北京网站建设制作哪家公司好淘宝网页设计多少钱
一 css基础
css定义:可以设置网页中的样式,外观,美化
css中文名字:级联样式表,层叠样式表,样式表
二 css基础语法
1.style标签写在title标签后面
2.选择器{属性名1:属性值1;属性名2:属性值2}
color 代表颜色
font-size 代表字号,px为像素单位
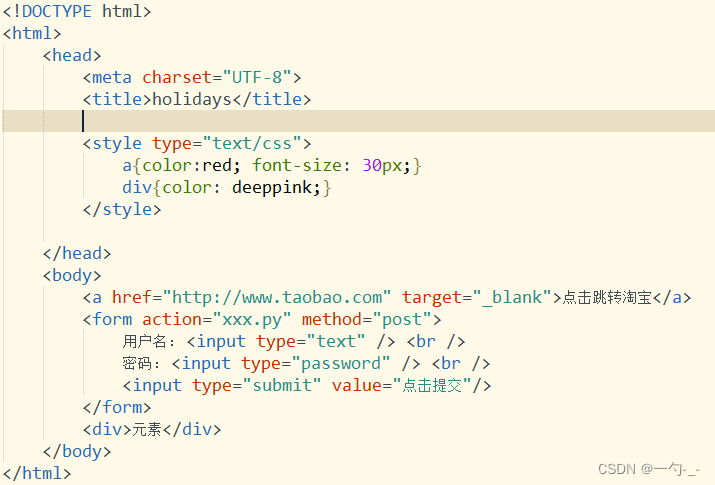
三 开发人员调试工具
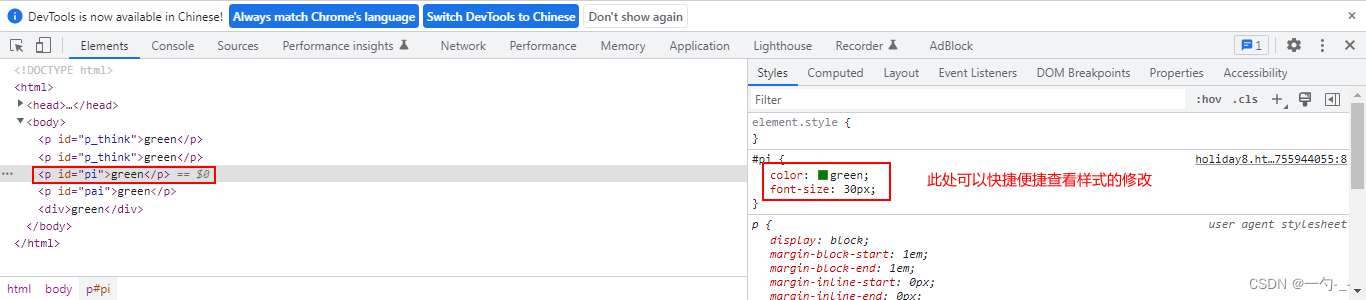
1.打开方式:F12或在网页中右键-检查
2.找到菜单中的第一个选项:elements
3.用鼠标左键点击想要查看的标签
4.右侧就会出现对应的css代码
5.想设置颜色:点击颜色方框,使用调色盘改变颜色后,别忘了把颜色的代码放在程序中
6.设置字体大小:鼠标左键点击数字,可以按住上下键,不要忘记改代码
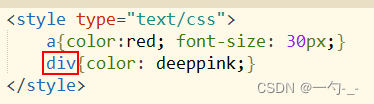
四 标签选择器
选择器:在大括号之前写的内容,就是选择器
标签选择器:用标签的名字来进行页面元素,标签,标记的选择
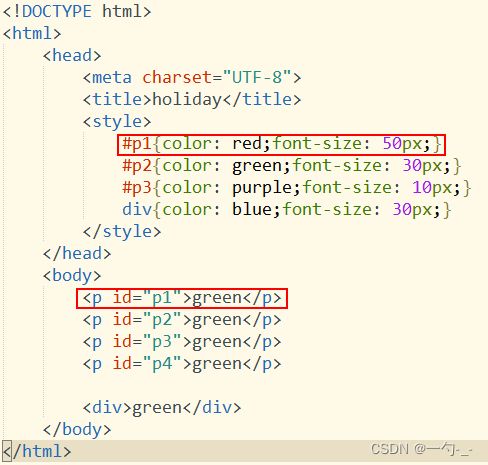
五 id选择器
id选择器:用html标签中的id属性来进行选取的方式
六 命名规则
1.不能数字开头
2.不能使用除了中划线和下划线之外的符号
3.不推荐使用中文
4.尽量做到见名知意
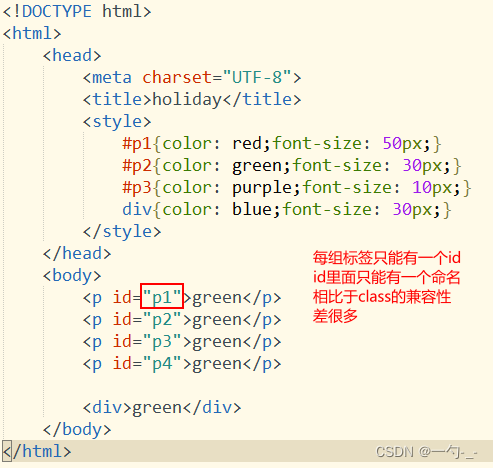
唯一性:
1.id命名不可以重复使用;在js中会因为id 的命名冲突而导致报错
2.每个标签只能有一组id
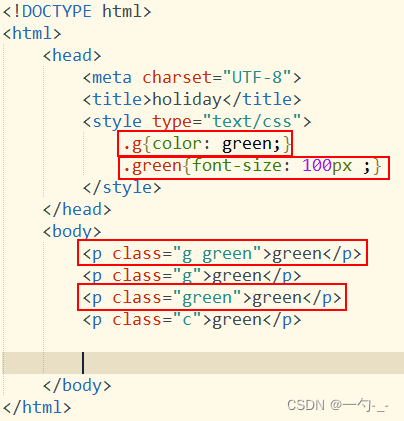
七 class类选择器
类选择器:使用html中的class的值来进行选取的方式
注意:class类选择器可以重复命名
每个标签可以有多个class类名,中间使用空格分割即可
命名规则:与id的命名规则完全一样。