医生在线咨询优化设计四年级上册数学答案

- 0 前言
- 1 df命令的功能、格式和选项说明
-
- 1.1 df命令的功能
- 1.2 df命令的格式
- 1.3 df命令选项说明
- 2 df命令使用实例
-
- 2.1 df:显示主要文件系统信息
- 2.2 df -a:显示所有文件系统信息
- 2.3 df -t[=]TYPE或--type[=]TYPE:显示TYPE指定类型的文件系统信息
- 2.4 df --total:追加显示统计信息
- 2.5 df -l 或 --local:只显示本地文件系统信息
- 2.6 df -B[=]SIZE或--block-size[=]SIZE:按按 SIZE指定的单位来打印大小信息
- 2.7 df -h或--human-readable:以人类可读格式打印尺寸
- 2.8 df -i或--inodes: 列出索引节点而不是块使用情况信息
- 2.9 df-T或--print-type:打印文件系统类型
- 2.10 df -P或--portability:使用 POSIX 输出格式
- 2.11 df -x=TYPE或--exclude-type=TYPE:显示非TYPE指定类型的文件系统信息
0 前言
说到DF,你最先想起的是啥呢?
我最选想来的是以前玩过的由 NovaLogic 开发和出版的一款第一人称射击游戏,名字是《Delta Force | 三角洲特种部队》,简写就是DF,启动游戏的文件是df.exe。
那么,在Linux中,df命令的功能是什么呢?
1 df命令的功能、格式和选项说明
我们可以使用 help def命令查看 df命令的帮助信息。
purpleEndurer @ bash ~ $df --help
Usage: df [OPTION]... [FILE]...
Show information about the file system on which each FILE resides,
or all file systems by default.Mandatory arguments to long options are mandatory for short options too.
-a, --all include pseudo, duplicate, inaccessible file systems
-B, --block-size=SIZE scale sizes by SIZE before printing them; e.g.,
'-BM' prints sizes in units of 1,048,576 bytes;
see SIZE format below
--direct show statistics for a file instead of mount point
--total produce a grand total
-h, --human-readable print sizes in human readable format (e.g., 1K 234M 2G)
-H, --si likewise, but use powers of 1000 not 1024
-i, --inodes list inode information instead of block usage
-k like --block-size=1K
-l, --local limit listing to local file systems
--no-sync do not invoke sync before getting usage info (default)
--output[=FIELD_LIST] use the output format defined by FIELD_LIST,
or print all fields if FIELD_LIST is omitted.
-P, --portability use the POSIX output format
--sync invoke sync before getting usage info
-t, --type=TYPE limit listing to file systems of type TYPE
-T, --print-type print file system type
-x, --exclude-type=TYPE limit listing to file systems not of type TYPE
-v (ignored)
--help display this help and exit
--version output version information and exitDisplay values are in units of the first available SIZE from --block-size,
and the DF_BLOCK_SIZE, BLOCK_SIZE and BLOCKSIZE environment variables.
Otherwise, units default to 1024 bytes (or 512 if POSIXLY_CORRECT is set).SIZE is an integer and optional unit (example: 10M is 10*1024*1024). Units
are K, M, G, T, P, E, Z, Y (powers of 1024) or KB, MB, ... (powers of 1000).FIELD_LIST is a comma-separated list of columns to be included. Valid
field names are: 'source', 'fstype', 'itotal', 'iused', 'iavail', 'ipcent',
'size', 'used', 'avail', 'pcent', 'file' and 'target' (see info page).GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
Report df translation bugs to <http://translationproject.org/team/>
For complete documentation, run: info coreutils 'df invocation'

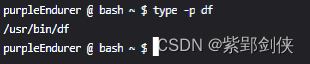
1.1 df命令的功能
df命令是一个外部命令,其功能是显示有关每个 指定FILE 所在的文件系统的信息,或者默认显示所有文件系统的信息。
purpleEndurer @ bash ~ $ type -p df
/usr/bin/df
purpleEndurer @ bash ~ $
1.2 df命令的格式
df [选项]... [文件]...
1.3 df命令选项说明
| 选项 | 功能 |
|---|---|
| -a或--all | 显示所有系统,包括虚拟(伪)、重定向、不可访问的文件系统 |
| -B[=]SIZE或--block-size=SIZE | 按 SIZE指定的单位来打印大小信息 SIZE 包括一个整数和可选单位K、M、G、T、P、E、Z、Y(1024 的幂)或 KB、MB、...(1000 的幂)。 例如: -BM 以1024*1024 = 1,048,576 字节为单位来打印 -B10M 是以 10*1024*1024 = 10,485,760 字节为单位来打印 |
| --direc | 显示文件而不是挂载点统计信息 |
| --total | 追加显示统计信息 |
| -h或--human-readable | 以人类可读格式打印尺寸(例如,1K 234M 2G) |
| -H或--si | 使用 1000 的幂而不是 1024 的幂 |
| -i或--inodes | 列出 索引节点 信息而不是块使用情况。 |
| -k | 类似--block-size=1K |
| -l或--local | 只显示本地文件系统 |
| --no-sync | 在获取使用情况信息之前不调用同步(默认) |
| --output[=FIELD_LIST] | 使用FIELD_LIST定义的输出格式,如果省略FIELD_LIST则打印所有字段。 |
| -P或--portability | 使用 POSIX 输出格式 |
| --sync | 在获取使用情况信息之前调用同步 |
| -t[=]TYPE或--type[=]TYPE | 显示TYPE 指定类型的文件系统信息 |
| -T或--print-type | 打印文件系统类型 |
| -x=TYPE或--exclude-type=TYPE | 显示非指定 TYPE 类型的文件系统信息 |
| -v | (忽略) |
| --help | 显示此帮助并退出 |
| --version | 输出版本信息并退出 |
2 df命令使用实例
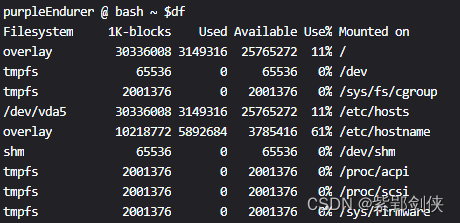
2.1 df:显示主要文件系统信息
purpleEndurer @ bash ~ $df
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 30336008 3149316 25765272 11% /
tmpfs 65536 0 65536 0% /dev
tmpfs 2001376 0 2001376 0% /sys/fs/cgroup
/dev/vda5 30336008 3149316 25765272 11% /etc/hosts
overlay 10218772 5892684 3785416 61% /etc/hostname
shm 65536 0 65536 0% /dev/shm
tmpfs 2001376 0 2001376 0% /proc/acpi
tmpfs 2001376 0 2001376 0% /proc/scsi
tmpfs 2001376 0 2001376 0% /sys/firmware
overlayfs文件系统是一种堆叠文件系统,可以将多个目录的内容叠加到另一个目录上,不影响磁盘空间结构。
默认的Linux发行版中的内核配置都会开启tmpfs,并映射到了/dev/shm目录。
/dev/shm/这个目录不在硬盘上,而是在内存里。
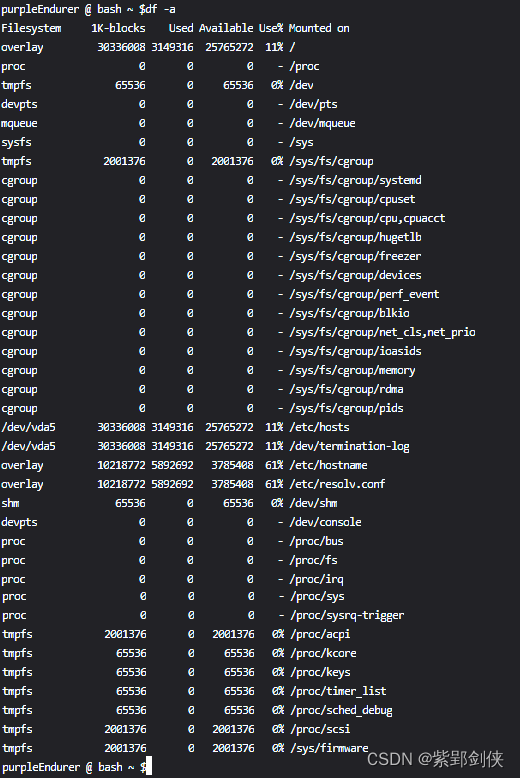
2.2 df -a:显示所有文件系统信息
purpleEndurer @ bash ~ $df -a
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 30336008 3149316 25765272 11% /
proc 0 0 0 - /proc
tmpfs 65536 0 65536 0% /dev
devpts 0 0 0 - /dev/pts
mqueue 0 0 0 - /dev/mqueue
sysfs 0 0 0 - /sys
tmpfs 2001376 0 2001376 0% /sys/fs/cgroup
cgroup 0 0 0 - /sys/fs/cgroup/systemd
cgroup 0 0 0 - /sys/fs/cgroup/cpuset
cgroup 0 0 0 - /sys/fs/cgroup/cpu,cpuacct
cgroup 0 0 0 - /sys/fs/cgroup/hugetlb
cgroup 0 0 0 - /sys/fs/cgroup/freezer
cgroup 0 0 0 - /sys/fs/cgroup/devices
cgroup 0 0 0 - /sys/fs/cgroup/perf_event
cgroup 0 0 0 - /sys/fs/cgroup/blkio
cgroup 0 0 0 - /sys/fs/cgroup/net_cls,net_prio
cgroup 0 0 0 - /sys/fs/cgroup/ioasids
cgroup 0 0 0 - /sys/fs/cgroup/memory
cgroup 0 0 0 - /sys/fs/cgroup/rdma
cgroup 0 0 0 - /sys/fs/cgroup/pids
/dev/vda5 30336008 3149316 25765272 11% /etc/hosts
/dev/vda5 30336008 3149316 25765272 11% /dev/termination-log
overlay 10218772 5892692 3785408 61% /etc/hostname
overlay 10218772 5892692 3785408 61% /etc/resolv.conf
shm 65536 0 65536 0% /dev/shm
devpts 0 0 0 - /dev/console
proc 0 0 0 - /proc/bus
proc 0 0 0 - /proc/fs
proc 0 0 0 - /proc/irq
proc 0 0 0 - /proc/sys
proc 0 0 0 - /proc/sysrq-trigger
tmpfs 2001376 0 2001376 0% /proc/acpi
tmpfs 65536 0 65536 0% /proc/kcore
tmpfs 65536 0 65536 0% /proc/keys
tmpfs 65536 0 65536 0% /proc/timer_list
tmpfs 65536 0 65536 0% /proc/sched_debug
tmpfs 2001376 0 2001376 0% /proc/scsi
tmpfs 2001376 0 2001376 0% /sys/firmware
purpleEndurer @ bash ~ $
proc是一种伪文件系统(也即虚拟文件系统),它存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。
devpts是一个虚拟文件系统,用于实现终端设备的动态分配和管理。
mqueue是Linux进程间通信-消息队列。
sysfs 是一个伪文件系统,用于对具体的内核对象(例如物理设备)进行建模,并提供一种将设备和设备驱动程序关联起来的方法。
cgroups(Control Groups),是Linux内核提供的物理资源隔离机制,通过这种机制,可以实现对Linux进程或者进程组的资源限制、隔离和统计功能。
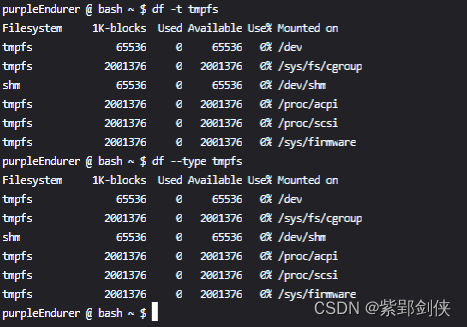
2.3 df -t[=]TYPE或--type[=]TYPE:显示TYPE指定类型的文件系统信息
显示 tmpfs类型的文件系统信息:
purpleEndurer @ bash ~ $ df -t tmpfs
Filesystem 1K-blocks Used Available Use% Mounted on
tmpfs 65536 0 65536 0% /dev
tmpfs 2001376 0 2001376 0% /sys/fs/cgroup
shm 65536 0 65536 0% /dev/shm
tmpfs 2001376 0 2001376 0% /proc/acpi
tmpfs 2001376 0 2001376 0% /proc/scsi
tmpfs 2001376 0 2001376 0% /sys/firmware
purpleEndurer @ bash ~ $ df --type tmpfs
Filesystem 1K-blocks Used Available Use% Mounted on
tmpfs 65536 0 65536 0% /dev
tmpfs 2001376 0 2001376 0% /sys/fs/cgroup
shm 65536 0 65536 0% /dev/shm
tmpfs 2001376 0 2001376 0% /proc/acpi
tmpfs 2001376 0 2001376 0% /proc/scsi
tmpfs 2001376 0 2001376 0% /sys/firmware
purpleEndurer @ bash ~ $
2.4 df --total:追加显示统计信息
显示 tmpfs类型的文件系统信息及统计信息:
purpleEndurer @ bash ~ $ df -t tmpfs --total
Filesystem 1K-blocks Used Available Use% Mounted on
tmpfs 65536 0 65536 0% /dev
tmpfs 2001376 0 2001376 0% /sys/fs/cgroup
shm 65536 0 65536 0% /dev/shm
tmpfs 2001376 0 2001376 0% /proc/acpi
tmpfs 2001376 0 2001376 0% /proc/scsi
tmpfs 2001376 0 2001376 0% /sys/firmware
total 8136576 0 8136576 0% -
purpleEndurer @ bash ~ $

命令执行结果末尾增加了一行统计信息:
total 8136576 0 8136576 0% -
2.5 df -l 或 --local:只显示本地文件系统信息
purpleEndurer @ bash ~ $ df -l
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 30336008 3149440 25765148 11% /
tmpfs 65536 0 65536 0% /dev
tmpfs 2001376 0 2001376 0% /sys/fs/cgroup
/dev/vda5 30336008 3149440 25765148 11% /etc/hosts
overlay 10218772 5892672 3785428 61% /etc/hostname
shm 65536 0 65536 0% /dev/shm
tmpfs 2001376 0 2001376 0% /proc/acpi
tmpfs 2001376 0 2001376 0% /proc/scsi
tmpfs 2001376 0 2001376 0% /sys/firmware
purpleEndurer @ bash ~ $

2.6 df -B[=]SIZE或--block-size[=]SIZE:按按 SIZE指定的单位来打印大小信息
分别以 M 和 10M为单位显示 tmpfs类型的文件系统信息
purpleEndurer @ bash ~ $ df -t tmpfs -BM
Filesystem 1M-blocks Used Available Use% Mounted on
tmpfs 64M 0M 64M 0% /dev
tmpfs 1955M 0M 1955M 0% /sys/fs/cgroup
shm 64M 0M 64M 0% /dev/shm
tmpfs 1955M 0M 1955M 0% /proc/acpi
tmpfs 1955M 0M 1955M 0% /proc/scsi
tmpfs 1955M 0M 1955M 0% /sys/firmware
purpleEndurer @ bash ~ $ df -t tmpfs -B10M
Filesystem 10M-blocks Used Available Use% Mounted on
tmpfs 7 0 7 0% /dev
tmpfs 196 0 196 0% /sys/fs/cgroup
shm 7 0 7 0% /dev/shm
tmpfs 196 0 196 0% /proc/acpi
tmpfs 196 0 196 0% /proc/scsi
tmpfs 196 0 196 0% /sys/firmware
purpleEndurer @ bash ~ $

2.7 df -h或--human-readable:以人类可读格式打印尺寸
以人类可读格式显示tmpfs类型的文件系统信息
purpleEndurer @ bash ~ $ df -t tmpfs -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 64M 0 64M 0% /dev
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
shm 64M 0 64M 0% /dev/shm
tmpfs 2.0G 0 2.0G 0% /proc/acpi
tmpfs 2.0G 0 2.0G 0% /proc/scsi
tmpfs 2.0G 0 2.0G 0% /sys/firmware
purpleEndurer @ bash ~ $

2.8 df -i或--inodes: 列出索引节点而不是块使用情况信息
显示tmpfs类型的文件系统索引节点信息
purpleEndurer @ bash ~ $ df -t tmpfs -i
Filesystem Inodes IUsed IFree IUse% Mounted on
tmpfs 500345 18 500327 1% /dev
tmpfs 500345 18 500327 1% /sys/fs/cgroup
shm 500345 1 500344 1% /dev/shm
tmpfs 500345 1 500344 1% /proc/acpi
tmpfs 500345 1 500344 1% /proc/scsi
tmpfs 500345 1 500344 1% /sys/firmware
purpleEndurer @ bash ~ $

可以看到,命令返回信息中:
第2列是Inodes而不是Size
第3列是Iused而不是Used
第5列是是IUse%而不是Use%.
2.9 df-T或--print-type:打印文件系统类型
显示tmpfs类型的文件系统包括系统类型的信息
purpleEndurer @ bash ~ $ df -t tmpfs -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
tmpfs tmpfs 65536 0 65536 0% /dev
tmpfs tmpfs 2001380 0 2001380 0% /sys/fs/cgroup
shm tmpfs 65536 0 65536 0% /dev/shm
tmpfs tmpfs 2001380 0 2001380 0% /proc/acpi
tmpfs tmpfs 2001380 0 2001380 0% /proc/scsi
tmpfs tmpfs 2001380 0 2001380 0% /sys/firmware

命令返回信息中增加了第2列Type。
可见/dev/shm也是tmpfs类型的文件系统。
显示本地文件系统包括系统类型的信息
purpleEndurer @ bash ~ $ df -l -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
overlay overlay 30336008 3149388 25765200 11% /
tmpfs tmpfs 65536 0 65536 0% /dev
tmpfs tmpfs 2001380 0 2001380 0% /sys/fs/cgroup
/dev/vda5 ext4 30336008 3149388 25765200 11% /etc/hosts
overlay overlay 10218772 5892484 3785616 61% /etc/hostname
shm tmpfs 65536 0 65536 0% /dev/shm
tmpfs tmpfs 2001380 0 2001380 0% /proc/acpi
tmpfs tmpfs 2001380 0 2001380 0% /proc/scsi
tmpfs tmpfs 2001380 0 2001380 0% /sys/firmware

可见/dev/vda5其实是ext4文件系统。
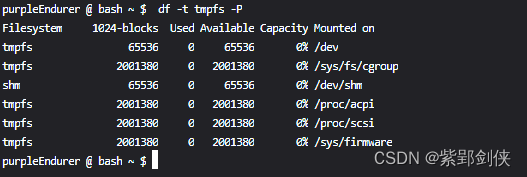
2.10 df -P或--portability:使用 POSIX 输出格式
使用 POSIX 输出格式显示tmpfs类型的文件系统信息
purpleEndurer @ bash ~ $ df -t tmpfs -P
Filesystem 1024-blocks Used Available Capacity Mounted on
tmpfs 65536 0 65536 0% /dev
tmpfs 2001380 0 2001380 0% /sys/fs/cgroup
shm 65536 0 65536 0% /dev/shm
tmpfs 2001380 0 2001380 0% /proc/acpi
tmpfs 2001380 0 2001380 0% /proc/scsi
tmpfs 2001380 0 2001380 0% /sys/firmware
purpleEndurer @ bash ~ $
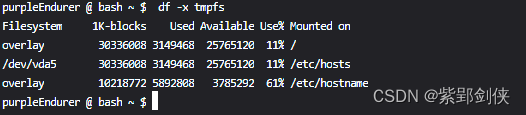
2.11 df -x=TYPE或--exclude-type=TYPE:显示非指定 TYPE 类型的文件系统信息
显示非tmpfs类型的文件系统信息
purpleEndurer @ bash ~ $ df -x tmpfs
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 30336008 3149468 25765120 11% /
/dev/vda5 30336008 3149468 25765120 11% /etc/hosts
overlay 10218772 5892808 3785292 61% /etc/hostname
purpleEndurer @ bash ~ $