网站的动效怎么做的互动网站策划
【提示:官方已不再维护,建议命令行方式安装,但可以学习了解一下】
Appium Desktop是一款适用于Mac、Windows和Linux的应用程序,它以漂亮灵活的UI为您提供Appium自动化服务器的强大功能。它基本上是Appium Server的图形界面。您可以设置选项、启动/停止服务器、查看日志等。
-
需要先准备好安装JDK和SDK环境
-
从https://github.com/appium/appium-desktop这里可以找到安装包

-
双击Appium-Server-GUI-windows-1.22.3-4.exe安装


等待安装完成。


点Edit Configurations,打开窗口如下:
JAVA_HOME 和 ANDROID_HOME 默认就会加载系统变量配置的路径
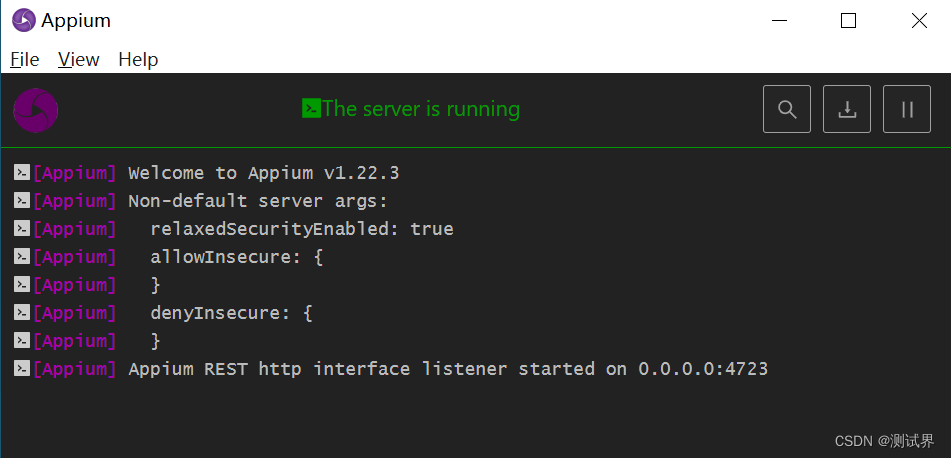
点右上角的X关掉该窗口,点startServer按钮,启动Appium服务,如下图