参考:
https://zhuanlan.zhihu.com/p/567761684?utm_id=0
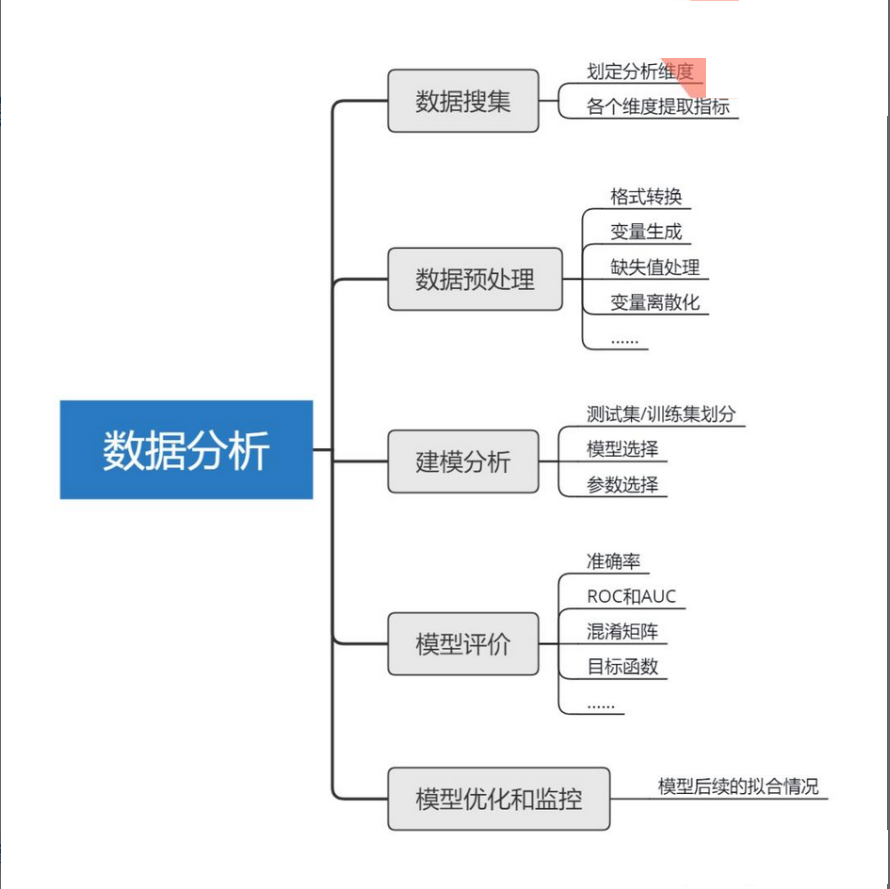
1、数据分析步骤地图

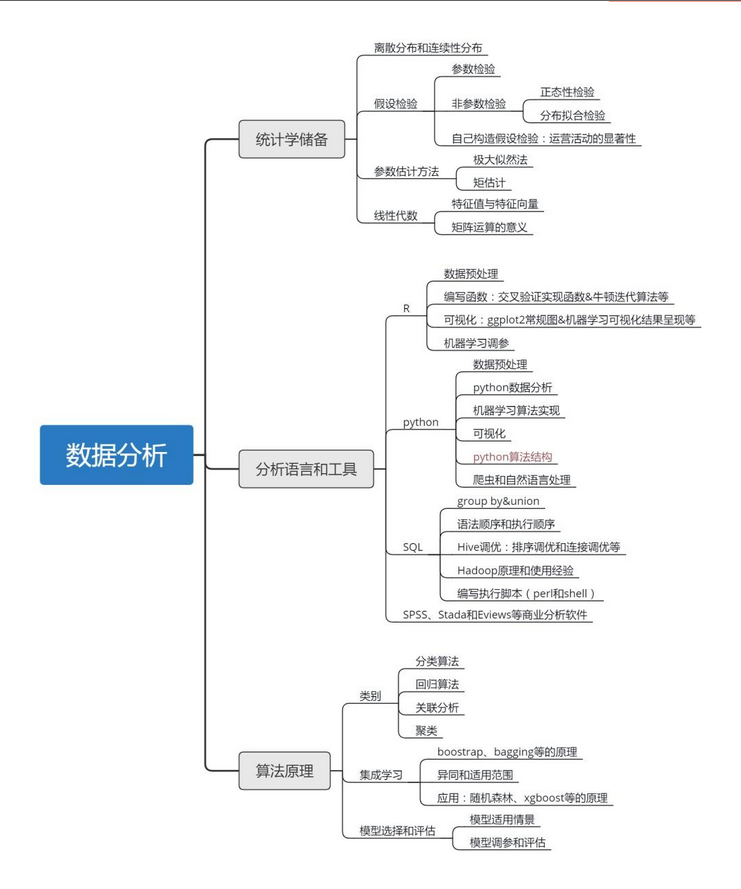
2、数据分析基础知识地图
3、数据分析技术知识地图
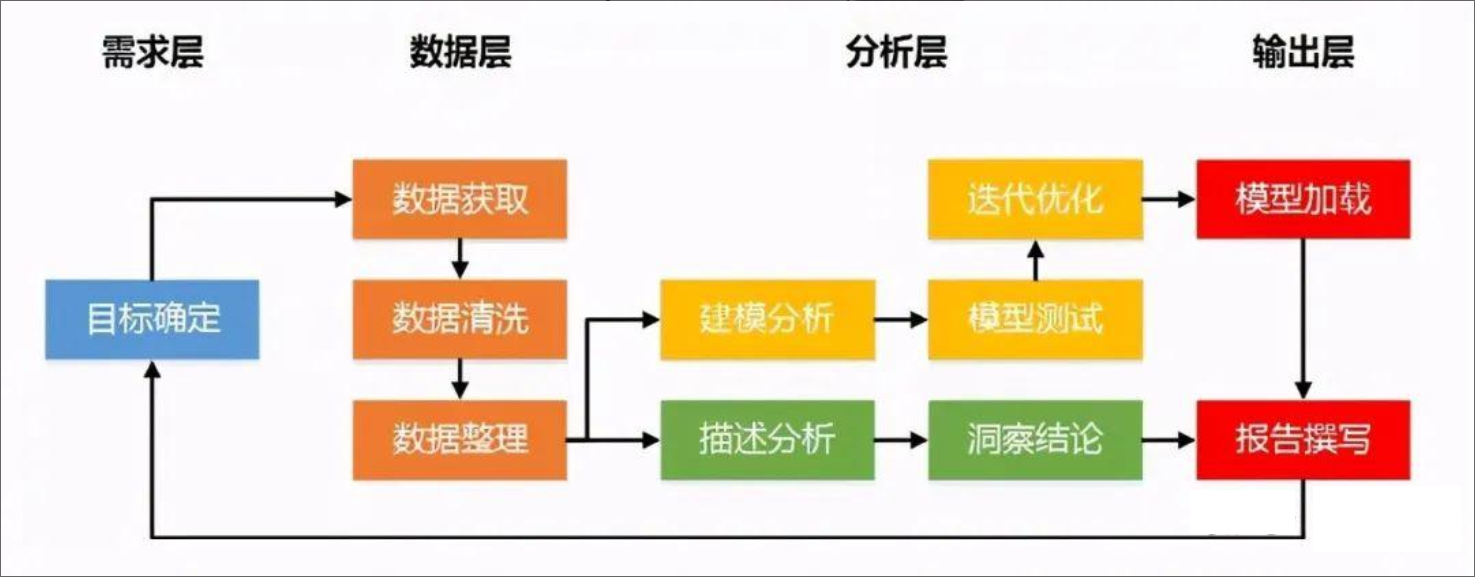
4、数据分析业务流程
5、数据分析师能力体系

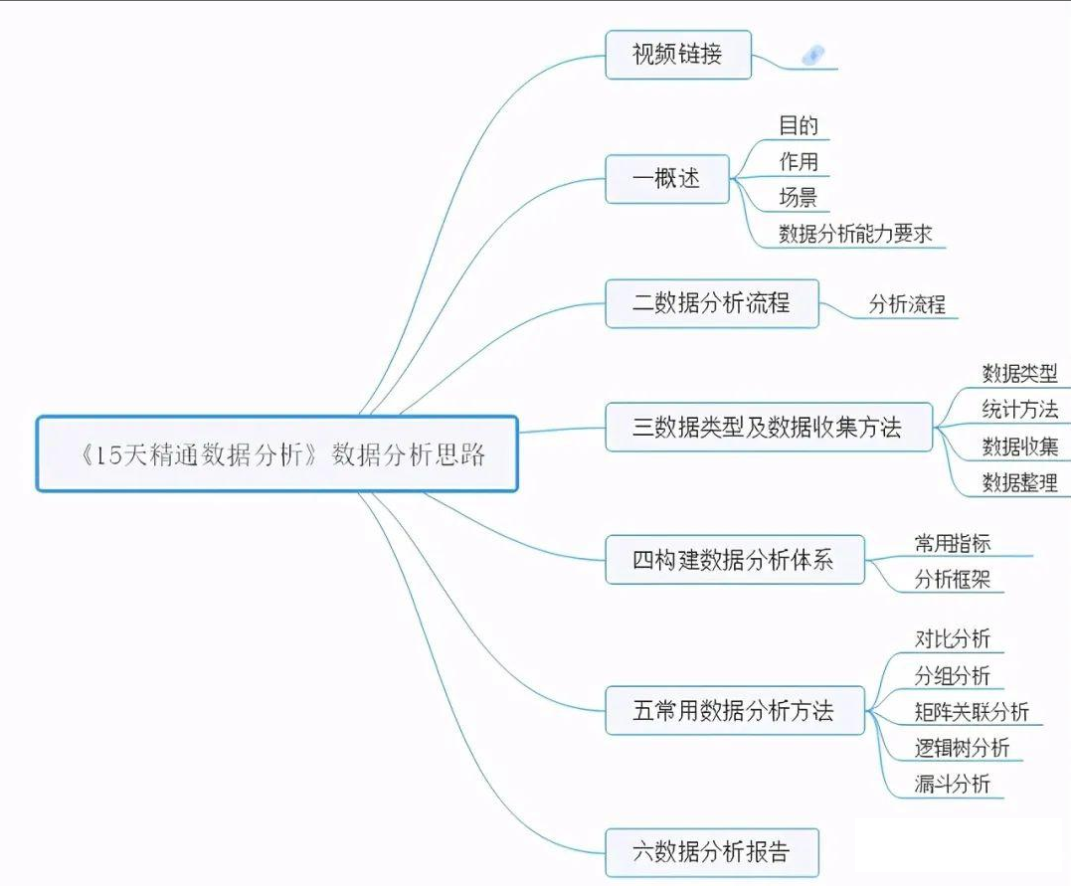
6、数据分析思路体系
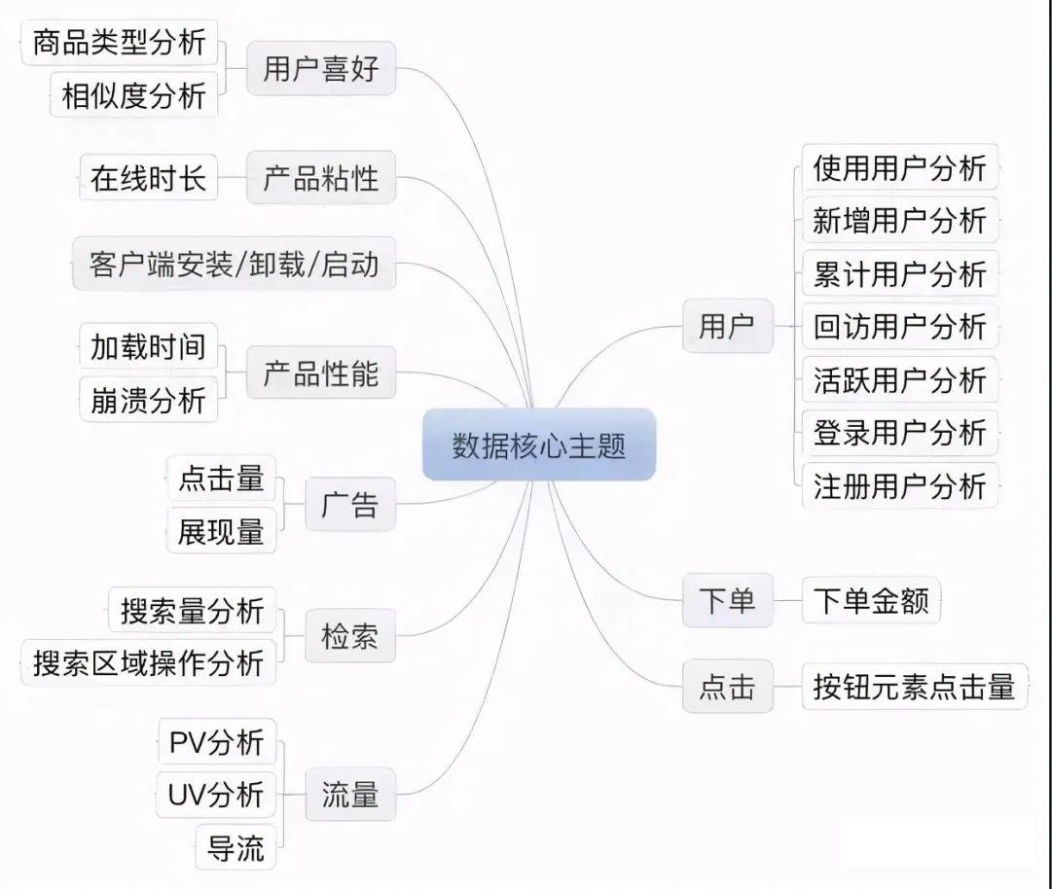
7、电商数据分析核心主题
8、数据科学技能书知识地图

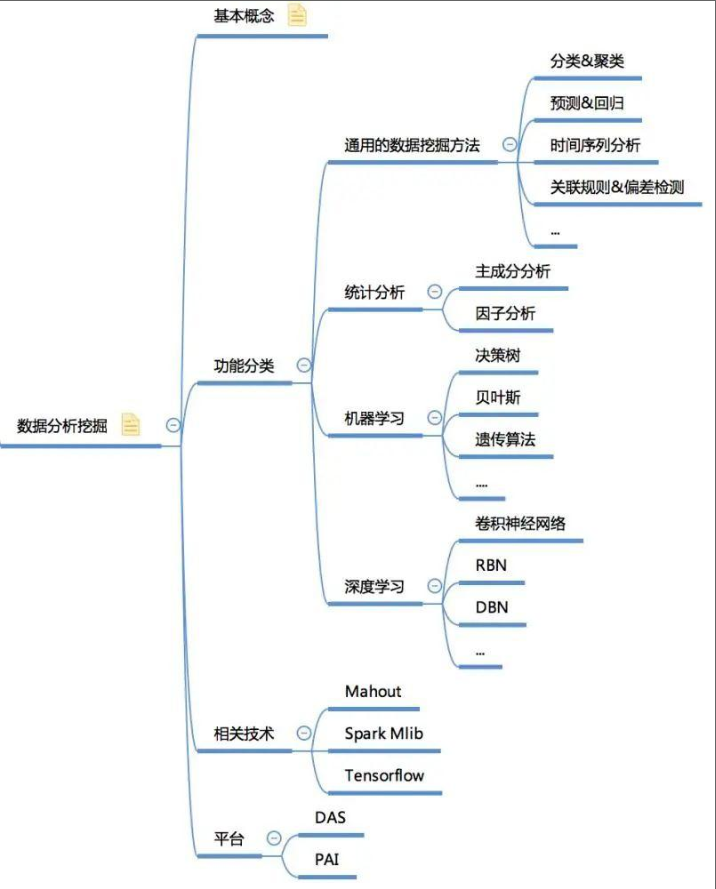
9、数据挖掘体系
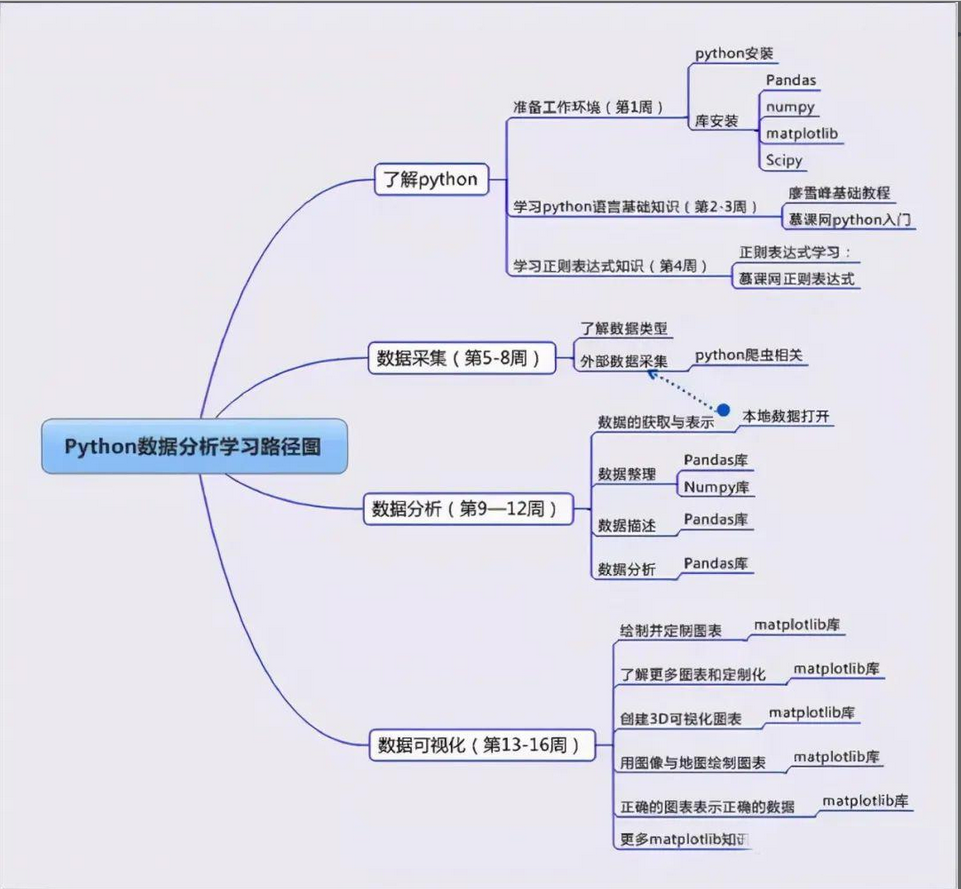
10、python学习路径
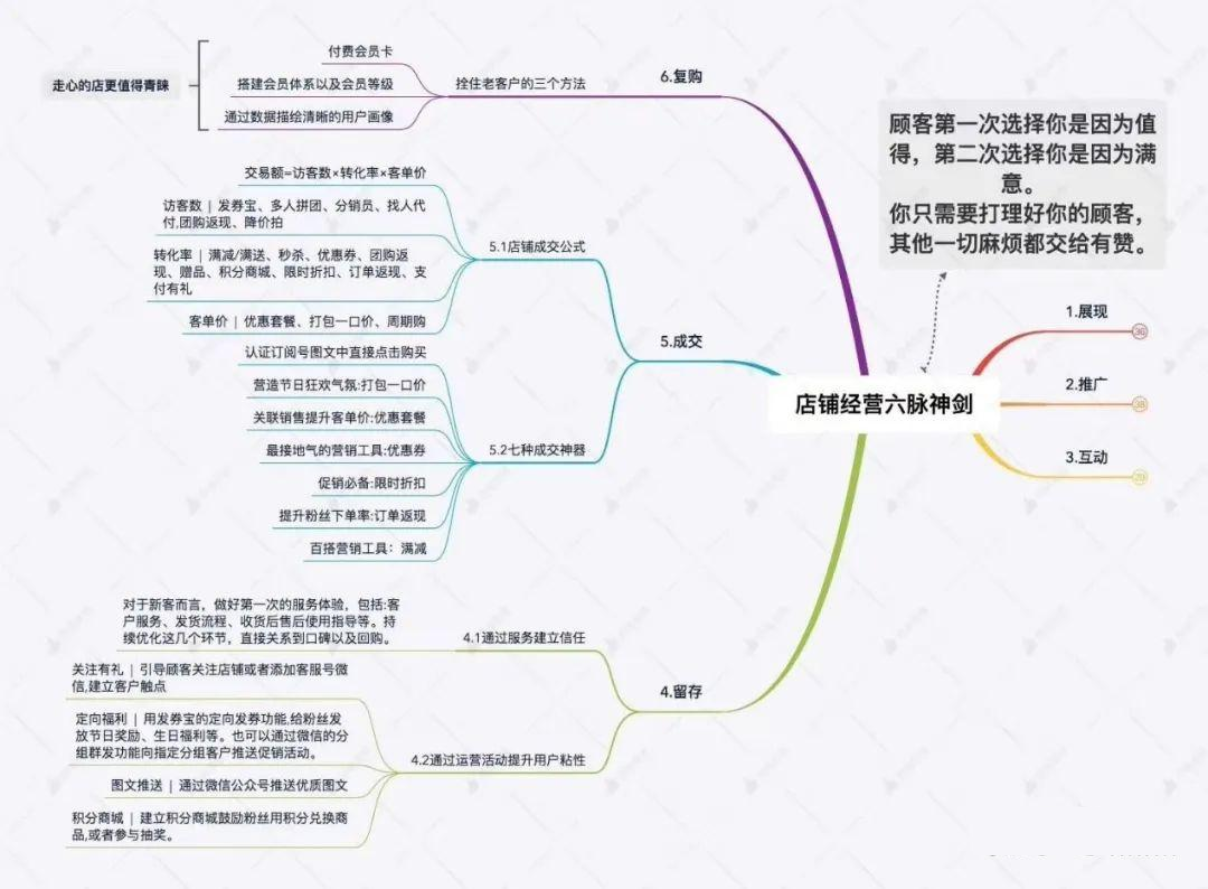
11、线下店铺数据分析
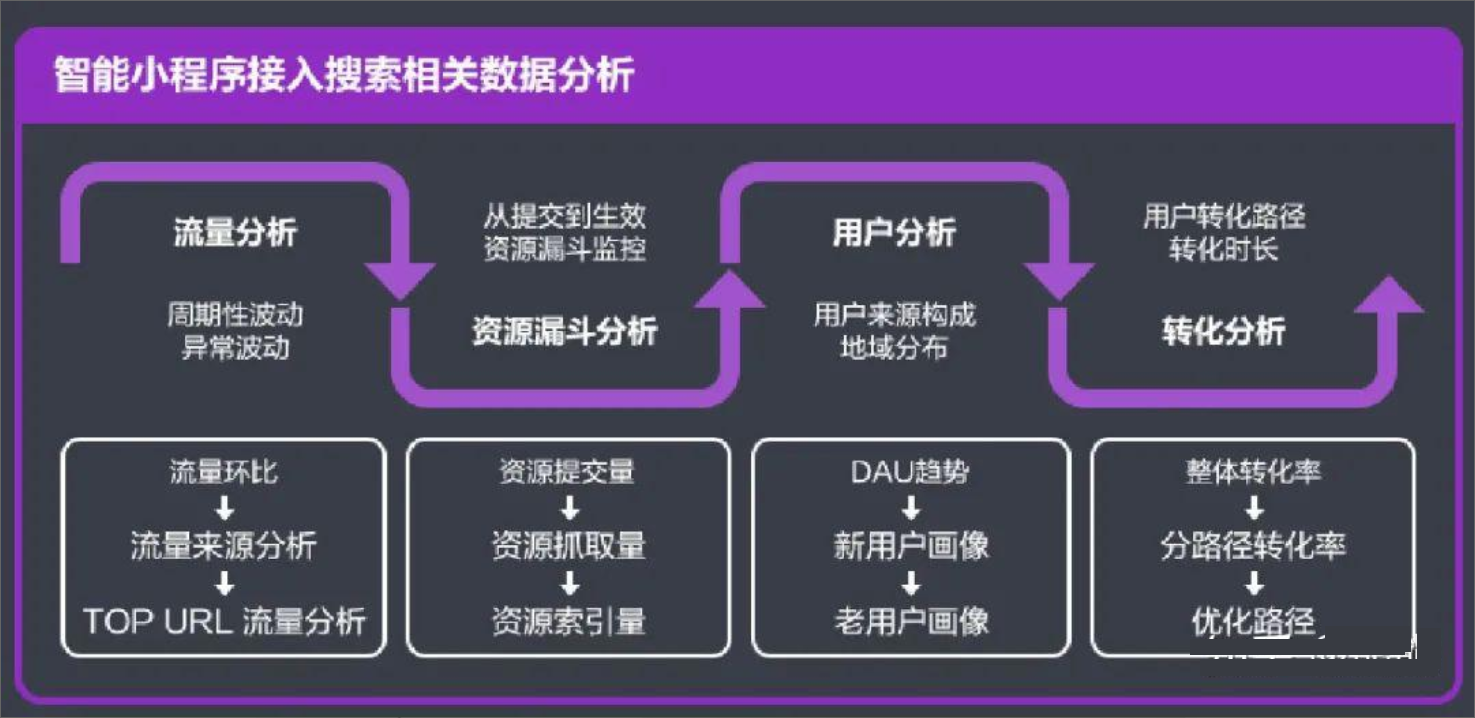
12、小程序数据分析
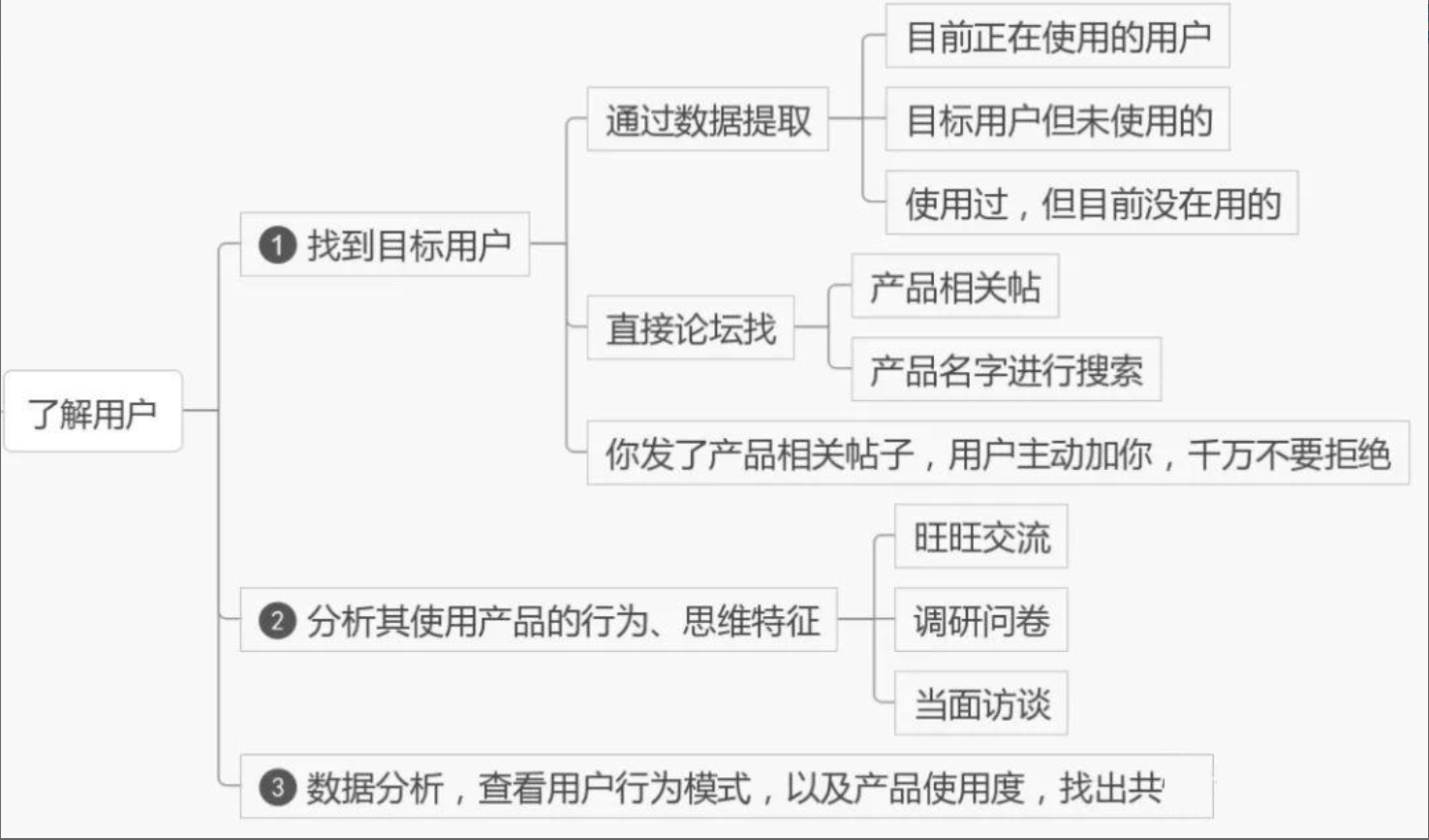
13、用户分析
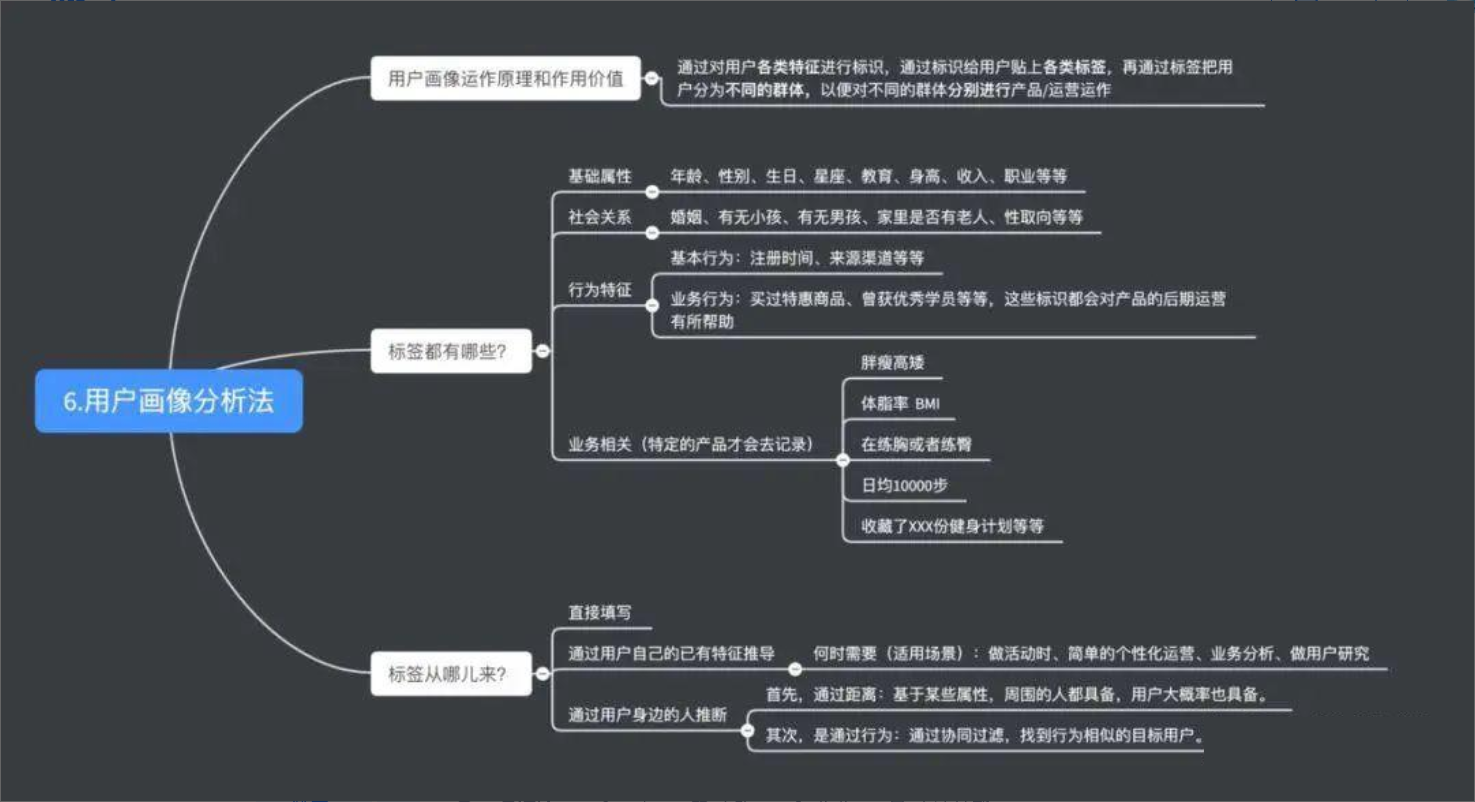
14、用户画像法
15、Excel常用公式

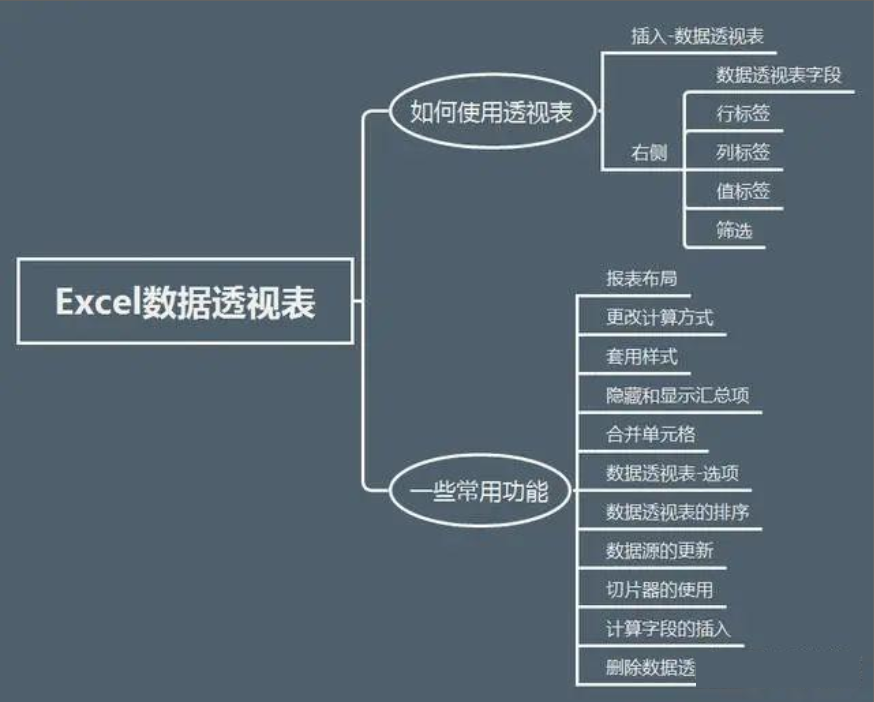
16、Excel透视表
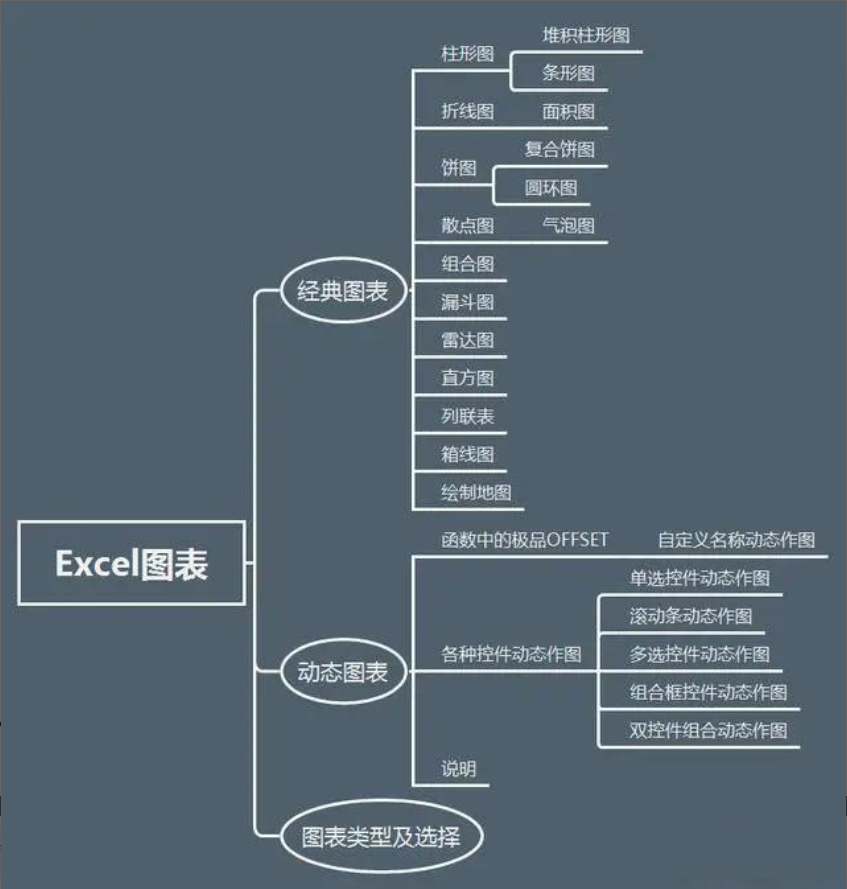
17、数据分析图表
18、MySQL

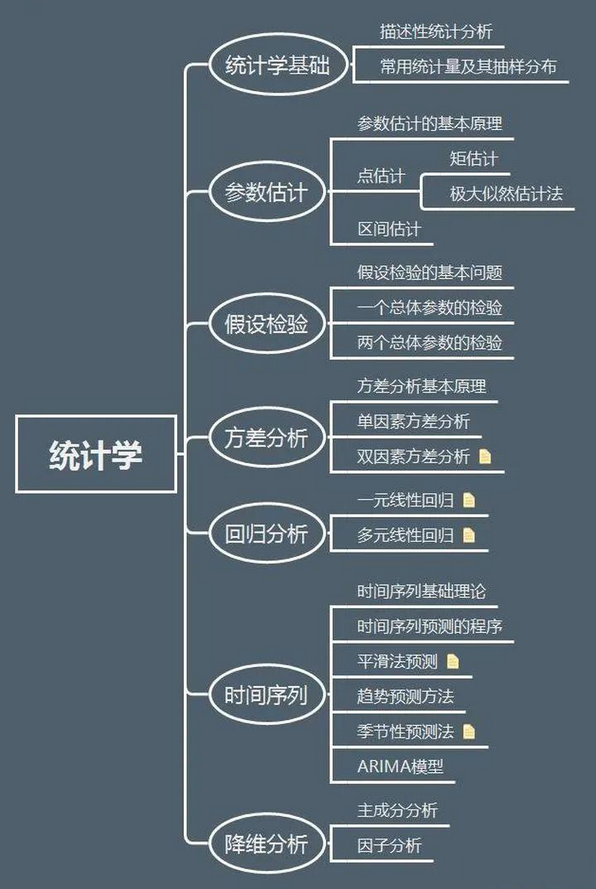
19、统计学
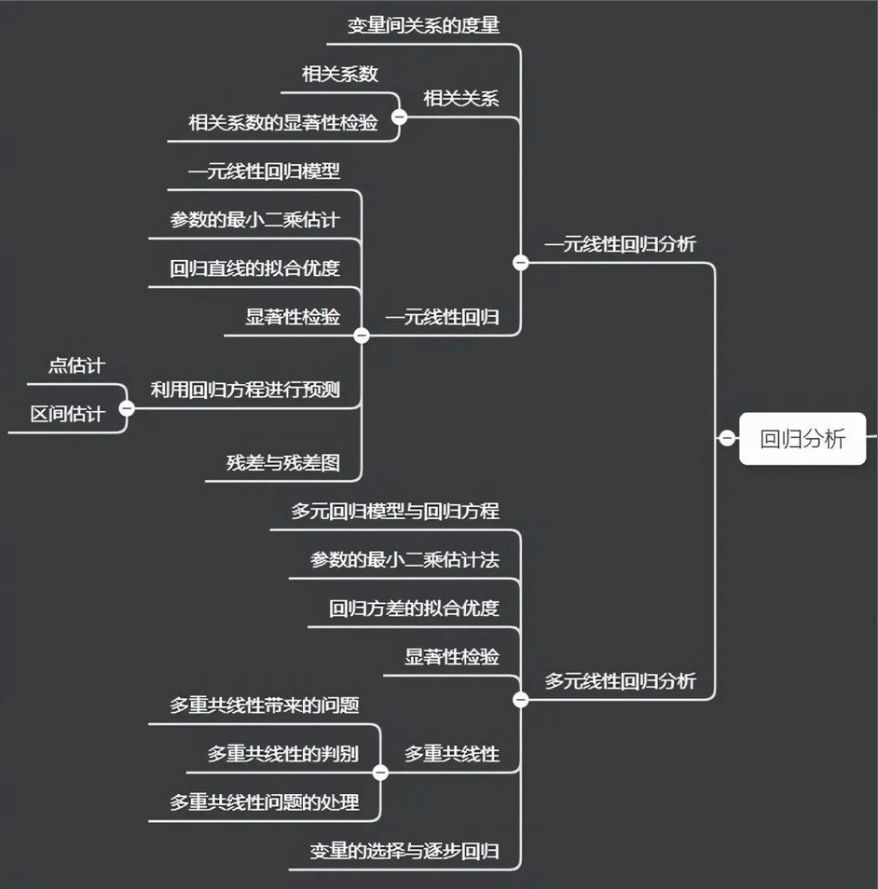
20、回归分析方法