深圳网站建设网站制作公司宣传册页面设计模板
[STM32]标准库-自定义BootLoader
- Bootloader
- Bootloader的实现
- BOOTloader工程
- APP工程
Bootloader
bootloader其实就是一段启动程序,它在芯片启动的时候最先被执行,可以用来做一些硬件的初始化或者用作固件热更新,当初始化完成之后跳转到对应的应用程序中去。
bootloader程序需要通过下载器烧写到芯片中,而APP则可以通过有线方式的UART、IIC、USB、SPI等总线来通过bootloader来更新,视所设计的bootloader程序而定。另外,对于无线方式热更新APP,一般是用WiFi、bluetooth通过UART透传的方式烧写芯片APP程序。
Bootloader的实现
本次采用STM32F429IGT6单片机,Flash共有1MB大小,SRAM共有256KB。
本次设计一个Bootloader和一个APP程序,空间分别如下:
BOOTloader程序起始地址0x0800 0000分配大小为0xA000,40KB,
注意按照扇区对齐(比如4KB一个扇区)
APP程序起始地址0x0800 A000分配的大小为0xF6000,984KB。
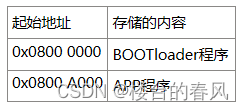 STM32的中断向量表和栈顶地址
STM32的中断向量表和栈顶地址
STM32Fx有一个中断向量表,这个中断向量表存放代码开始部分的后4个字节处(即0x08000004),代码开始的4个字节存放的是栈顶地址。
栈是从高到低分配,高地址到低地址
堆是从低到高分配,低地址到高地址
排列格式如下
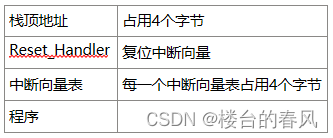 我们知道一般情况下,我们下载的代码放在0x08000_000这个位置,为了实现bootloader,我们可以将下载代码的位置整体往后挪一段空间,比如我们挪到0x0800_3000,那么这之前挪动空出来的一段空间,我们就可以用来存放我们的bootloader程序。系统上电后先运行bootloader,bootloader决定是否要更新app,最后跳转到0x0800 3000这个位置执行。
我们知道一般情况下,我们下载的代码放在0x08000_000这个位置,为了实现bootloader,我们可以将下载代码的位置整体往后挪一段空间,比如我们挪到0x0800_3000,那么这之前挪动空出来的一段空间,我们就可以用来存放我们的bootloader程序。系统上电后先运行bootloader,bootloader决定是否要更新app,最后跳转到0x0800 3000这个位置执行。
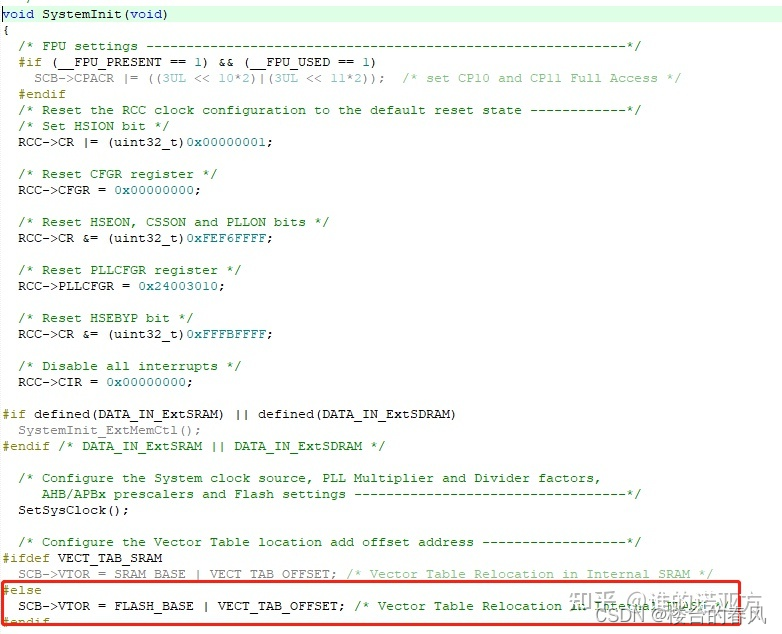 上图为SystemInit中修改用户app存放位置(0x0800 3000)的地方,SystemInit在启动文件中用到,它会在复位后,在main函数运行之前运行;
上图为SystemInit中修改用户app存放位置(0x0800 3000)的地方,SystemInit在启动文件中用到,它会在复位后,在main函数运行之前运行;
BOOTloader工程
bootloader和App都是完整的STM32工程,区别在于工程所实现的功能和占用Flash的大小。由于Bootloader的功能比较单一,并且为了节约Flash留给用户App,Bootloader一般不带操作系统,所占用的Flash较小。APP是完整的用户程序,按照正常的设计流程进行设计,只需要在工程配置和部分初始化代码处进行修改。
设置工程起始地址,及其大小
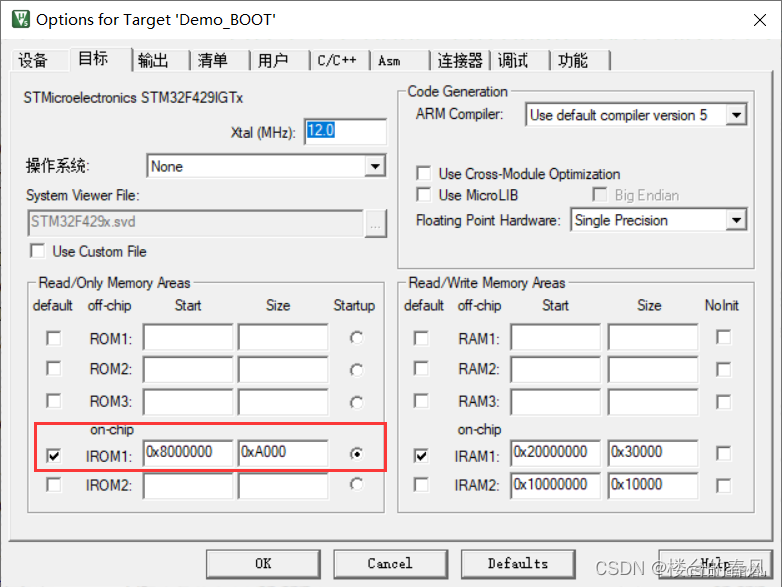 中断向量表的地址偏移
中断向量表的地址偏移
调用函数NVIC_SetVectorTable()进行配置。BOOT工程一般不需要配置
执行BOOT后,跳转到APP程序中
注意点:
检查堆栈地址是否有效,单片机的RAM大小为0x30000,0x3000 0000 - 0x3000 = 0x2FFD 0000,也可以用其他方法来计算RAM是否超过单片机的范围
关闭全局中断,__set_PRIMASK(1);仅只剩下NMI 和硬 fault 可以响应,记得在APP工程设置__set_PRIMASK(0);
复位BOOT工程中用到的外设
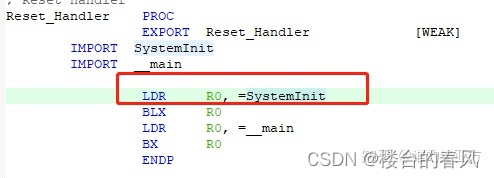
函数指针赋值为Reset_Handler向量的地址
设置堆栈地址
跳转到APP中
typedef void (*Run_APP_t)(void);
/**
-
@brief 跳转并执行到APP程序
-
@param APPProgramAddr : APP程序的地址
-
@retval None
/
static void Jump_to_APP(uint32_t APPProgramAddr)
{
Run_APP_t run_app = (Run_APP_t)((uint32_t*)(APPProgramAddr + 4));/* 检查堆栈地址(RAM地址)是否有效,然后跳转到用户应用程序 /
if(((uint32_t*)APPProgramAddr & 0x2FFD0000) == 0x20000000)
{
/*
关闭所有中断,
在它被置 1 后,就关掉所有可屏蔽的异常,只剩下NMI 和硬 fault 可以响应。
它的缺省值是 0,表示没有关中断。
*/
__set_PRIMASK(1);/* 复位所有已经开启的外设 */ GPIO_DeInit(GPIOH); GPIO_DeInit(GPIOA); GPIO_DeInit(GPIOC); EXTI_DeInit(); CRC_ResetDR(); USART_DeInit(USART1);/* 设置堆栈指针 */
// __set_PSP((uint32_t)APPProgramAddr);
// __set_CONTROL(0);
__set_MSP((uint32_t)APPProgramAddr);
/* 跳转到APP程序中执行 */run_app();
}
else
{USART1Printf("BOOT_ERROR1!\r\n");
}
}
APP工程
Flash的起始地址,大小
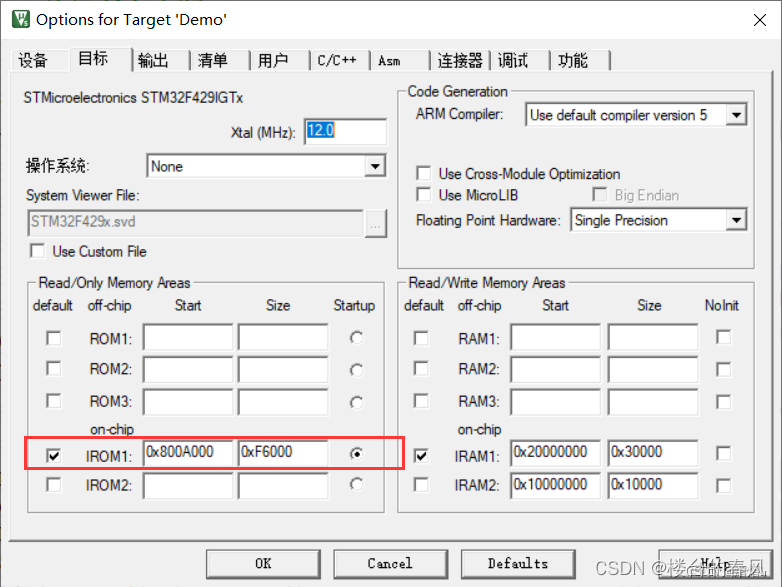 中断向量表偏移地址和开启全局中断
中断向量表偏移地址和开启全局中断
/* 设置中断向量表 /
NVIC_SetVectorTable(NVIC_VectTab_FLASH, 0xA000);//中断向量表偏移
/
关闭所有中断,
在它被置 1 后,就关掉所有可屏蔽的异常,只剩下NMI 和硬 fault 可以响应。
它的缺省值是 0,表示没有关中断。
*/
__set_PRIMASK(0);
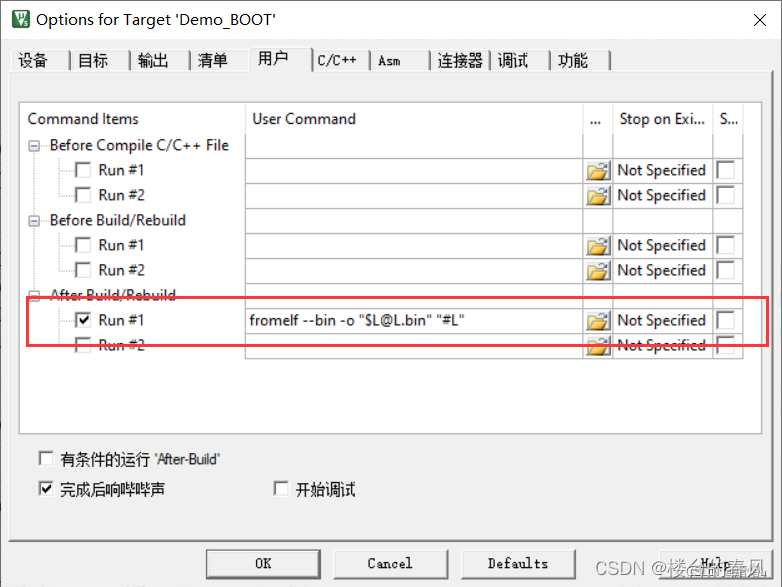
Keil5生成BIN文件
fromelf --bin -o “$L@L.bin” “#L”
 注意点:上电应检查标志位,不能初始化任何外设,根据该标志位来决定是否进入APP
注意点:上电应检查标志位,不能初始化任何外设,根据该标志位来决定是否进入APP
通过软件复位给 APP 一个干净的系统
这里的标志位存在RTC备份寄存器0中,占用4个字节