服务器如何做网站资深的金融行业网站开发
文章目录
- 前言
- 一、锁
- 1.定义一个锁变量
- 2.pthread_mutex_init
- 3.pthread_mutex_destroy
- 4.pthread_mutex_lock/pthread_mutex_unlock
- 5.静态变量锁和全局变量锁的初始化
- 二、问题描述及锁的运用
- 三、RAII风格的锁
前言
临界资源: 在多个线程或进程间共享的资源.
临界区: 代码中访问临界资源的那部分代码区域.
多个线程同时访问共享数据, 其中至少一个线程进行了写操作, 且没有适当的同步机制来保护数据, 可能导致数据的不一致性, 也就是一种线程安全问题.
一、锁
多个线程同时访问共享数据, 其中至少一个线程进行了写操作, 且没有适当的同步机制来保护数据, 可能导致数据的不一致性, 对于这种问题, 可以通过加锁来解决, 加锁后, 只有申请到锁的线程才能进入临界区执行代码语句, 其他没有竞争到锁的线程会阻塞等待, 直到申请到锁的线程将锁释放, 接着各个线程再来竞争锁.
相当于被加锁的代码区域只能被各个线程串行执行.
1.定义一个锁变量
头文件: #include <pthread.h>
pthread_mutex_t mutex;
2.pthread_mutex_init
头文件: #include <pthread.h>
函数声明: int pthread_mutex_init(pthread_mutex_t *restrict mutex,const pthread_mutexattr_t *restrict attr);
- 返回值: 如果成功, 返回值为 0, 如果失败, 返回一个非零错误码.
- mutex: 指向要初始化的互斥锁的指针.
- attr: 设置互斥锁的属性, 一般传递 nullptr, 表示使用默认属性.
功能: 初始化锁.
示例代码:
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
3.pthread_mutex_destroy
头文件: #include <pthread.h>
函数声明: int pthread_mutex_destroy(pthread_mutex_t *mutex);
- 返回值: 如果成功, 返回值为 0, 如果失败, 返回一个非零错误码.
- mutex: 指向要释放的互斥锁的指针.
功能: 释放锁.
示例代码:
pthread_mutex_t mutex;
pthread_mutex_destroy(&mutex);
4.pthread_mutex_lock/pthread_mutex_unlock
头文件: #include <pthread.h>
函数声明: int pthread_mutex_lock(pthread_mutex_t *mutex); / int pthread_mutex_unlock(pthread_mutex_t *mutex);
- 返回值: 如果成功, 返回值为 0, 如果失败, 返回一个非零错误码.
- mutex: 指向已初始化的互斥锁的指针.
功能: 加锁/解锁.
示例代码:
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
pthread_mutex_lock(&mutex);
//...
pthread_mutex_unlock(&mutex);
pthread_mutex_destroy(&mutex);
在 pthread_mutex_lock(&mutex); 和 pthread_mutex_unlock(&mutex); 之间的代码就是被加锁的代码, 只有申请到锁的线程才能进入执行, 释放锁后, 各个线程再重新竞争锁.
5.静态变量锁和全局变量锁的初始化
如果锁变量是 static 修饰的静态变量锁或者是声明在全局的锁, 可以直接通过宏进行初始化:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
二、问题描述及锁的运用
假设多个线程的入口函数为同一个, 代码如下:
#include <iostream>
#include <pthread.h>
using namespace std;void* Routine(void* arg)
{int cnt = 0;for(int i = 0; i < 3; ++i){printf("线程[%lld]中的cnt: %d, 地址为: 0x%x\n", pthread_self(), ++cnt, &cnt);}cout << endl;
}int main()
{pthread_t tids[3];for(int i = 0; i < 3; ++i){pthread_create(tids + i, nullptr, Routine, nullptr);}for(int i = 0; i < 3; ++i){pthread_join(tids[i], nullptr);}return 0;
}
可以看到, 在入口函数中, 存在一个变量 cnt, 那么多个线程的入口函数都是同一个, 每个线程都对该入口函数里的 cnt 进行累加操作, 是否会出现线程安全问题呢?
运行结果:
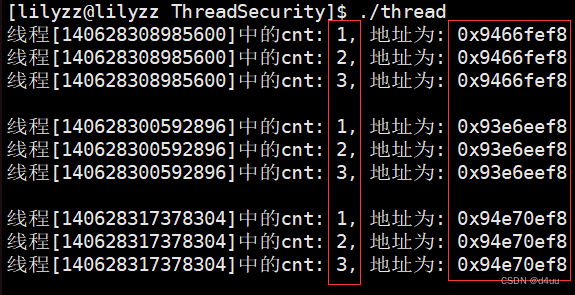
这里是不存在线程安全问题的, 因为每个线程在线程库中都存在自己的结构及数据上下文:

所以在入口函数中的变量等数据都是每个线程私有的一部分, 因此并不会有线程安全问题.
但是如果是全局变量或者被 static 修饰的变量, 被多个线程同时访问修改时就会存在线程安全问题, 假设一个场景: 三个线程进行"抢票", 即对全局变量 tickets 进行减减操作, 代码如下:
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <pthread.h>
using namespace std;int tickets = 30; //总票数void* Ticket(void* arg)
{while(1){//还有票if(tickets > 0){usleep(100000); //休眠0.1秒,模拟抢票前戏printf("线程 0x%x 抢到了一张票,还剩 %d 张票...\n", pthread_self(), --tickets);}else{break;}}return nullptr;
}int main()
{pthread_t tids[3];for(int i = 0; i < 3; ++i){pthread_create(tids + i, nullptr, Ticket, nullptr);}for(int i = 0; i < 3; ++i){pthread_join(tids[i], nullptr);}return 0;
}
运行结果:

可以看到, 在不加锁的情况下, tickets 直接被干到负数了, 原因就在于当 tickets 只剩 1 张时, 进行 if(tickets > 0) 判断时, 三个线程并行的执行了判断且进入了 if 语句内, 那 tickets 被干到负数也是必然的了.
通过加锁来规避这个问题, 代码修改如下:
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <pthread.h>
using namespace std;int tickets = 10000; //总票数
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;void* Ticket(void* arg)
{while(1){pthread_mutex_lock(&mutex);//还有票if(tickets > 0){usleep(50000); //休眠0.05秒,模拟抢票前戏printf("线程 0x%x 抢到了一张票,还剩 %d 张票...\n", pthread_self(), --tickets);pthread_mutex_unlock(&mutex);}else{pthread_mutex_unlock(&mutex);break;}}return nullptr;
}int main()
{pthread_t tids[3];for(int i = 0; i < 3; ++i){pthread_create(tids + i, nullptr, Ticket, nullptr);}for(int i = 0; i < 3; ++i){pthread_join(tids[i], nullptr);}pthread_mutex_destroy(&mutex);return 0;
}
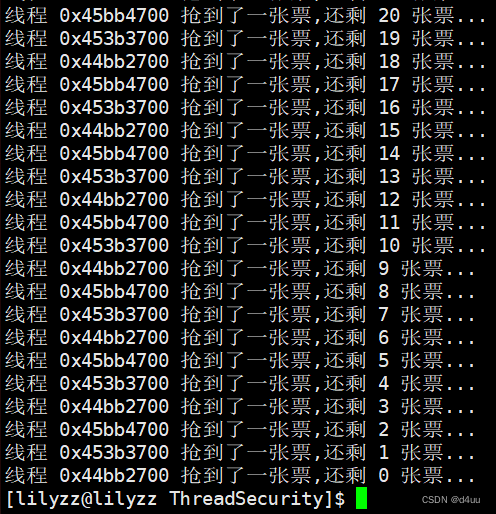
需要注意的是 if 和 else 语句中都需要进行解锁, 如果只在 if 中解锁, 最后申请到锁但走了 else 语句的线程就并没有释放锁, 可能导致其他在等待锁资源的线程永远阻塞申请不到锁.
运行结果:

三、RAII风格的锁
虽然加锁, 解锁配套使用不难, 但毕竟是人写的, 难免可能出现加锁后忘了解锁, 而后导致死锁的情况, 所以通过 RAII 设计风格封装一下锁的使用, 可以有效避免这种问题.
示例代码:
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <pthread.h>
using namespace std;int tickets = 100; //总票数
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;class LockGuard
{
public://构造加锁LockGuard(pthread_mutex_t* m): _pmutex(m){pthread_mutex_lock(_pmutex);}//析构解锁~LockGuard (){pthread_mutex_unlock(_pmutex);}
public:pthread_mutex_t* _pmutex;
};void* Ticket(void* arg)
{while(1){usleep(100000);LockGuard lg(&mutex);//还有票if(tickets > 0){usleep(50000); //休眠0.05秒,模拟抢票前戏printf("线程 0x%x 抢到了一张票,还剩 %d 张票...\n", pthread_self(), --tickets);}else{break;}}return nullptr;
}int main()
{pthread_t tids[3];for(int i = 0; i < 3; ++i){pthread_create(tids + i, nullptr, Ticket, nullptr);}for(int i = 0; i < 3; ++i){pthread_join(tids[i], nullptr);}pthread_mutex_destroy(&mutex);return 0;
}
运行结果:
这样可以达到, 构造时加锁, 析构时解锁, 全自动化, 不必担心忘了解锁了.