顺义成都网站建设河南高端网站建设
ubuntu安装
centos安装
安装完毕之后执行一下这条命令,可以避免每次使用docker命令都需要sudo权限
sudo usermod -aG docker $USER
阿里云docker镜像加速
DockerHub
遇到不懂或者不会使用的命令可以使用docker --help查看文档
docker --help
如:
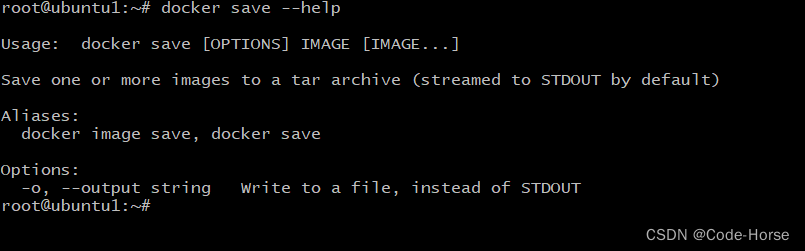
docker save --help
docker load --help
使用docker时需要特别注意防火墙和端口占用
镜像相关命令
镜像是将应用程序及其需要的系统函数库、环境、配置、依赖等打包而成。
docker images # 查看所有镜像docker pull nginx # 从云端(docker hub)拉取nginx镜像,没有指定tag则是最新docker save -o ubuntu:20.04.tar nginx # 将镜像导出到磁盘docker rmi nginx # 删除镜像docker load -i nginx # 从磁盘中载入镜像... #更多使用 参看 docker --hlep
容器相关命令
容器相当于一个只能运行当前镜像的一个微系统,只包含镜像运行所需要的lib库、依赖、bash等文件。
# --name:容器名称 -p: 宿主机端口 映射 容器内端口 -d:后台运行容器
docker run --name mynginx-p 20000:22 -d nginx docker ps # 查看所有运行中的容器
docker ps -a # 查看所有容器docker logs mynginx # 查看容器日志
docker logs -f mynginx # -f 跟踪日志输出,实时监控docker pause mynginx # 挂起(暂停)容器
docker unpause mynginx # 恢复原本状态容器docker stop mynginx # 停止容器docker rm mynginx # 删除容器
docker rm -f mynginx # 强制删除容器,不建议# exec: 进入容器内部执行一个命令 -it:给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
docker exec -it mn bash # 进入mn容器,执行bash命令, exit可以退出容器.... #更多使用 参看 docker --hlep
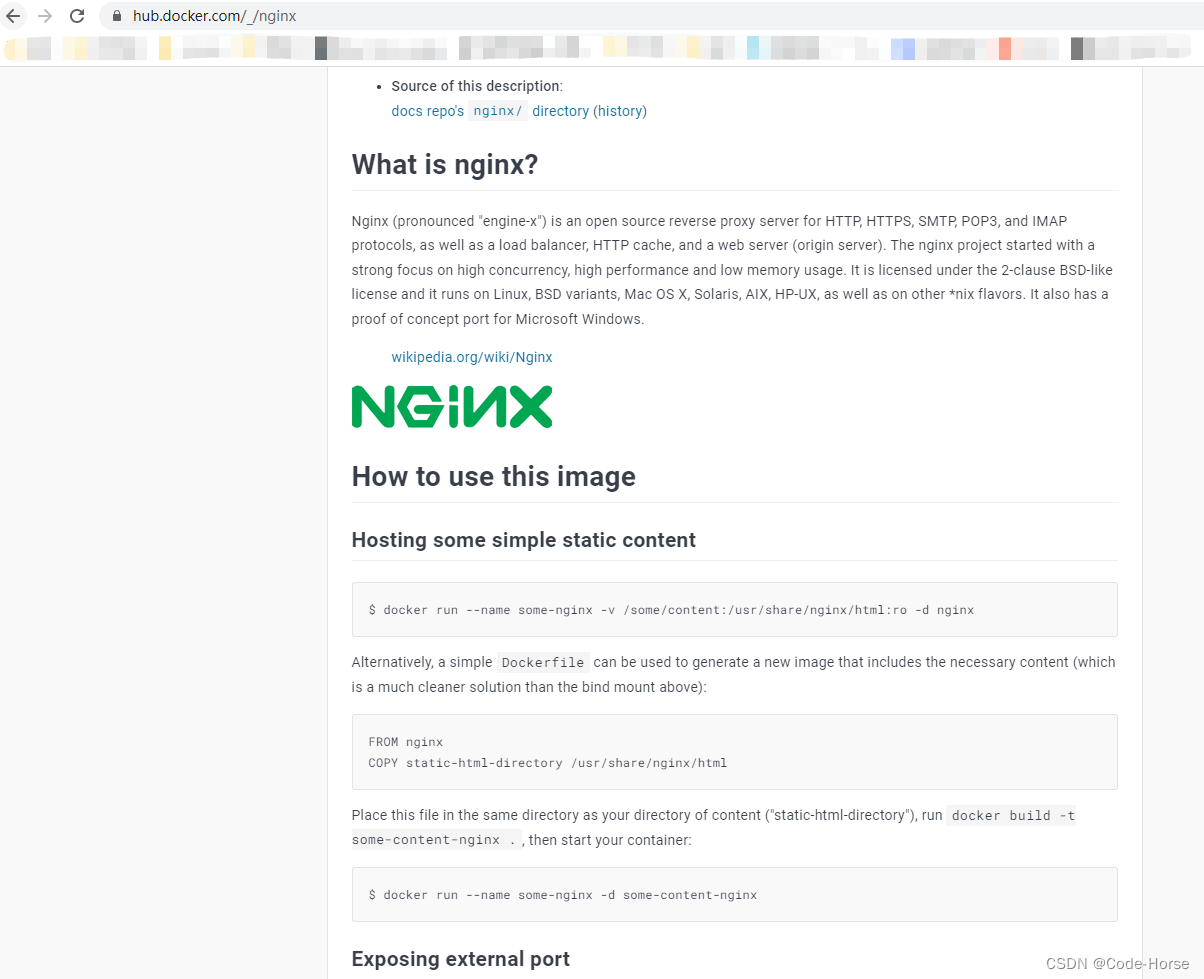
有些镜像可能会比较难创建和使用容器,如果发现使用run命令并且去查看状态并没有启动时,可以参看镜像的使用文档或者百度
在docker hub:https://hub.docker.com/_/nginx中查看镜像时,可以发现底下会有使用容器的教程的
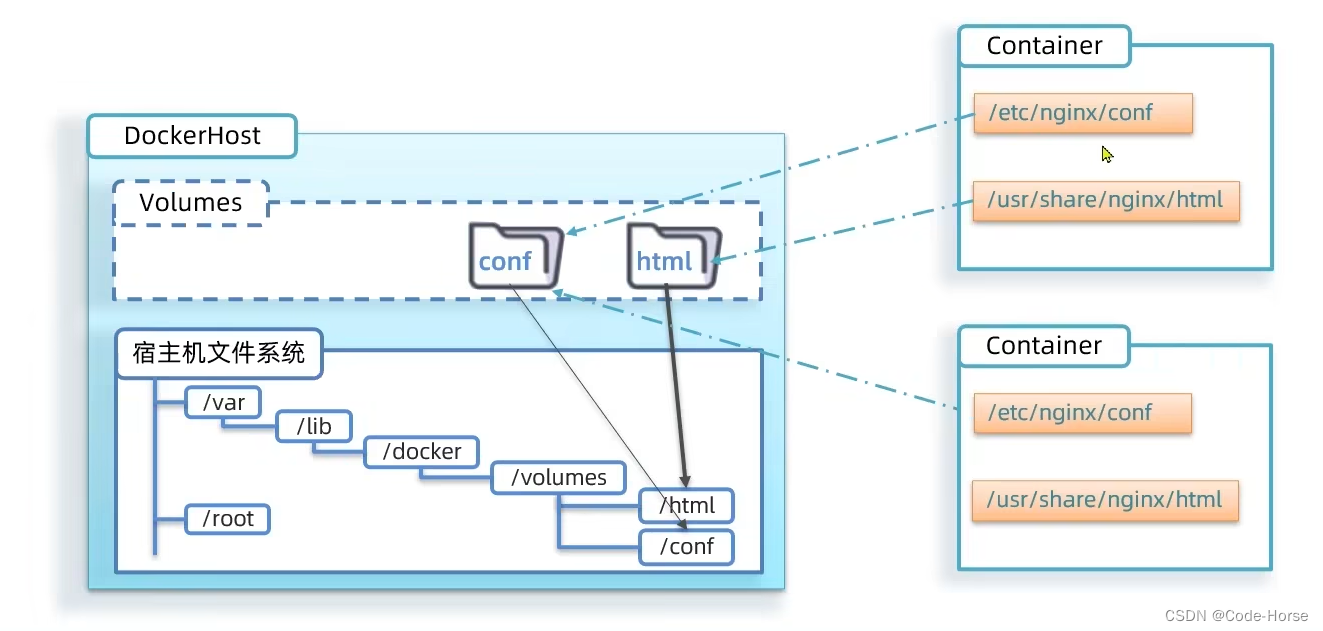
数据卷
数据卷可以使得宿主机和容器文件做一个映射。用户只操作宿主机文件就可以达到修改容器中的文件,达到用户操作和容器的解耦合,用户不需要进入容器中修改文件。
docker volume --help # 查看数据卷的帮助文档
docker volume create html # 创建一个或多个数据卷docker volume ls # 查看所有数据卷
docker volume inspect html # 显示一个或多个数据卷的详细信息docker volume prune # 删除所有未被使用的本地数据卷
docker volume rm html # 删除一个或多个数据卷
在启动时可以使用-v volumeName:/targetContainerPath参数来挂载(映射)数据卷
docker run --name mn -p 80:80 -v html:/usr/share/nginx/html -d nginx # -v 数据卷:需要映射容器中的文件
# 如果数据卷没有创建,docker会自动创建。
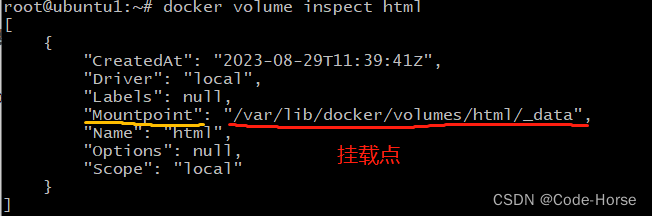
挂载成功后,修改挂载点中的文件,容器中的文件也会跟着改变
Dockerfile自定义镜像:Dockerfile参考文档

编写DockerFile文件
# 指定基础镜像
FROM ubuntu:16.04
# 配置环境变量,JDK的安装目录
ENV JAVA_DIR=/usr/local# 拷贝运行环境jdk 和 java项目的包
COPY ./jdk8.tar.gz $JAVA_DIR/
COPY ./docker-demo.jar /tmp/app.jar# 安装JDK
RUN cd $JAVA_DIR \&& tar -xf ./jdk8.tar.gz \&& mv ./jdk1.8.0_144 ./java8# 配置环境变量
ENV JAVA_HOME=$JAVA_DIR/java8
ENV PATH=$PATH:$JAVA_HOME/bin# 暴露端口
EXPOSE 8090
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar
编辑完DockerFile文件后,使用 docker build 开始构建
# -t: 镜像名:tag ./: Dockerfile所在的文件夹
docker buld -t javaweb:1.0 ./
由于有分层的概念,构建时可以使用别的基础镜像
# 指定基础镜像
FROM java:8-alpine #项目
COPY ./docker-demo.jar /tmp/app.jar# 暴露端口
EXPOSE 8090
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar
如果发现服务怎么都起不来,可以检查下内存是否足够
top # 可以查看内存
df -h # 查看磁盘内存