wordpress会员积分充值插件酒店网站搜索引擎优化方案
功能介绍
启动界面

开始采集:
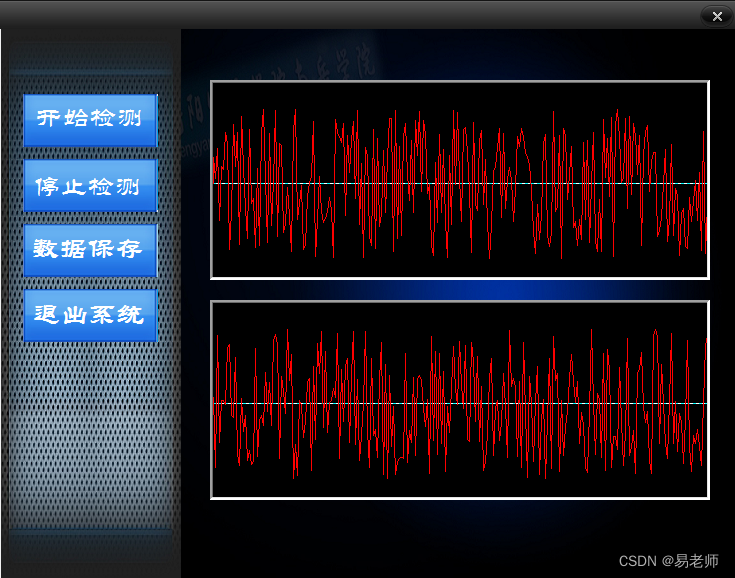
PS:不涉及 数据保存,重现等功能
界面设计
界面分为三块:顶部黑条带关闭按钮、左边对话框,右边的主界面
资源:
顶部黑条 top.bmp 2* 29 (宽 * 高 像素点)
![]()
左对话框 left.bmp

主对话框: bk.bmp

1、 顶部黑条的实现——贴图功能
主要类:CBitmap 加载图片 CRect 获取窗口大小等 CDC 绘制图片
函数:
加载图片:LoadBitmap (CBitmap成员函数,推荐) LoadImage(API函数)
获取图片属性:BITMAP 结构体 和 GetBitmap
尺寸相关:GetSystemMetrics (API函数,获取屏幕尺寸)GetClientRect (窗口类函数,获取客户区尺寸)
CDC函数:GetDC ReleaseDC 获取和释放DC CreateCompatibleDC 创建兼容DC SelectObject 选择GDI对象 BitBlt StretchBlt 贴图(后面函数可以缩放)
关于GDI和CDC
GDI是画笔、画刷、字体、图片等等
CDC是设备上下文,可以理解为人的”手“和工作区的结合——有了手才能拿起画笔、画刷等工具在指定的区域内绘图!
内存DC与显示DC
显示DC就是屏幕区,特点是所有操作都同步显示在窗口里
内存DC在可以理解为与显示DC相同的一块内存区域,它的操作不会同步显示到窗口,可以通过贴图的方式来实现把内存DC内容”粘贴“到显示DC ,从而显示内容。
具体步骤:
创建对话框类型的MFC程序(略),删除主对话框的按钮,并去掉标题栏:
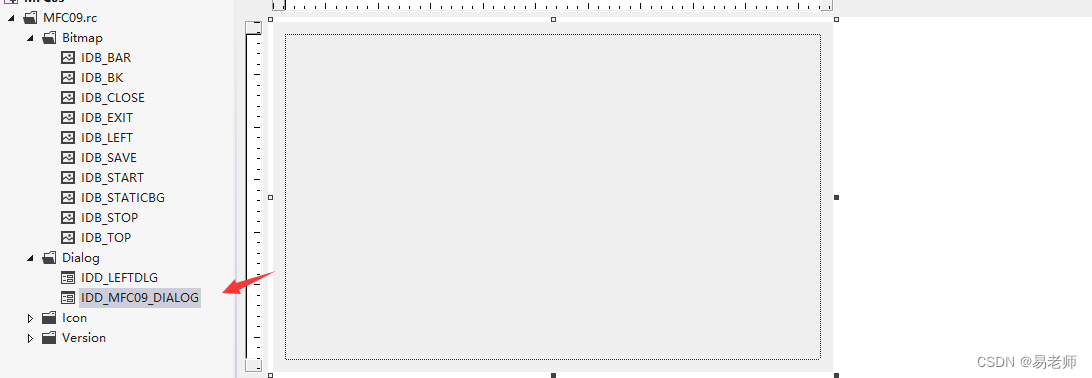
加载资源:
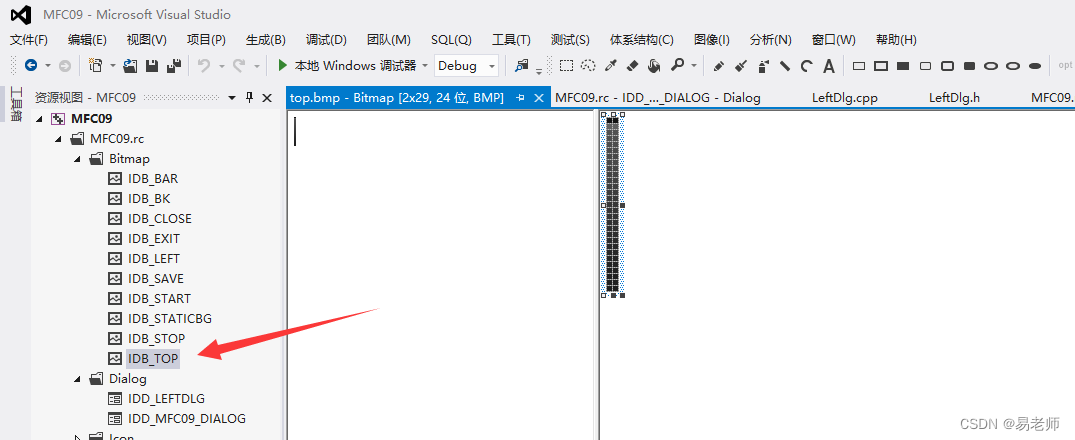
对话框类头文件中定义CBitmap实例(指针也可以,需要new)
CBitmap m_top; 和内存DC指针 CDC *mdc;
对话框CPP文件里:OnInitDialog()函数 (初始化函数,只做一次)
BOOL CMFC09Dlg::OnInitDialog()
{CDialogEx::OnInitDialog();// 设置此对话框的图标。当应用程序主窗口不是对话框时,框架将自动// 执行此操作SetIcon(m_hIcon, TRUE); // 设置大图标SetIcon(m_hIcon, FALSE); // 设置小图标// TODO: 在此添加额外的初始化代码m_top.LoadBitmap(IDB_TOP);mdc = new CDC;CDC *dc = this->GetDC();mdc->CreateCompatibleDC(dc);this->ReleaseDC(dc);return TRUE; // 除非将焦点设置到控件,否则返回 TRUE
}加载图片,创建与显示DC兼容的mdc ,记得释放DC
OnPaint() 函数(重绘消息响应函数,可能多次执行)
void CMFC09Dlg::OnPaint()
{if (IsIconic()){CPaintDC dc(this); // 用于绘制的设备上下文SendMessage(WM_ICONERASEBKGND, reinterpret_cast<WPARAM>(dc.GetSafeHdc()), 0);// 使图标在工作区矩形中居中int cxIcon = GetSystemMetrics(SM_CXICON);int cyIcon = GetSystemMetrics(SM_CYICON);CRect rect;GetClientRect(&rect);int x = (rect.Width() - cxIcon + 1) / 2;int y = (rect.Height() - cyIcon + 1) / 2;// 绘制图标dc.DrawIcon(x, y, m_hIcon);}else{CPaintDC dc(this);CRect rect;GetClientRect(&rect);mdc->SelectObject(&m_top);dc.SetStretchBltMode(STRETCH_HALFTONE);dc.StretchBlt(0,0,rect.right,30,mdc,0,0,2,29,SRCCOPY);CDialogEx::OnPaint();}
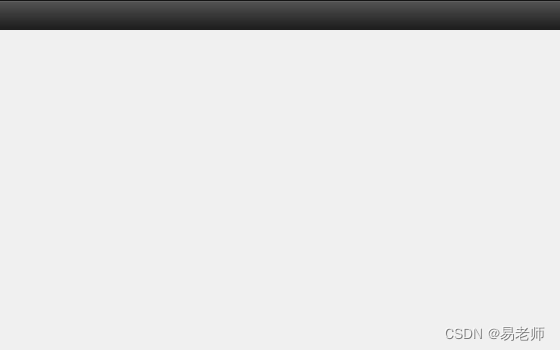
}运行后对话框的标题栏就显示出来了:
主窗口也是类似操作,合并后的代码为:
BOOL CMFC09Dlg::OnInitDialog()
{CDialogEx::OnInitDialog();// 设置此对话框的图标。当应用程序主窗口不是对话框时,框架将自动// 执行此操作SetIcon(m_hIcon, TRUE); // 设置大图标SetIcon(m_hIcon, FALSE); // 设置小图标// TODO: 在此添加额外的初始化代码m_top.LoadBitmap(IDB_TOP);m_BackGround.LoadBitmap(IDB_BK);mdc = new CDC;CDC *dc = this->GetDC();mdc->CreateCompatibleDC(dc);this->ReleaseDC(dc);return TRUE; // 除非将焦点设置到控件,否则返回 TRUE
}
void CMFC09Dlg::OnPaint()
{if (IsIconic()){CPaintDC dc(this); // 用于绘制的设备上下文SendMessage(WM_ICONERASEBKGND, reinterpret_cast<WPARAM>(dc.GetSafeHdc()), 0);// 使图标在工作区矩形中居中int cxIcon = GetSystemMetrics(SM_CXICON);int cyIcon = GetSystemMetrics(SM_CYICON);CRect rect;GetClientRect(&rect);int x = (rect.Width() - cxIcon + 1) / 2;int y = (rect.Height() - cyIcon + 1) / 2;// 绘制图标dc.DrawIcon(x, y, m_hIcon);}else{CPaintDC dc(this);CRect rect;GetClientRect(&rect);mdc->SelectObject(&m_top);dc.SetStretchBltMode(STRETCH_HALFTONE);dc.StretchBlt(0,0,rect.right,30,mdc,0,0,2,29,SRCCOPY);mdc->SelectObject(&m_BackGround);dc.StretchBlt(180,30,rect.right - 150,rect.bottom - 30,mdc,0,0,735,549,SRCCOPY);CDialogEx::OnPaint();}
}m_BackGround的定义与顶部的图片一样,在头文件中。
StretchBlt 带缩放的贴图函数,需要认真理解每个参数的意义。
运行结果:

窗口大小、位置的设置、左边对话框的实现,在后面再介绍。