网站建设案例 星座网站建设招聘兼职
1.base64加密方式
1. base64是什么?
Base64,顾名思义,就是包括小写字母a-z、大写字母A-Z、数字0-9、符号"+"、"/"一共64个字符的字符集,(另加一个“=”,实际是65个字符,至于为什么还会有一个“=",这个后面再说)。任何符号都可以转换成这个字符集中的字符,这个转换过程就叫做base64编码。
2.示例
<script>
let str = 'ImGod';
let str64 = window.btoa(str);//Base64加密
console.log('转化后:'+str64);
let jm = window.atob(str64);//Base64解密
console.log('解码后:'+jm);</script>
结果:

2.MD5 加密方式(不可逆)
1.什么是MD5
MD5是一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。MD5由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)设计,于1992年公开,用以取代MD4算法。
MD5.JS是通过前台js加密的方式对密码等私密信息进行加密的工具。
2.引入
<script src="https://cdn.bootcss.com/blueimp-md5/2.12.0/js/md5.min.js"></script>
4.示例
<script>
// MD5加密方式
// hex_md5(data);//data表示你要加密的数据
let str = 'abc';
let newStr = md5(str);
console.log(newStr);
</script>
结果:

3.编码和解码字符串
1.什么是编码和解码字符串
这个主要是使用JS函数的escape()和unescape(),分别是编码和解码字符串。
escape采用ISO Latin字符集对指定的字符串进行编码。所有的空格符、标点符号、特殊字符以及其他非ASCII字符都将被转化成%xx格式的字符编码(xx等于该字符在字符集表里面的编码的16进制数字)
在很多脚本语言的应用当中,escape函数是一个可转换编码的函数,比如javascript 的 ajax 中,向a.php传递参数?city=北京,可先将"北京"用escape重新编码,再进行传递,在服务器端接收后再解码才不会出现乱码。escape一般用于传递URL参数和类似urlencode base64_encode函数是类似的。
2 .示例
<script>
//编码和解码字符串
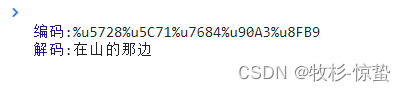
let str = '在山的那边';
let str1 = escape(str);
let str2 = unescape(str1)
console.log('编码:'+str1);
console.log('解码:'+str2);
</script>
结果:
4.sha1.js (不可逆)
1. sha1是什么?
SHA-1是一种数加密算法,该算法的思想是接收一段明文,然后以一种不可逆的方式将它转换成一段(通常更小)密文,也可以简单的理解为取一串输入码(称为预映射或信息),并把它们转化为长度较短、位数固定的输出序列即散列值(也称为信息摘要或信息认证代码)的过程。
2. 引入
<script src="https://cdn.bootcss.com/js-sha1/0.6.0/sha1.js"></script>
目前没有在网上没找到下载地址,只能在线引入。
3. 示例
<script>
//sha1加密方式
let str = 'abcd';
let sha_1 = sha1(str);
console.log(sha_1);
</script>
结果:
