食品网站建设的照片网站建设项
LabVIEW天然气压缩因子软件设计
项目背景
天然气作为一种重要的能源,其压缩因子的准确计算对于流量的计量和输送过程的优化具有关键意义。传统的计算方法不仅步骤繁琐,而且难以满足现场快速响应的需求。因此,开发一款既能保证计算精度又便于现场操作的软件成为行业的迫切需求。
系统组成与技术实现
软件由LabVIEW实现,包括复杂的数学计算和用户界面的构建。通过LabVIEW内建的强大数学功能,实现了所有数学计算模块,同时利用其优秀的用户界面设计能力,构建了易于操作的数据展示和控制界面。这种单一环境实现确保了软件的高效运行和稳定性。
工作原理
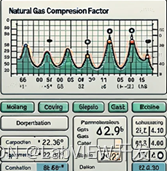
软件工作原理基于AGA8-92DC方程,用户仅需输入天然气的组成、温度、压力等参数,LabVIEW编写的程序便能快速计算出天然气的压缩因子。开发设计了一系列专门的VI(虚拟仪器),用于进行参数输入、计算过程控制及结果展示。
系统指标与性能
该软件能够在不同条件下准确计算天然气压缩因子,计算误差小于0.1%。软件操作简便,计算速度快,能够满足现场快速响应的需求。
硬件与软件的协同
通过完全在LabVIEW平台上实现,软件充分利用了LabVIEW在数据采集、信号处理及用户界面设计方面的特点,实现了硬件与软件的高效协同,从而提升了天然气压缩因子计算的准确性和实用性。
总结
该案例展示了完全基于LabVIEW的天然气压缩因子计算软件设计的实践应用。通过技术创新,软件不仅提高了计算精度,而且极大地提升了用户体验,为天然气行业提供了一个高效、准确的计算工具。