影视网站开发工程师展会电子商务网站如何建设
文章目录
- 一.概述
- 二.将会介绍的内容
- 三.DOTS技术与传统方式的不同
- 传统问题
- DOTS技术
- 四.插件安装
一.概述
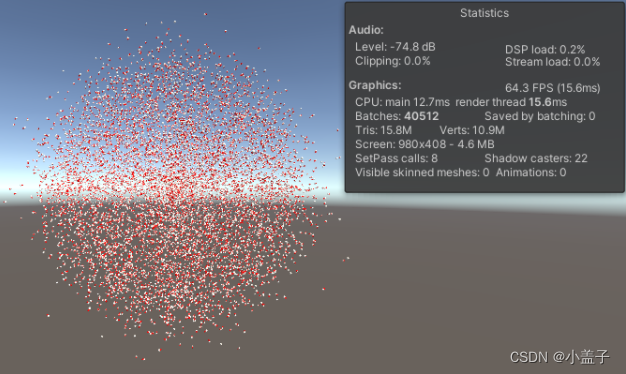
传统的游戏开发中,如果有成千上万的物体在场景中运动,那么你一定会认为是疯了.但有了Dost技术这一些都将变成可能.如图场景中有10000个物体在同时运动,帧率即能保持在60Fps以上.就是因为使用了我们今天要介绍的DOTS技术.

二.将会介绍的内容
我将几篇博文详细的介绍各模块的使用方式
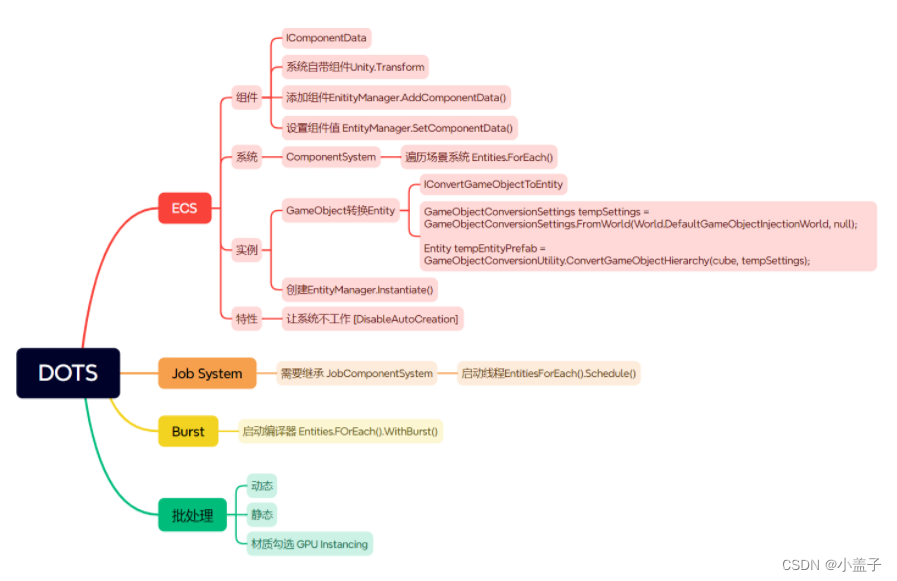
下面是我将会为大家介绍的内容结构脑图,在这相当于一个目录方便大家后面对照对像信息:
三.DOTS技术与传统方式的不同
传统问题
1.数据冗余 : Unity传统做法上脚本包含了大量的冗余信息,会引用到很多根本用不到的内容.比如MonoBehaviour的挂载就是这样.
2.单线程 : 在Unity中脚本大多在主线程运行,并未发挥多核心CPU的全部性能
3.编译器 : Unity对C#的代码编译的运行效率是相对低效的.
DOTS技术
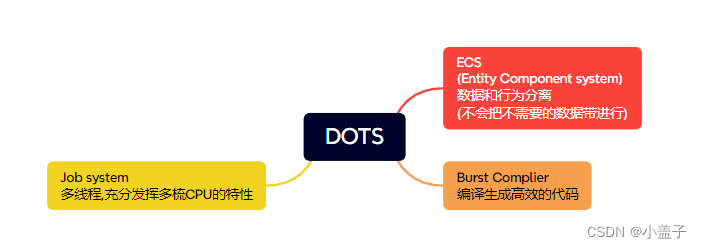
为了解决这解决上面的问题,Unity退出了DOTS技术,即:数据导向型技术堆栈.
1.ECS(Entity Component system) 数据和行为分离 (不会把不需要的数据带进行)
2.Job system:多线程,充分发挥多梳CPU的特性
3.Burst Complier:编译生成高效的代码
四.插件安装
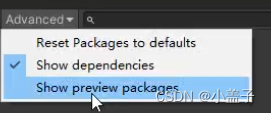
一、在PackageManager中选择Advanced并勾选Show preview pageages
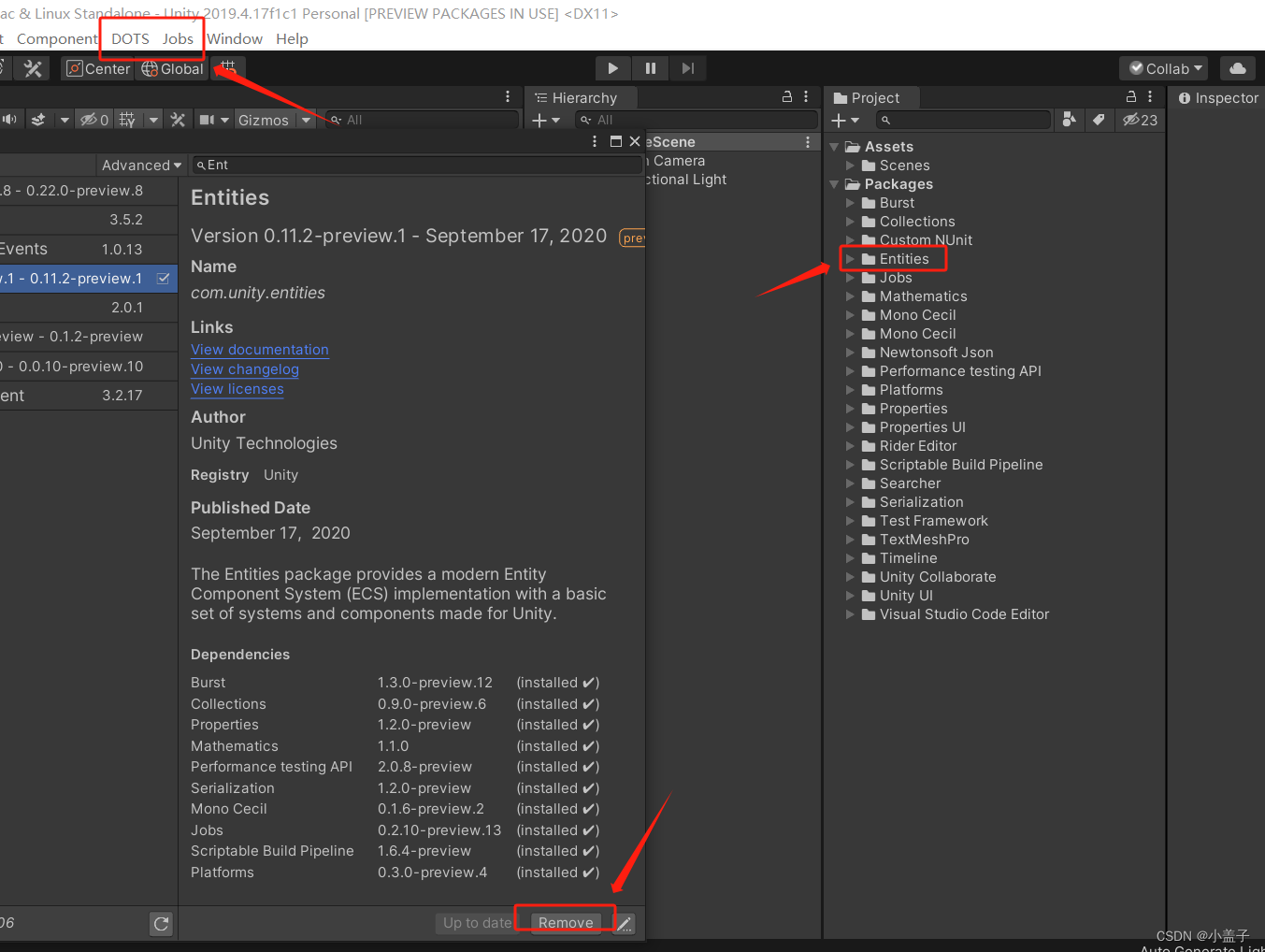
二.找到左边的Entities包进行安装,(比较大,等待比较久)
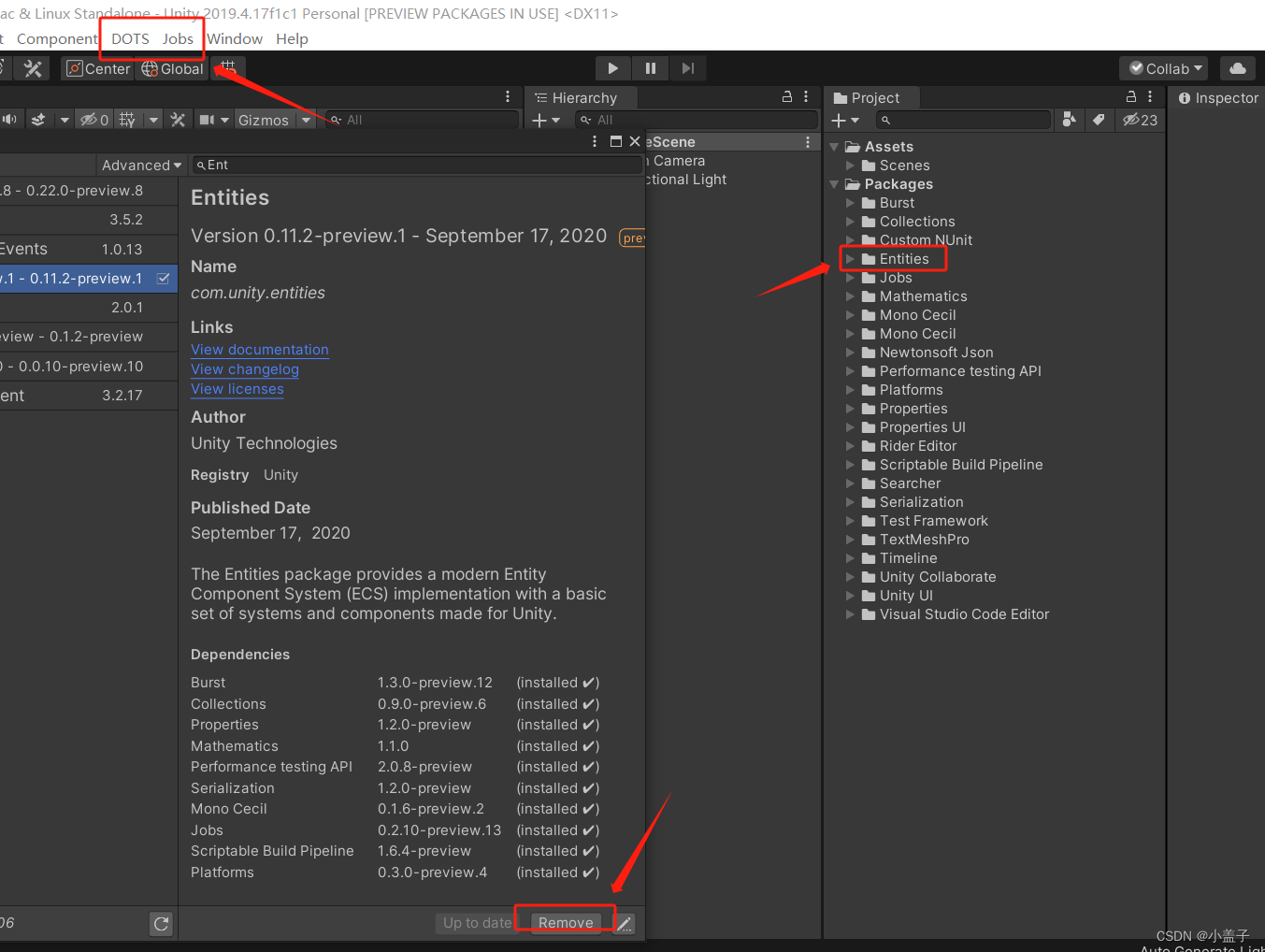
三.有了这些内容说明安装成功了
四.安装可视化组件Hybrid Renderer,用于差看场景中的实体