免费网站建设步骤软件定制一般多少钱
lua垃圾回收(Garbage Collect)是lua中一个比较重要的部分。由于lua源码版本变迁,目前大多数有关这个方面的文章都还是基于lua5.1版本,有一定的滞后性。因此本文通过参考当前的5.3.4版本的Lua源码,希望对Lua的GC算法有一个较为详尽的探讨。
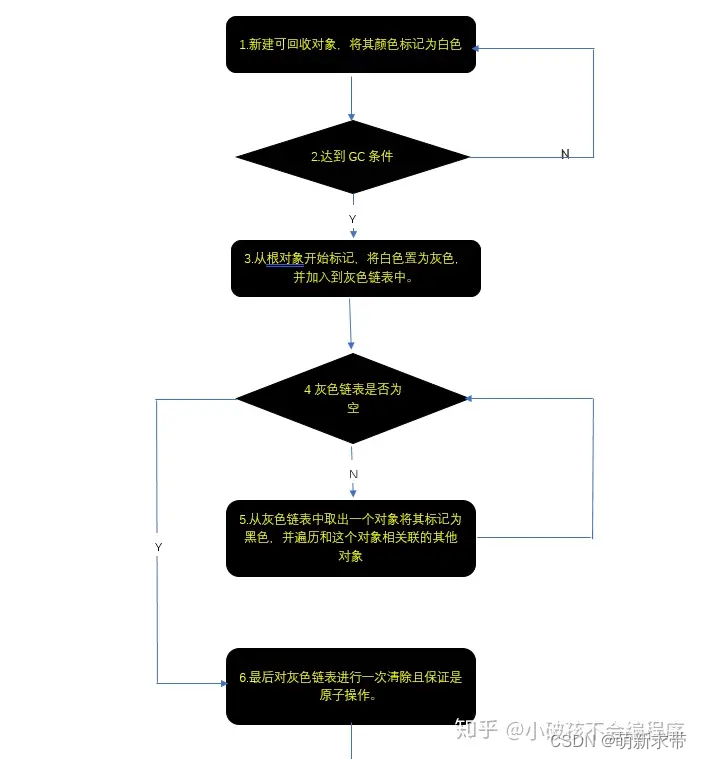
Lua的垃圾回收器使用了三色标记算法,这是一种基于标记-清除(mark-and-sweep)的改进算法。它引入了三种颜色来描述对象的状态,以提高垃圾回收的效率和性能。
三色标记算法的三种颜色是:
-
白色(White):初始状态下,所有的对象都被假设为白色,表示这些对象是未访问的、未标记的。
-
灰色(Gray):表示对象已被访问,但其引用的其他对象尚未被标记。灰色对象可能有指向白色对象的引用,即它们是待处理的对象。
-
黑色(Black):表示对象已被访问并且其引用的其他对象也已被标记。黑色对象及其引用的所有对象都是被标记为活跃对象,不会被垃圾回收。
Lua的三色标记算法流程如下:
-
初始标记阶段:从根集合(如全局变量、栈、寄存器等)开始,将根集合中的对象标记为黑色,并将其引用的对象标记为灰色。这个阶段是一个快速的标记过程,它只标记直接可达的对象。
-
追踪阶段:在初始标记后,垃圾回收器继续遍历灰色对象,将它们标记为黑色,同时将它们引用的白色对象变为灰色。这个过程会不断追踪、探索灰色对象的引用链,直到所有可达的对象都被标记为黑色。
-
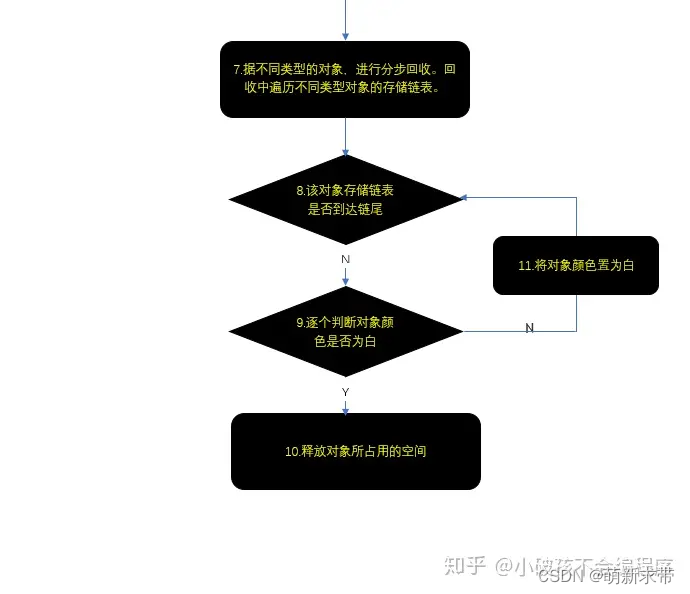
清除阶段:清除阶段会回收所有未标记(仍然是白色)的对象,释放它们占用的内存空间。这些未被标记的对象被认为是不可达的,因此可以安全地回收其所占用的内存。
-
内存整理(可选):在清除阶段之后,可能会对内存空间进行整理,例如合并连续的内存块或重新组织内存布局,以便在后续的内存分配中更有效地利用空闲块。
备注:白色分为白1和白2。原因:在GC标记阶段结束而清除阶段尚未开始时,如果新建一个对象,由于其未被发现引用关系,原则上应该被标记为白色,于是之后的清除阶段就会按照白色被清除的规则将新建的对象清除。这是不合理的。于是lua用两种白色进行标识,如果发生上述情况,lua依然会将新建对象标识为白色,不过是“当前白”(比如白1)。而lua在清扫阶段只会清扫“旧白”(比如白2),在清扫结束之后,则会更新“当前白”,即将白2作为当前白。下一轮GC将会清扫作为“旧白”的白1标识对象。通过这样的一个技巧解决上述的问题。如下图:(下图中为了方便颜色变换的理解,没有考虑barrier的影响)
三色标记算法通过将对象分为三种状态,减少了标记和追踪过程中对整个对象图的遍历次数,提高了垃圾回收的效率。它的主要优势在于其增量式标记和回收策略,使得垃圾回收过程可以分散到多个小步骤中,降低了垃圾回收对系统造成的停顿时间。
参考:
Lua GC机制分析与理解-上