青海网站建设与管理网站建设的目标
一.准备工作
1.安装python和pycharm并配置好环境变量
python安装路径

pycharm安装路径:
python系统变量:

pycharm环境变量:
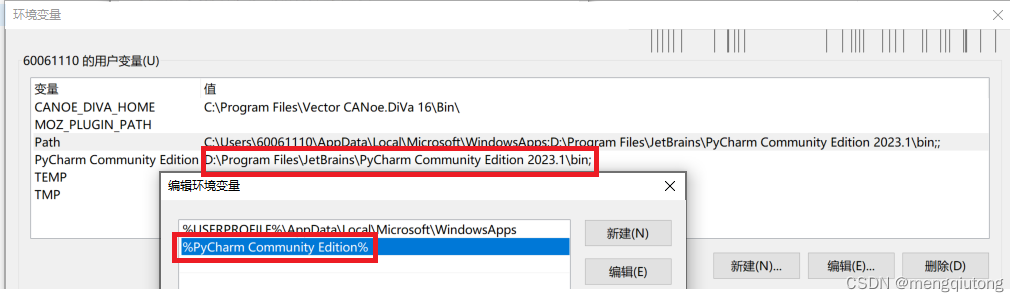
注意:正常安装,并勾选ADD PATH一般会自动配好
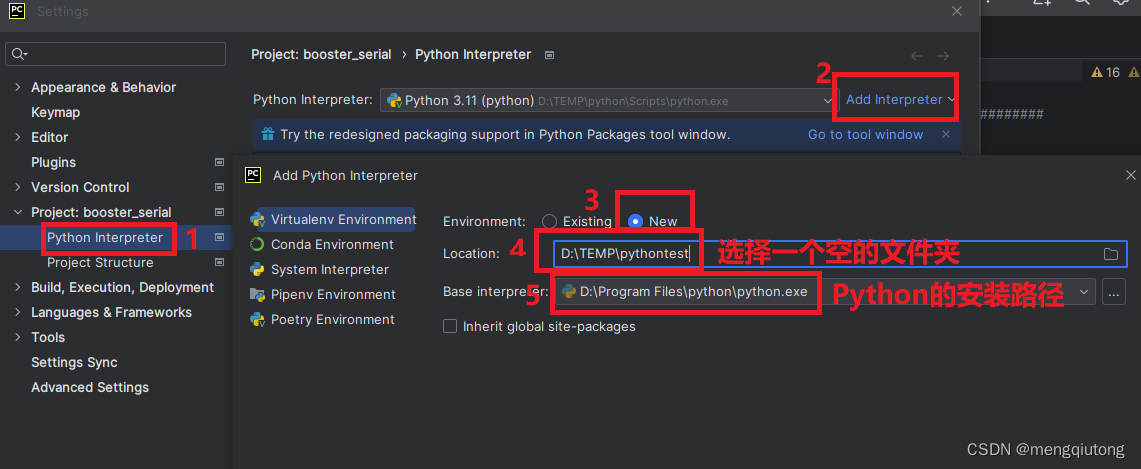
2.在pycharm创建一个新的python的虚拟环境
用pycharm开发python项目时,使用虚拟环境的好处是:
- 可以为不同的项目创建不同的python环境,避免了依赖包和版本的冲突。
- 可以为同一个项目的不同环境(如开发、测试、生产)使用不同的依赖包和配置。
- 可以方便地在pycharm中创建、管理、切换、激活、删除虚拟环境。
- 可以提高安全性和稳定性,避免污染系统环境和其他项目环境。
因此,一般建议为每个项目创建一个独立的虚拟环境,或者至少为不同类型或不同需求的项目创建不同的虚拟环境。项目创建在虚拟环境同文件夹内,以便查找。
以pythontest为例:
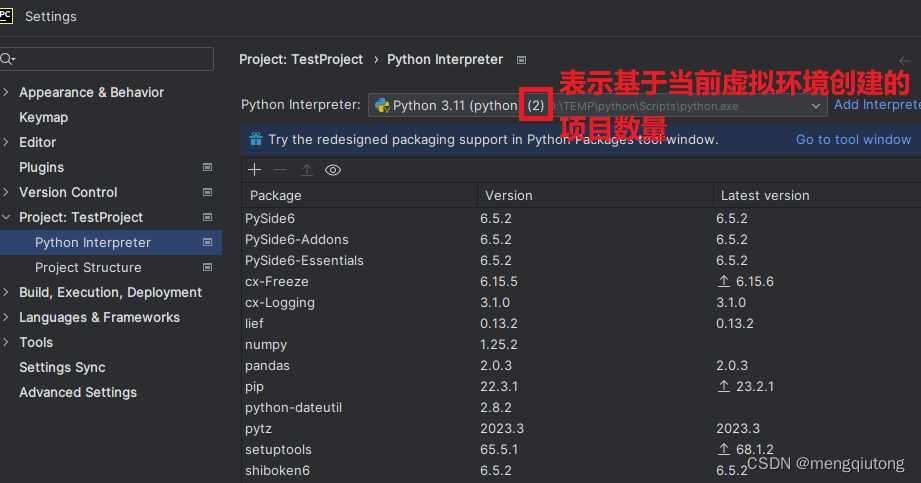
3.在虚拟环境中安装python包的方式
本文剩余的演示均在以下虚拟环境中演示:
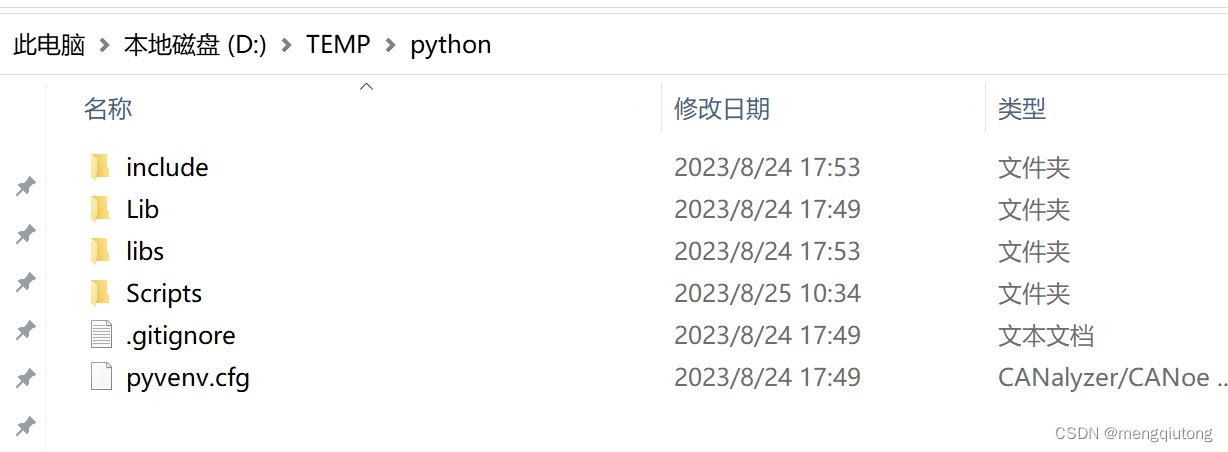
第一种在Available Packages里安装

第二种在Terminal(CMD)中安装
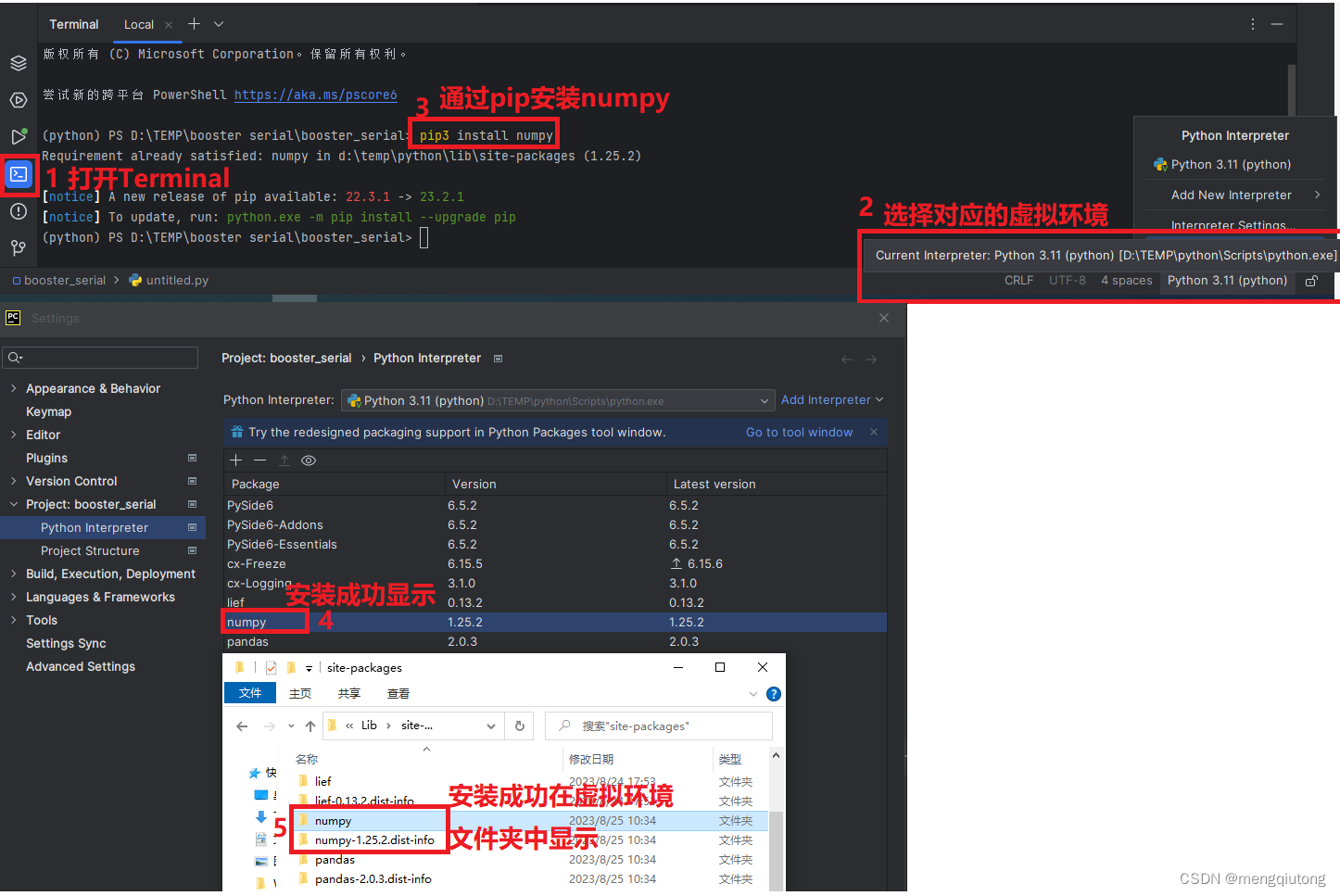
用 Terminal的方式(pip3 install Pyside6 )安装好Pyside6
pip install xxx 是用来为Python 2安装库的,而pip3 install xxx 是用来为Python 3安装库的。
如果系统中只安装了Python 2,那么就只能使用pip。如果系统中只安装了Python 3,那么既可以使用pip也可以使用pip3,二者是等价的。如果系统中同时安装了Python 2和Python 3,则pip默认给Python 2用,pip3指定给Python 3用
二.在Pycharm中配置PySide6 QtDesinger-打开Qt Designer窗口
用途:通过pycharm的External Tools 快速的打开Qt Designer窗口
Name:PySide6 QtDesinger (注意:名称可以自定义,要方便分辨即可)
Group:External Tools(默认是 External Tools,可自定义组名)
Program:D:\TEMP\python\Lib\site-packages\PySide6\designer.exe
Arguments:空着
Working directory: $ProjectFileDir


三.在Pycharm中配置pyside6-uic-将ui文件转换成py文件
Name:pyside6-uic(注意:名称可以自定义,要方便分辨即可)
Group: External Tools(默认是 External Tools,可自定义)
Program:D:\TEMP\python\Scripts\pyside6-uic.exe
Arguments: $FileName$ -o $FileNameWithoutExtension$.py
Working directory: $ProjectFileDir$

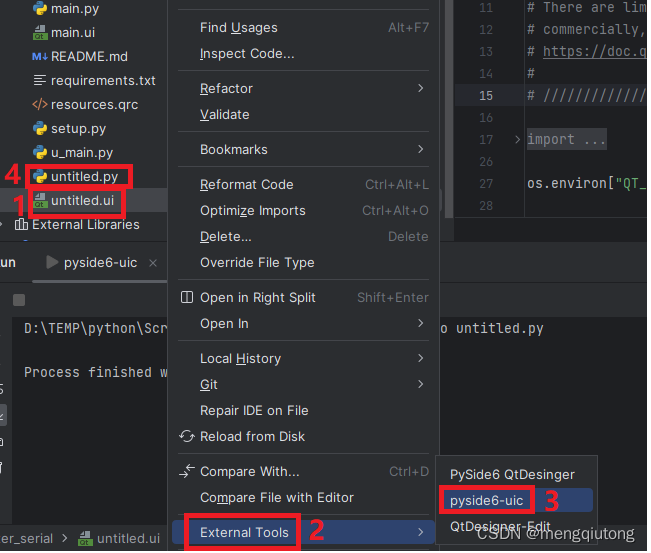
通过下面四个步骤即可把untitled.ui文件转换成untitled.py
四.在Pycharm中配置QtDesignerEdit-在pycharm中当前选择的ui文件,调起Qt Designer界面,修改现有UI文件
Name:QtDesignerEdit (注意:名称可以自定义,要方便分辨即可)
Group:(默认是 External Tools,可自定义组名)
Program:D:\TEMP\python\Lib\site-packages\PySide6\designer.exe
Arguments:$FileName$
Working directory:$FileDir$
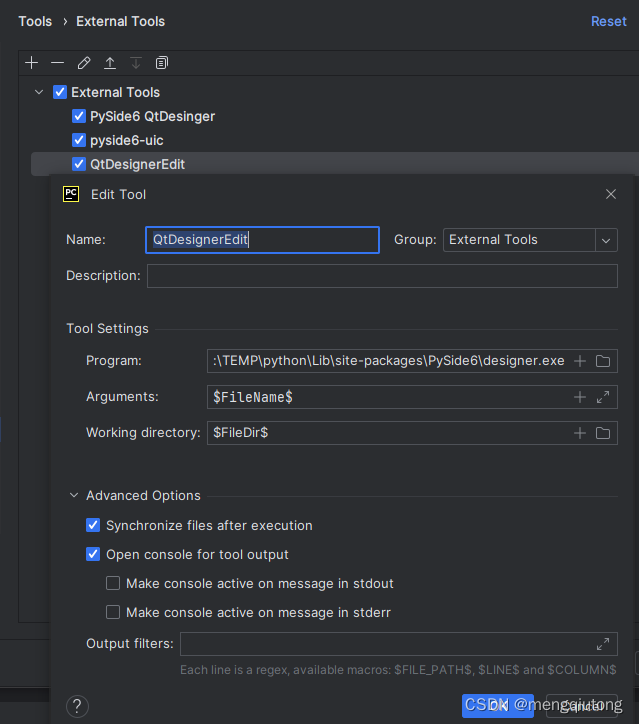
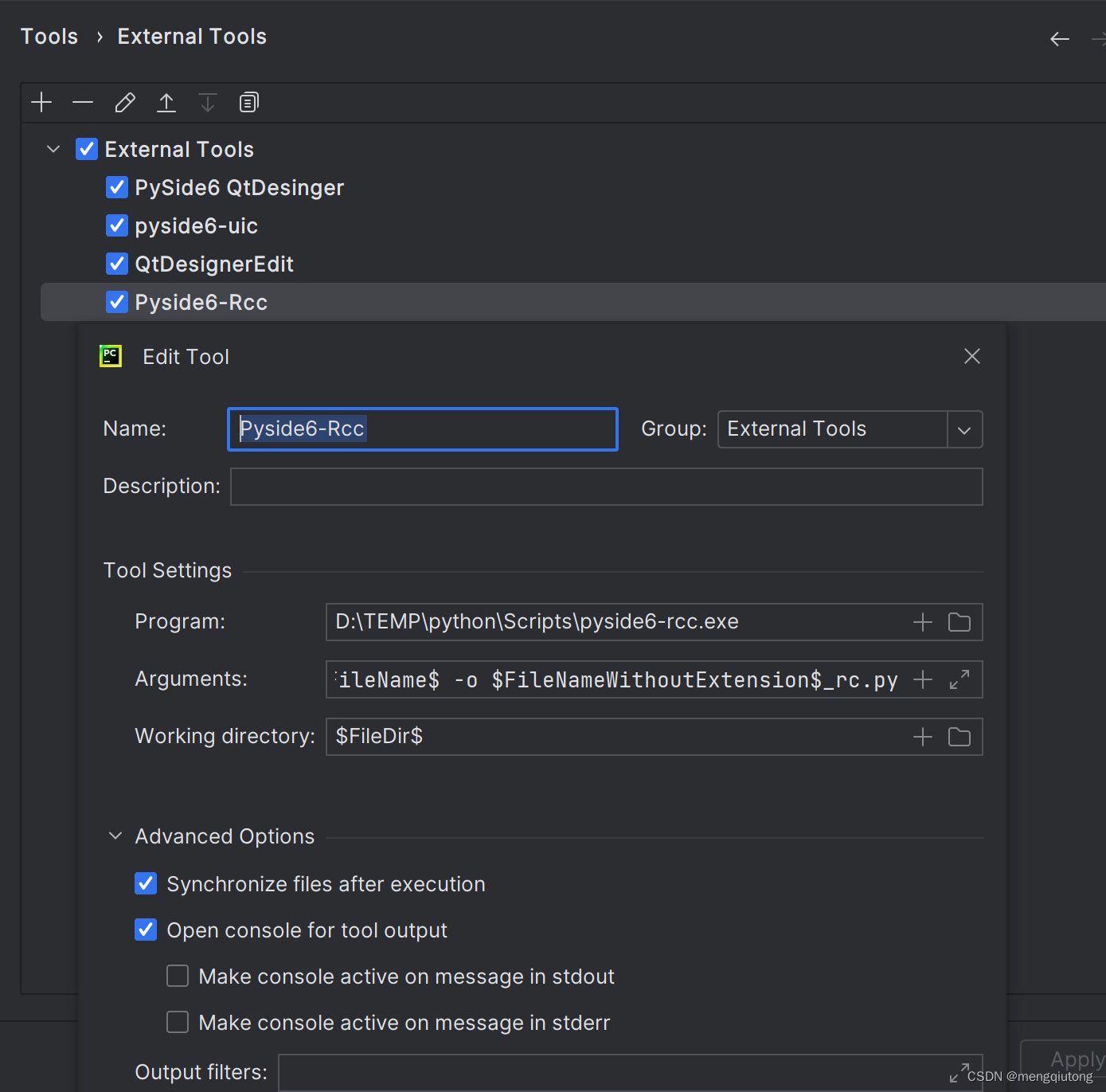
五. 在Pycharm中配置PyRcc-将rcc文件转换成py文件
Name:Pyside6-Rcc (注意:名称可以自定义,要方便分辨即可)
Group:External Tools (注意:默认是 External Tools,可自定义)
Program:D:\TEMP\python\Scripts\pyside6-rcc.exe
Arguments: $FileName$ -o $FileNameWithoutExtension$_rc.py
Working directory: $FileDir$
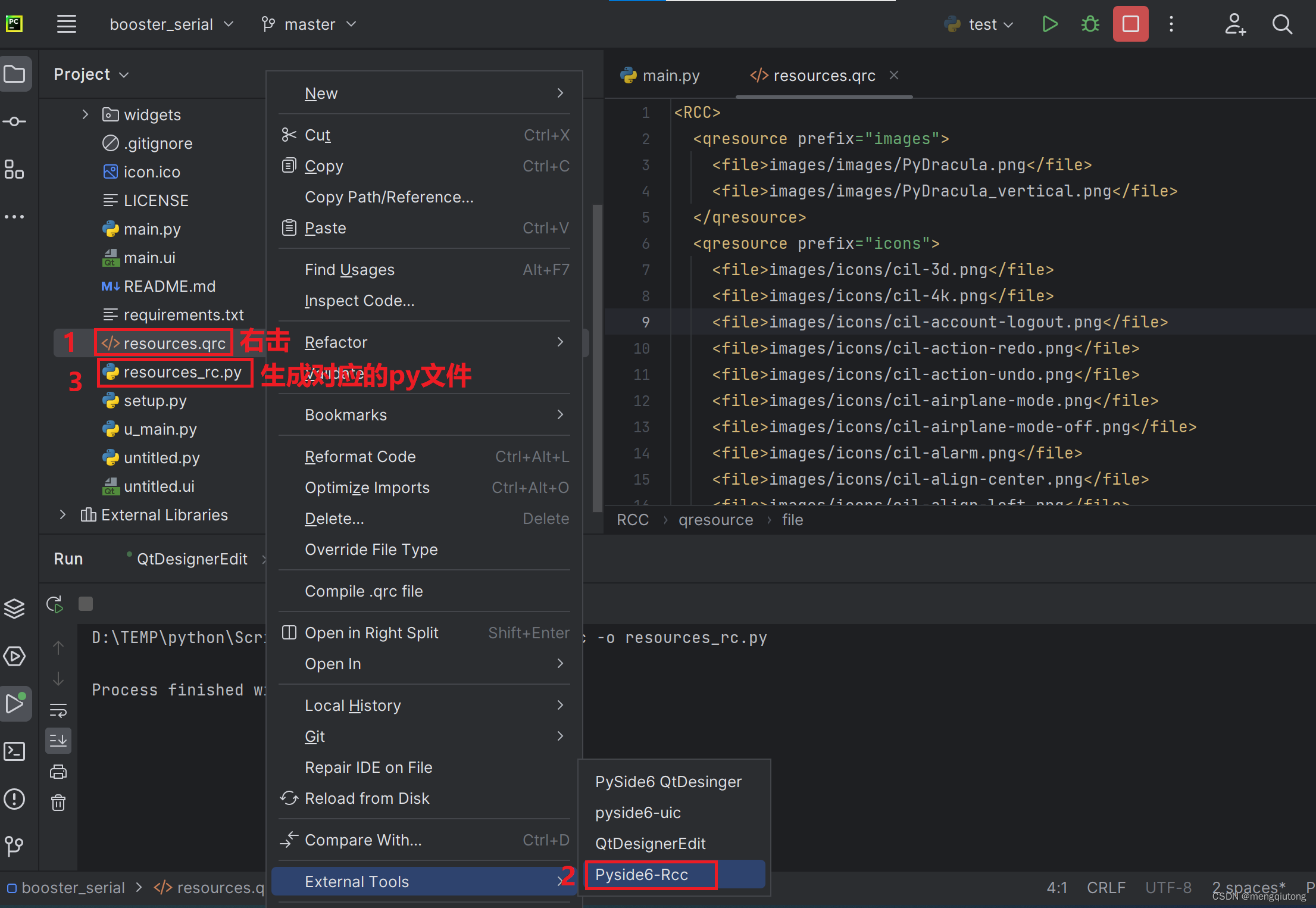
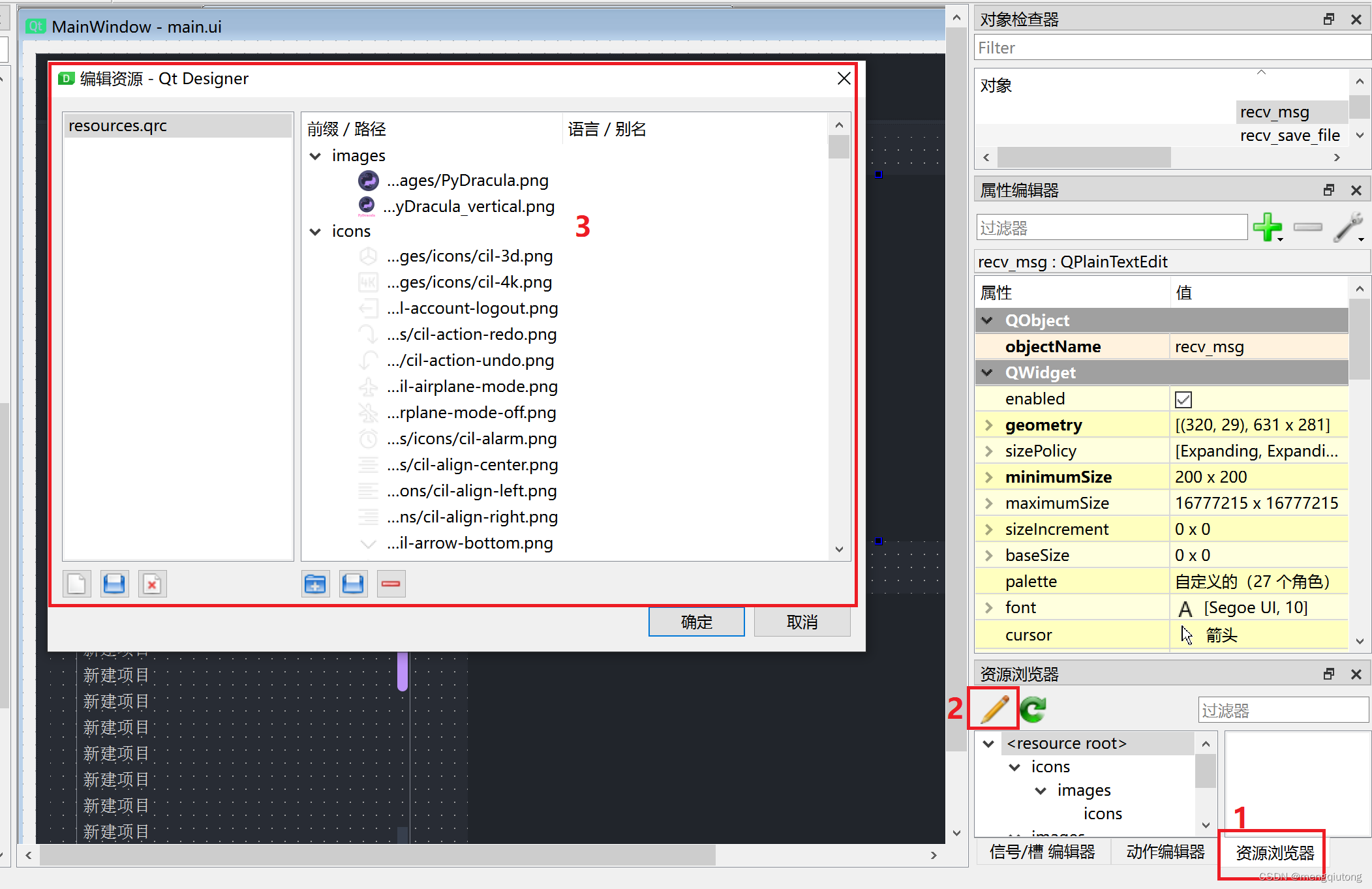
资源文件的创建: