旅游网站模板免费医院网站官方微信精神文明建设
##在线安装:
打开Vscode扩展商店,输入 "GitHub Copilot " ,选择下载人数最多的那个。(这个是你写一部分代码或者注释,Ai自动帮你提示/补全代码),建议选择这个
注意下面有个和他类似的 "GitHub Copilot Chat" ,这个是聊天式的,你问编程相关问题他给你答案。
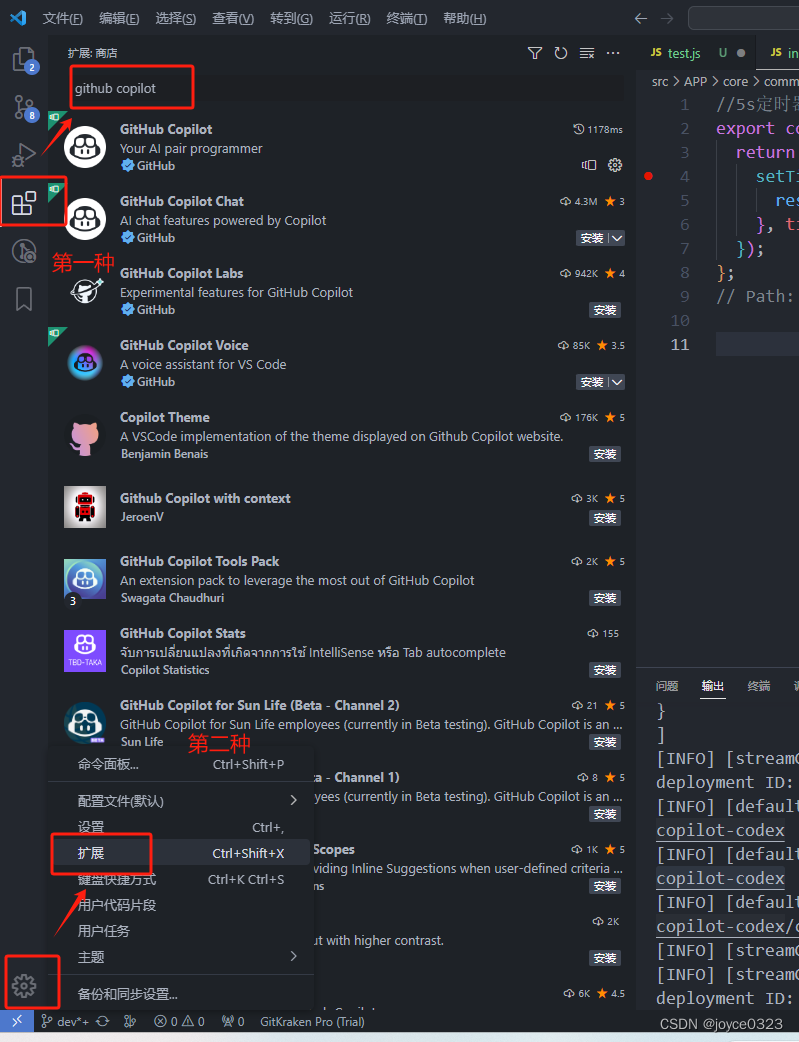
安装好之后,需要激活。一般分激活码和github账号登录。需要买服务可自行某宝20-30 可搞定。
搞定之后如果你看到如下图出现Copilot 图标,就能正常使用了:
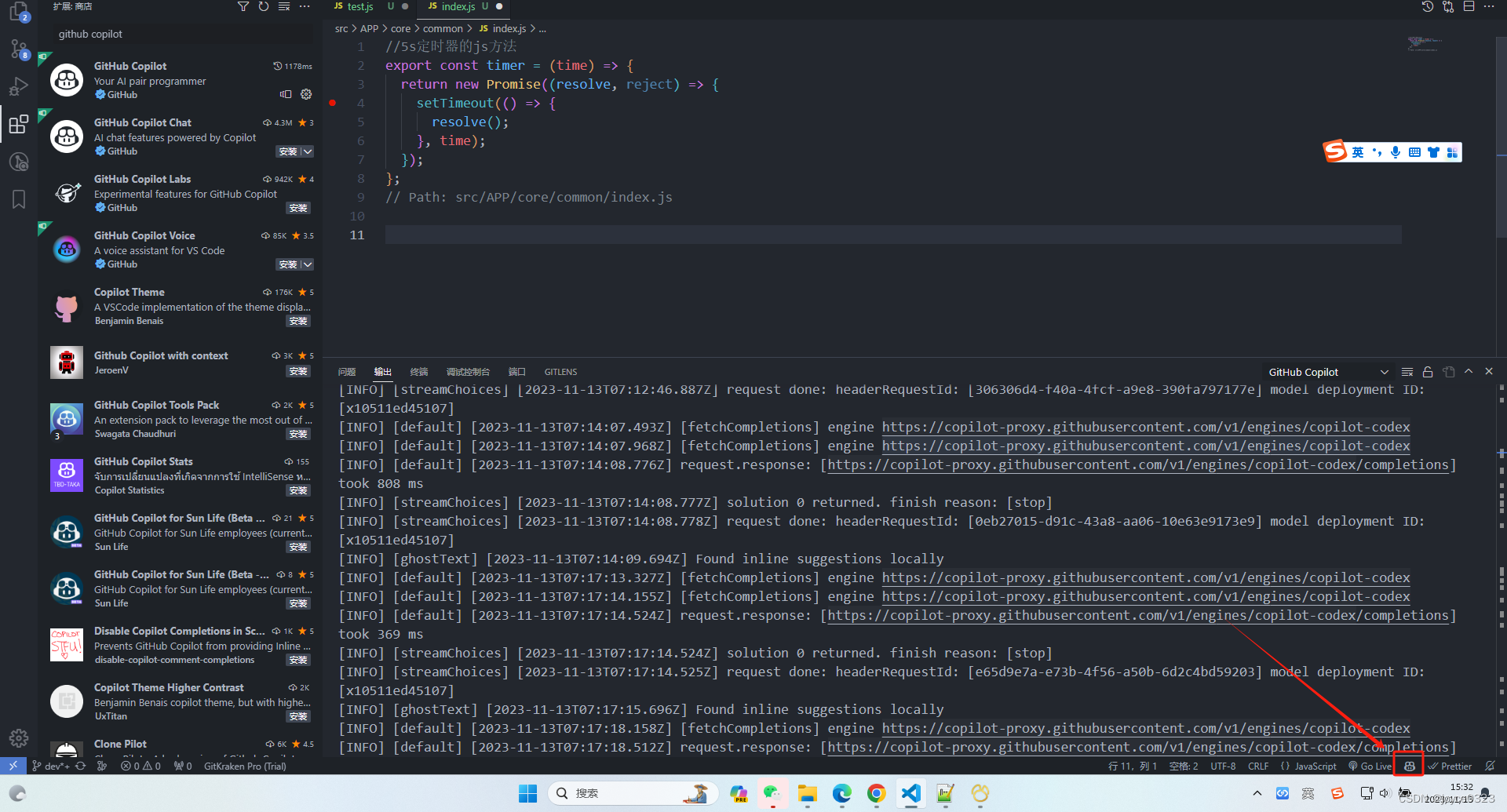
如果 这里没有任何图标,就点开右下角最右边的通知栏,如果是提示你让你登录github授权copilot的话就是授权失败,需要重新授权。
如果是这个地方一直转圈圈,或则提示连接超时,一般是连不上copilot的服务器,注意,连接copilot是不需要使用魔法上网的,可以按下面的地址配置即可:
ineo6 / Hosts · GitLab![]() https://gitlab.com/ineo6/hosts配置了还不行的话,尝试更改网络连接,如果是校园网,公司网络,可以考虑连自己的移动热点试试。
https://gitlab.com/ineo6/hosts配置了还不行的话,尝试更改网络连接,如果是校园网,公司网络,可以考虑连自己的移动热点试试。
注意:
GitHub Copilot 和 "GitHub Copilot Chat" 这两个插件是绑定的,你安装其中一个,另一个也会自动安装。如果两个都安装之后只有命令式Chat生效了,写代码不会自动提示的话,可以打开本地文件夹:
C:\Users\【用户名】\.vscode\extensions 找到 "GitHub Copilot Chat" 对应的版本,删除对应文件夹,然后重启Vscode即可。
##离线安装:
1先访问网站,下载好 对应的离线安装包:
官网下载(特别慢):Extensions for Visual Studio family of products | Visual Studio Marketplace
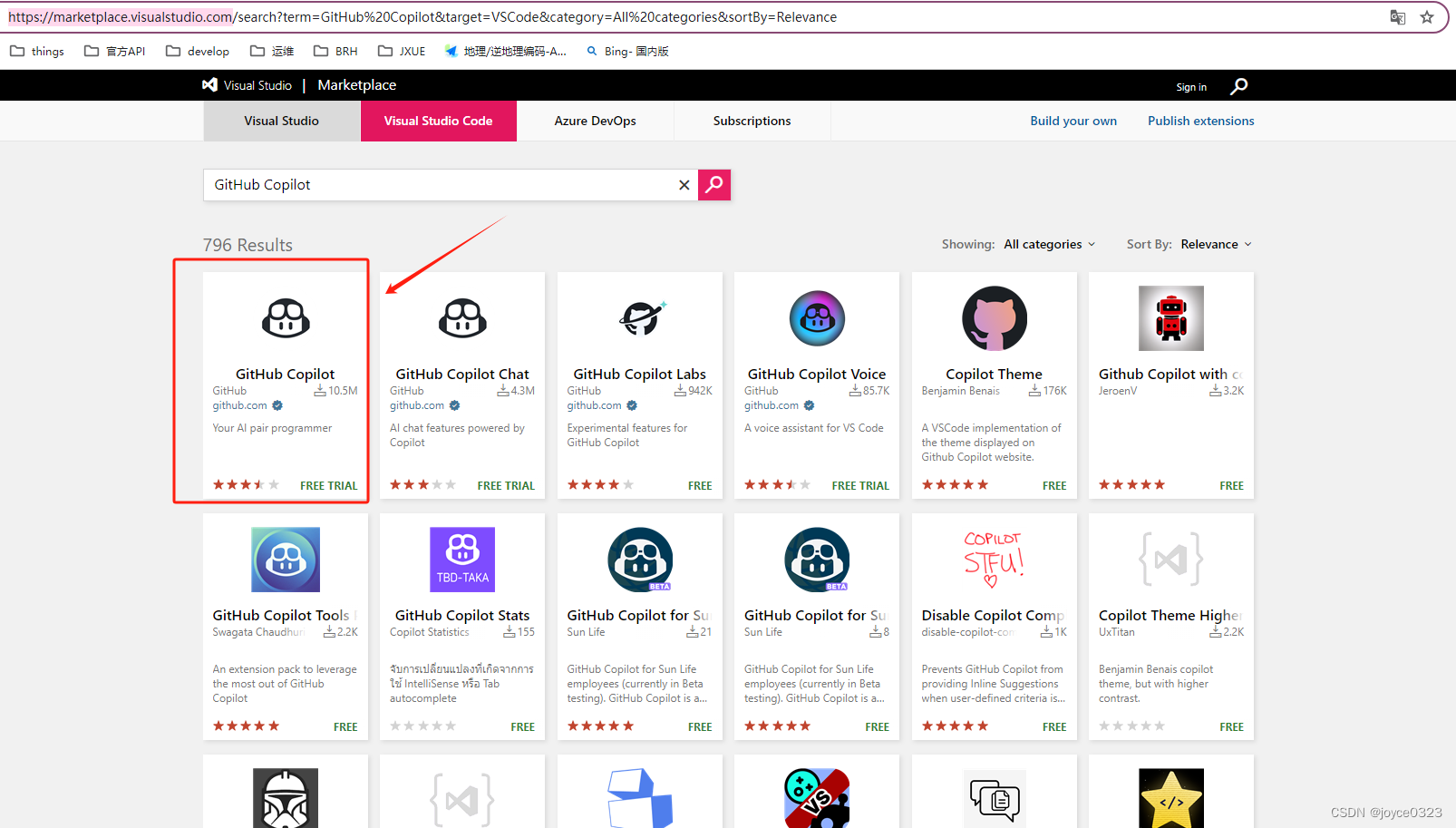
2:打开Vscode选择本地扩展程序,进行安装:

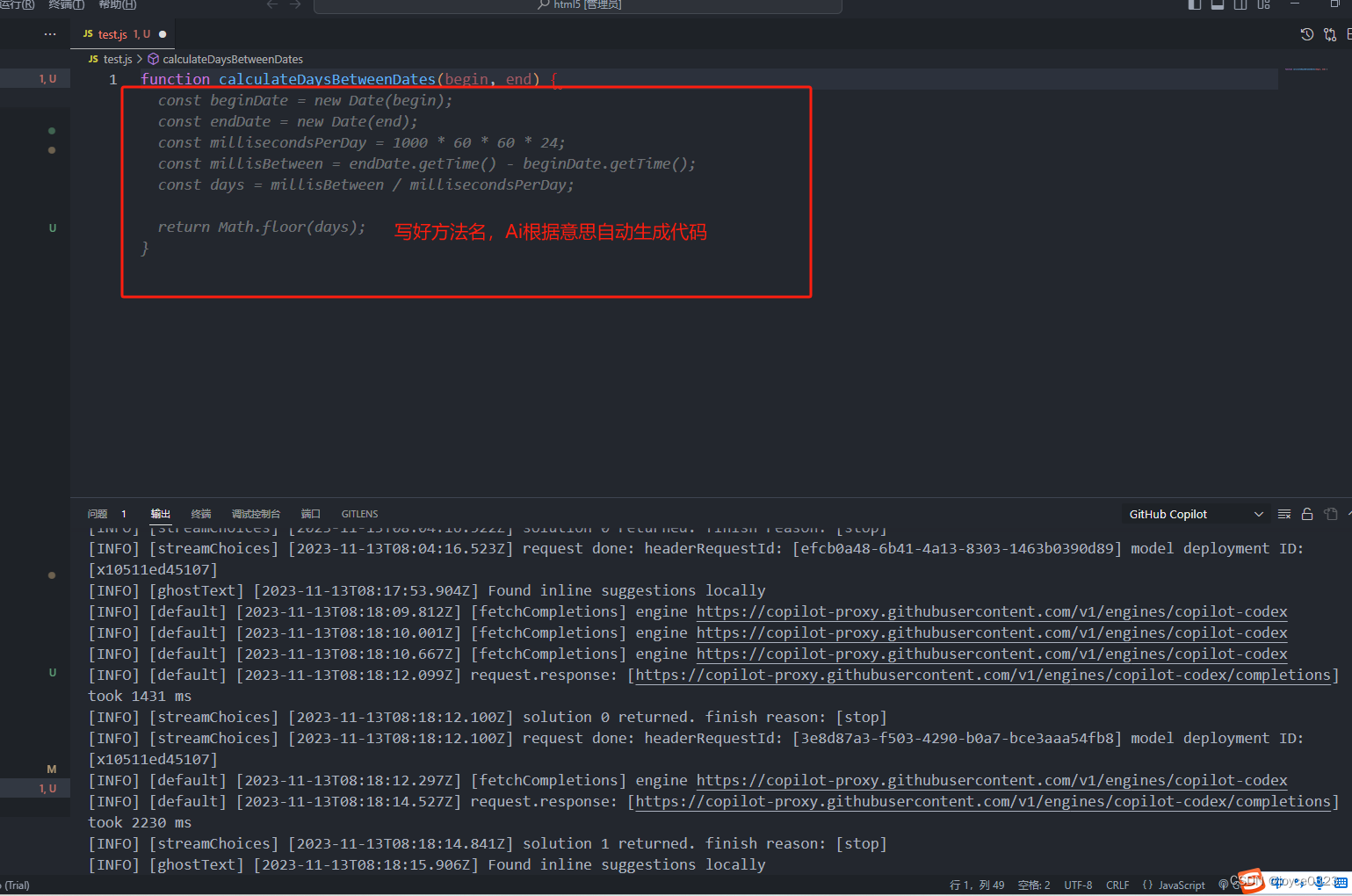
安装好后重启Vscode,保证网络正常即可正常使用。
正常使用结果如下:
结尾配上官方使用文档:

开始使用 GitHub Copilot - GitHub 文档