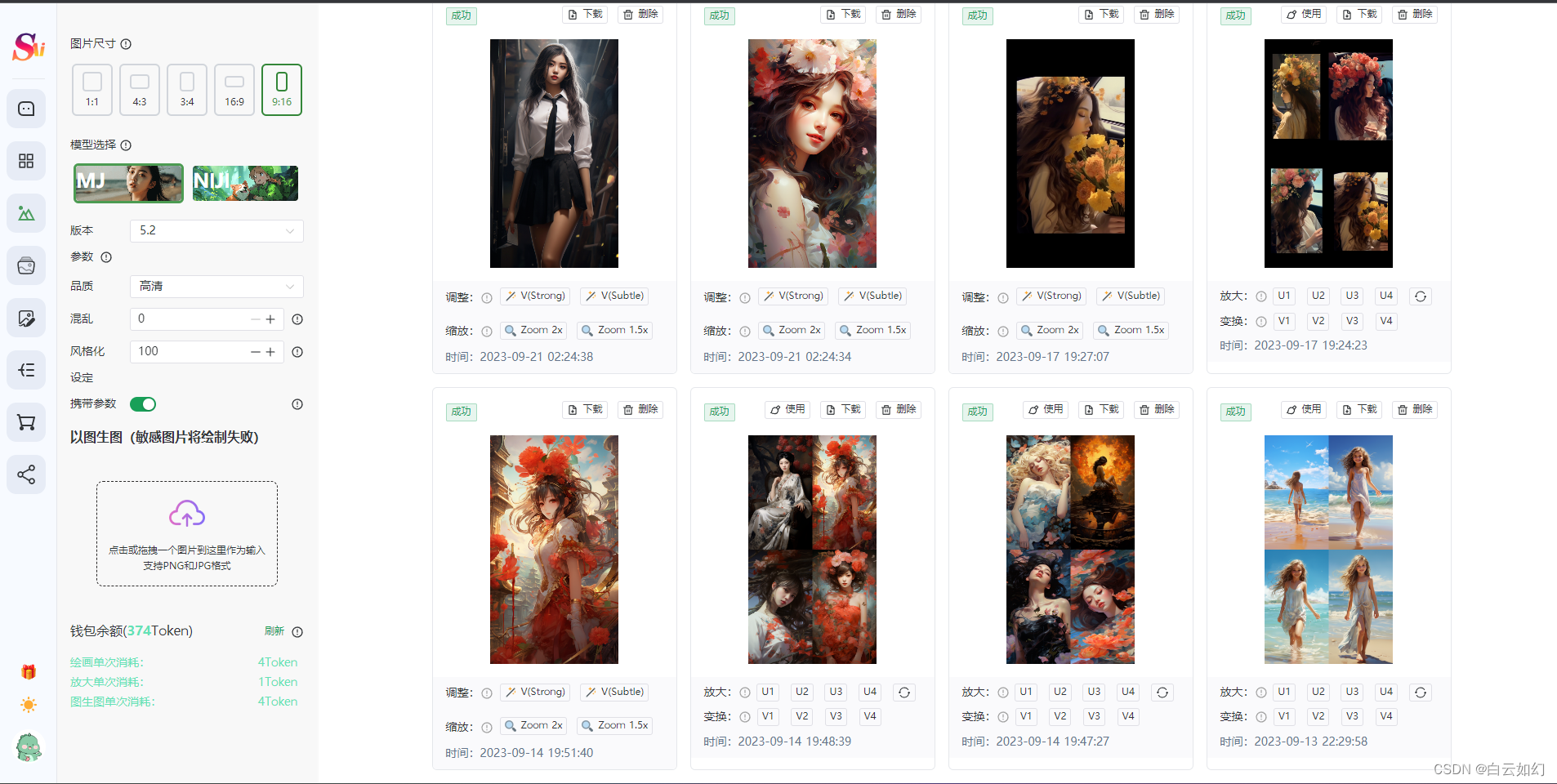
3.3.2 以图生图
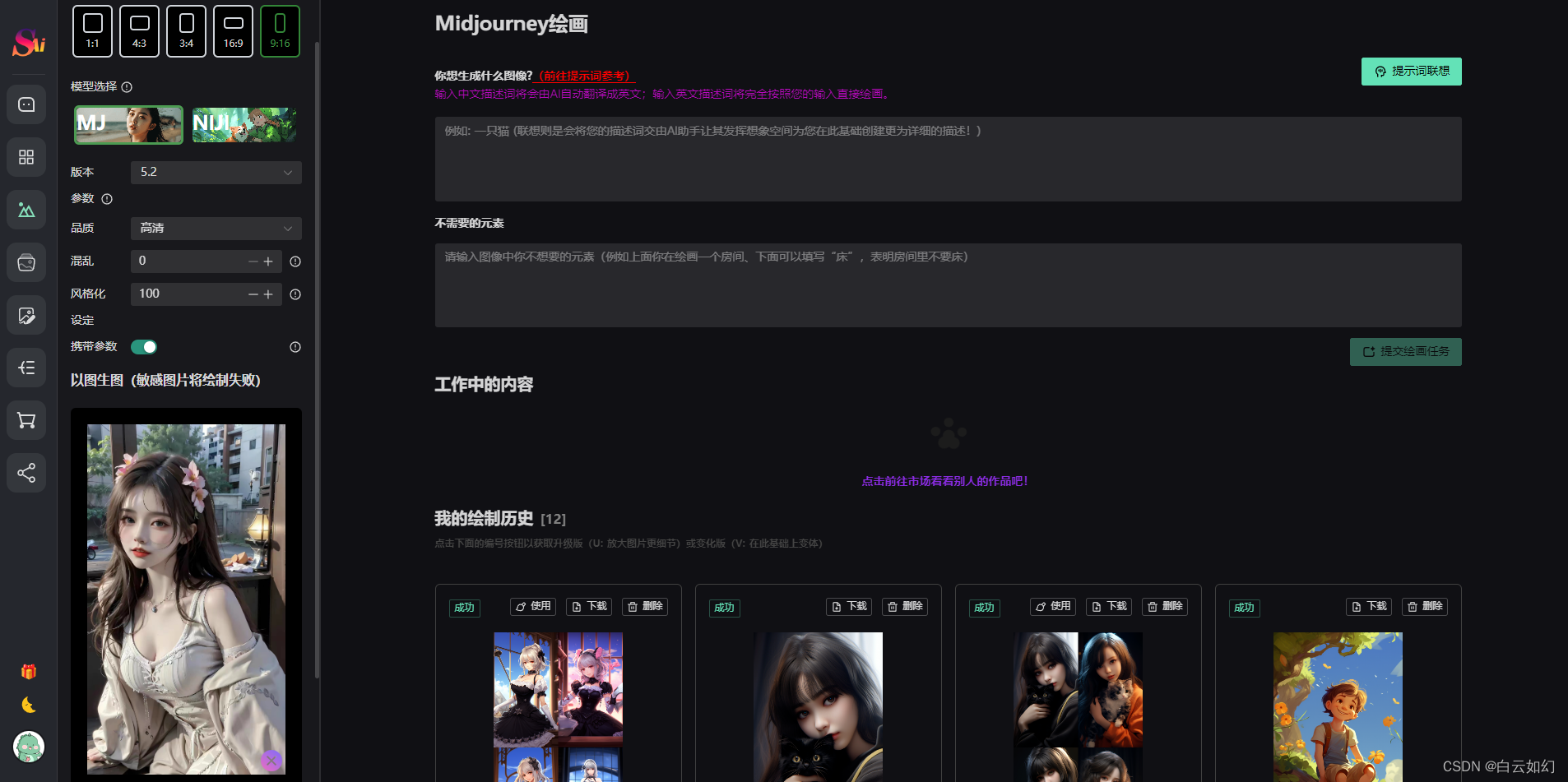
3.4 Dall-E2绘画

3.5 Mind思维导图生成
3.6 AI画廊

四、SparkAi系统介绍
本系统使用Nestjs和Vue3框架技术,持续集成AI能力到本系统!
4.1 前台演示站点
系统演示站点:https://ai.idcyli.com
4.2演示后台站点
-
演示系统后台:Spark-AI
-
演示后台账号密码:admin,123456
4.3 SparkAi源码下载
-
SparkAi-点击下载(https://pan.baidu.com/s/1_jnAsU_aC_i_mWSjIfyQgw?pwd=vw0o)
4.4 原文详细部署教程
SparkAi系统部署搭建文档SparkAi系统部署搭建文档https://www.idcyli.com/33.html
五、搭建部署教程
以下教程使用宝塔搭建!
5.1基础env环境配置
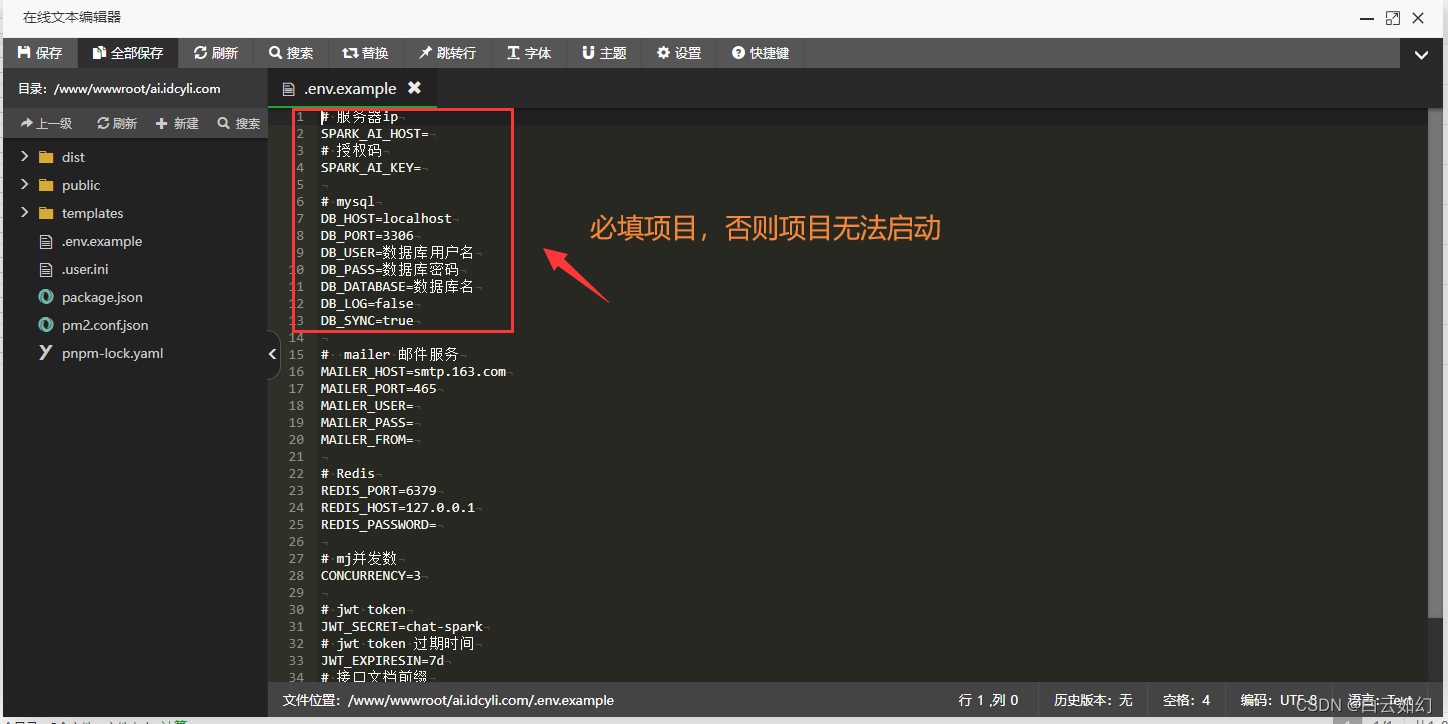
在代码中我们提供了基础 环境变量文件配置文件env.example,使用前先去掉后缀改为.env文件即可,我们在env环境配置文件只需要配置如下东西。
-
授权码授权ip配置
-
邮件服务配置
-
mysql数据库 这三项是基础配置、mysql与授权是必须的、在配置mysql与授权的情况下项目才可以启动成功、邮件服务可以后续追加。
5.2 env文件代码
# 服务器ip
SPARK_AI_HOST=
# 授权码
SPARK_AI_KEY=# mysql
DB_HOST=localhost
DB_PORT=3306
DB_USER=数据库用户名
DB_PASS=数据库密码
DB_DATABASE=数据库名
DB_LOG=false
DB_SYNC=true# mailer 邮件服务
MAILER_HOST=smtp.163.com
MAILER_PORT=465
MAILER_USER=发信邮箱
MAILER_PASS=邮箱发信密钥
MAILER_FROM=发信邮箱# Redis
REDIS_PORT=6379
REDIS_HOST=127.0.0.1
REDIS_PASSWORD=# mj并发数
CONCURRENCY=3# jwt token
JWT_SECRET=chat-spark
# jwt token 过期时间
JWT_EXPIRESIN=7d
# 自定义端口
PORT=9520
六、环境安装
系统所需环境:
-
Nginx >= 1.19.8
-
MySQL >= 5.7或者MySQL 8.0
-
PHP-7.4
-
PM2管理器 5.5
-
Redis 7.0.11
-
Node版本:>=16.19.1