高碑店市建设局网站界面做的最好的网站
1.找出选修课程成绩最差的选课记录
注:
聚合函数只能用在group by和()括号中
找最值可用排序order by+limit 1


2. 查询选修成绩 合格的课程 超过2门的 学生编号

3.删除姓名为"LiMing"的学生信息
注:
删除一整行信息,不要加 *

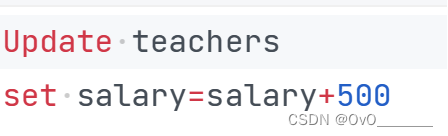
4.将所有教师的工资加500元
注:
语法update+表
set 设置修改内容
5. 查询没有选修java学生的姓名
注:
1.利用嵌套查询 引用 choices表,注意区别连接查询
2.not exists 类似 not in,有时输出结果一致
exists是小表套大表
in是大表套小表
3.字符匹配 like


6.查询没有学生选的课程名称
注:
not in ( )

7.查找与刘晨一个专业的同学
注:
嵌套查询,体会过程先找到刘晨专业是什么,再找该专业的学生

8.查询“谭浩强”教师任课的课程号,选修其课程的学生的学号和成绩
注:
外连接的表,是查询过程所需的表,但查询要求不是

9.查询出生日期大于所有女同学出生日期的男同学的姓名及系别
注:
比大小时,也可使用嵌套查询(比较运算符的子查询)

10.查询选修课程c++而没有选修课程java 的学生的编号
注:
intersect 求交集
not in() 和 in


11.