花钱做的网站推广被骗北京南站官网
--- 后之视今,亦犹今之视昔!
目录
早期系统架构图
早期系统架构视图
4+1视图解读
4+1架构视图缺点
现代系统架构图的指导实践
业务架构
例子
使用场景
画图技巧
客户端架构、前端架构
例子
使用场景
画图技巧
系统架构
例子
定义
使用场景
画图技巧
应用架构
例子
定义
使用场景
画图技巧
部署架构
例子
定义
使用场景
画图技巧
系统序列图
为什么系统序列图
从架构图到序列图
早期系统架构图
早期系统架构视图
第一次系统架构视图正式出现,是1995年Philippe在IEEE发表论文《The 4+1 View Model of Architecture》。并演变为RUP 4+1系统架构视图方法。下图是论文原图对4+1的阐释。文章介绍了如何通过这5种视图来表达【软件架构是什么】。
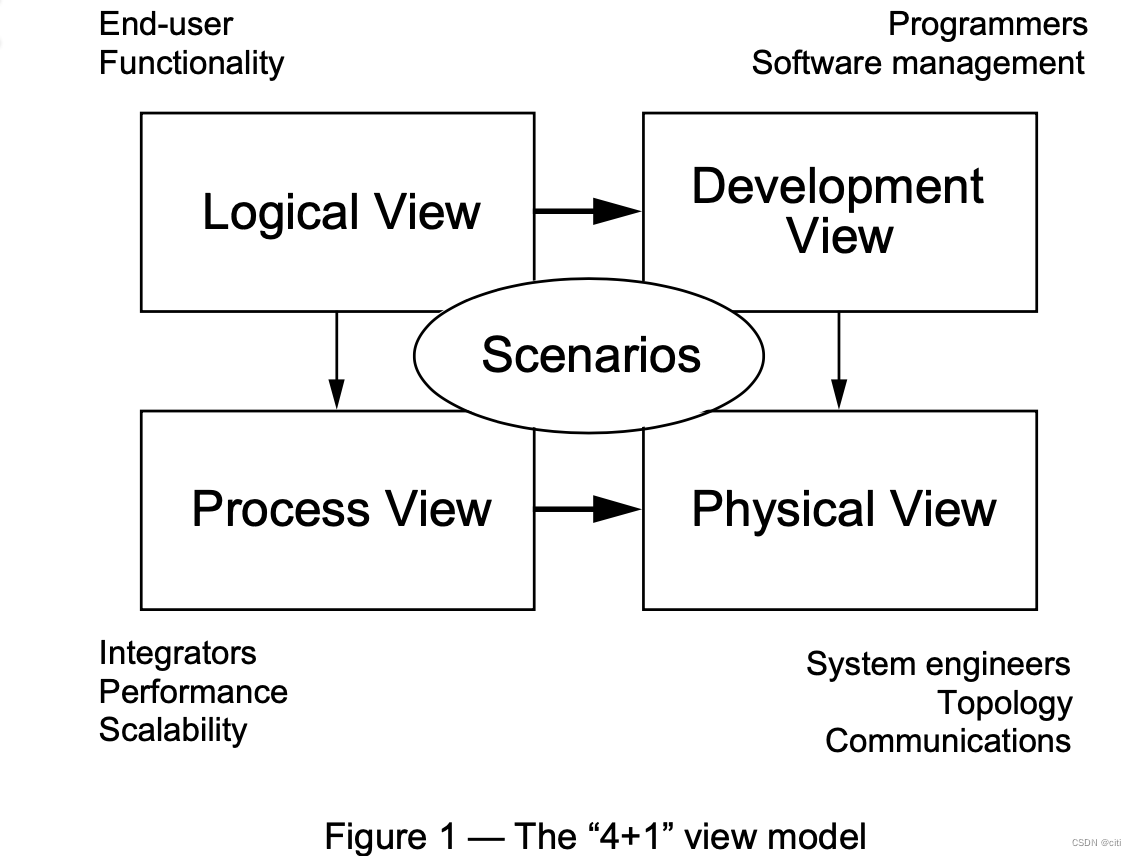
论文原图
4+1视图解读
Philippe的4+1,分别为逻辑视图、开发视图、处理视图、物理视图及场景视图。
从不同的角度来展示软件系统的设计。眼耳鼻舌身意,感知世界也总要分那么多的类型。
每个分类和具体的应用,可以看下涛哥的 架构蓝图--软件架构的“4+1”视图模型 - 知乎
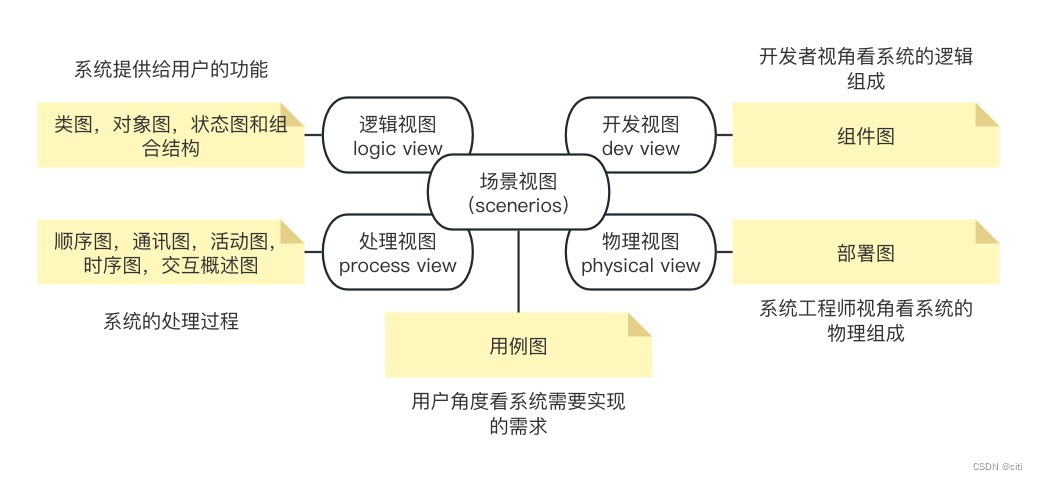
4+1架构视图缺点
毕竟是95年提出的概念,4+1视图很多方面并不能适应现代的软件工程了。
- 架构复杂度增加,目前大部分系统已由单体系统进化为分布式系统
- 强绑定UML图,UML不能很好地表达架构图
- 理解不一致的问题,逻辑视图、开发视图、处理(process)视图比较容器混淆
现代系统架构图的指导实践
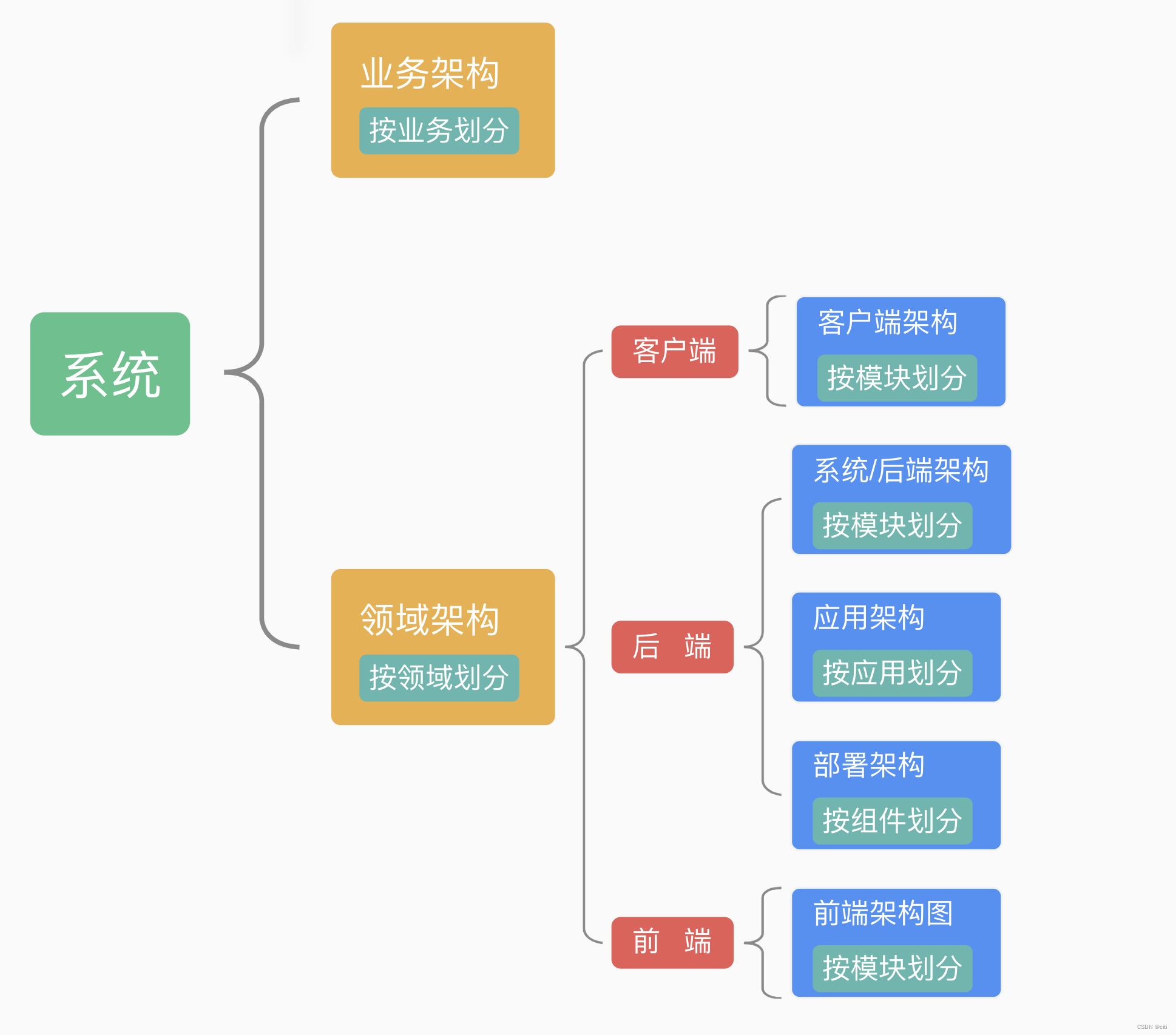
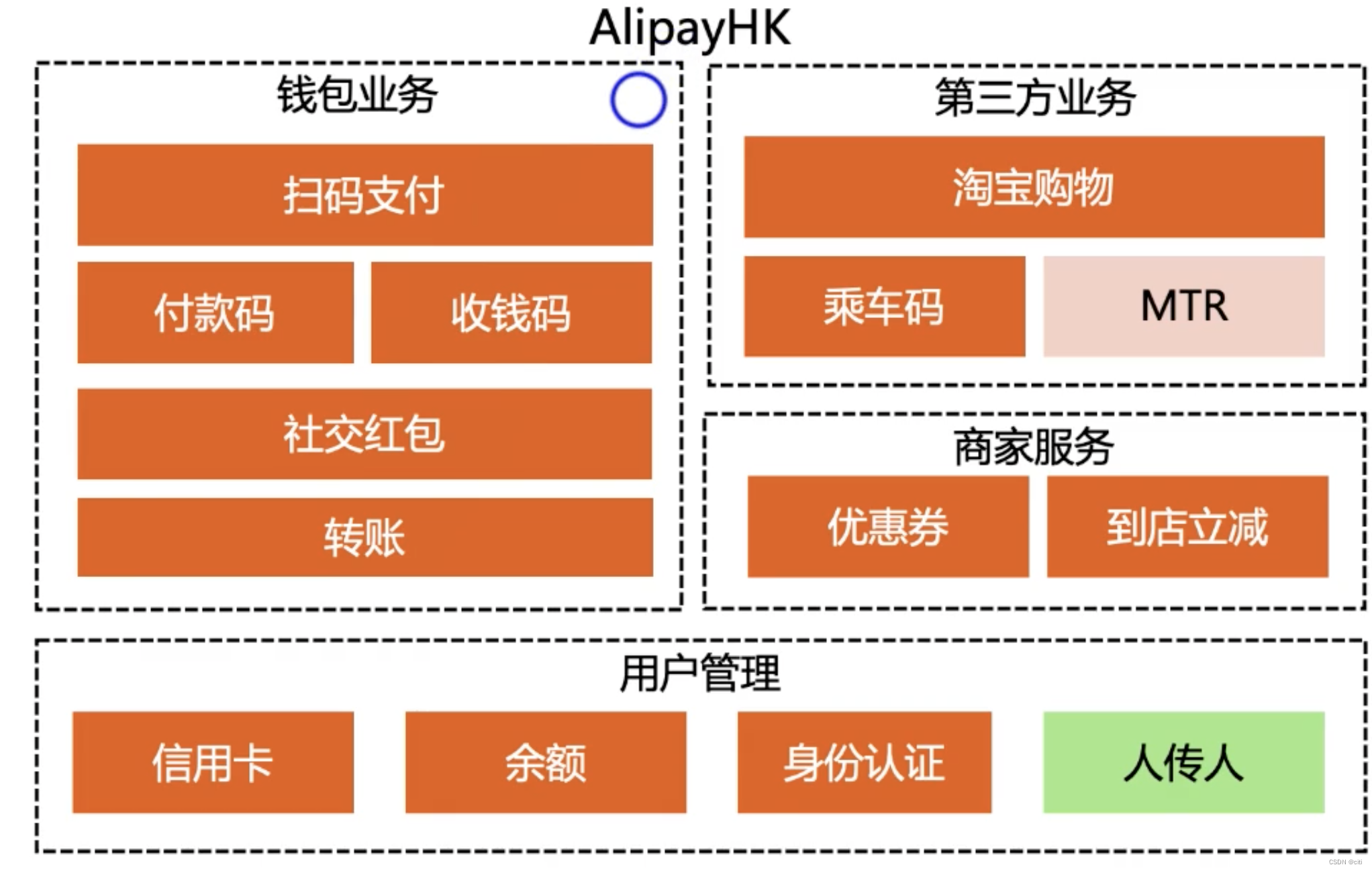
业务架构
描述系统为用户提供了什么业务功能,重点在于业务逻辑。类似于4+1视图中的场景视图。但其组织形式和美观程度不是用例图可以提供的。
例子
使用场景
- 产品人员规划业务
- 给高P汇报业务
- 给新员工培训业务
画图技巧
- 通过不同颜色来标识不同角色
- 业务分组管理
客户端架构、前端架构
类似与4+1中的【逻辑视图】。客户端和前端的领域逻辑架构。
例子
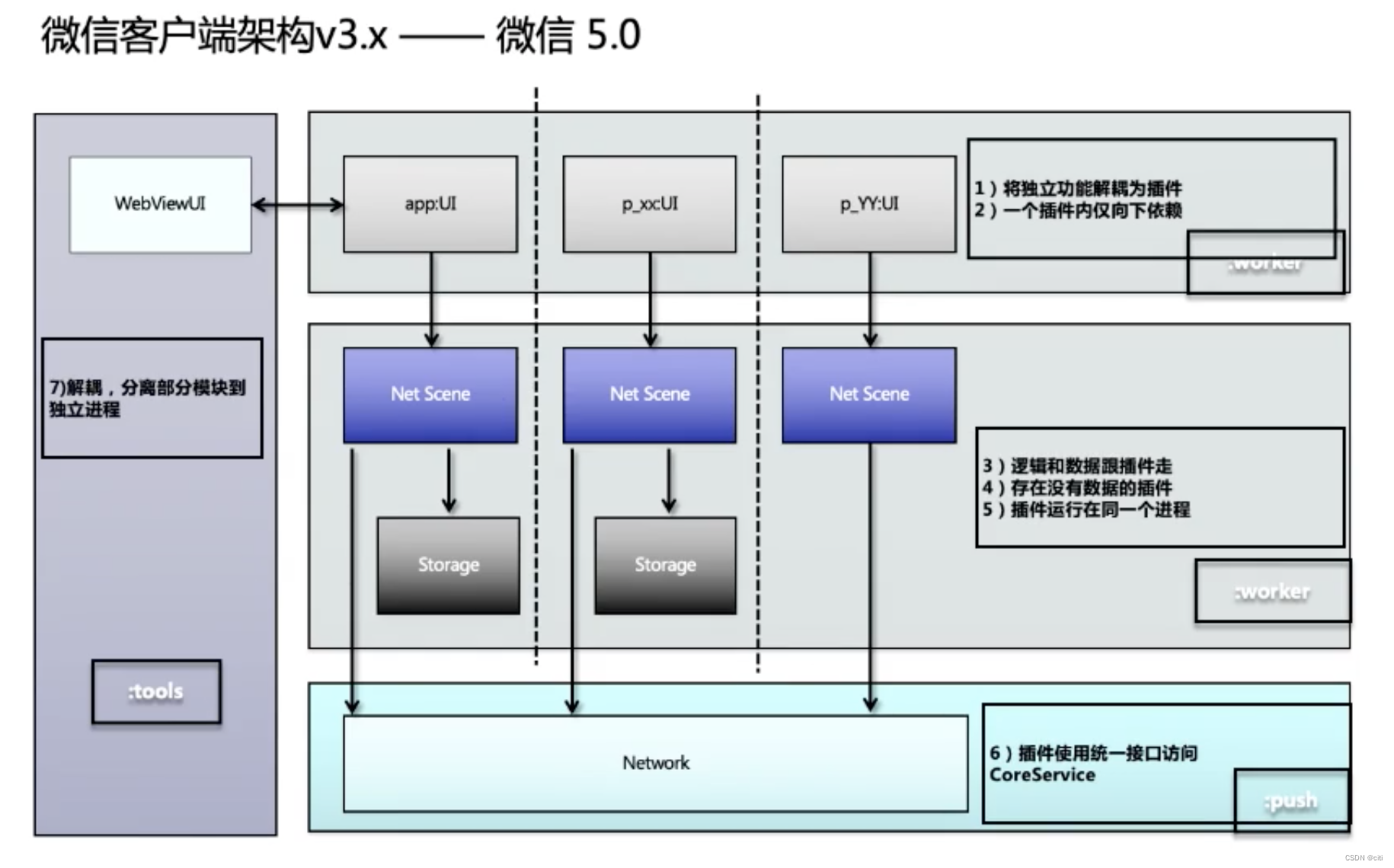
使用场景
- 整体架构设计
- 架构培训
画图技巧
- 通过不同颜色来标识不同角色
- 通过连接线表示关系
系统架构
例子
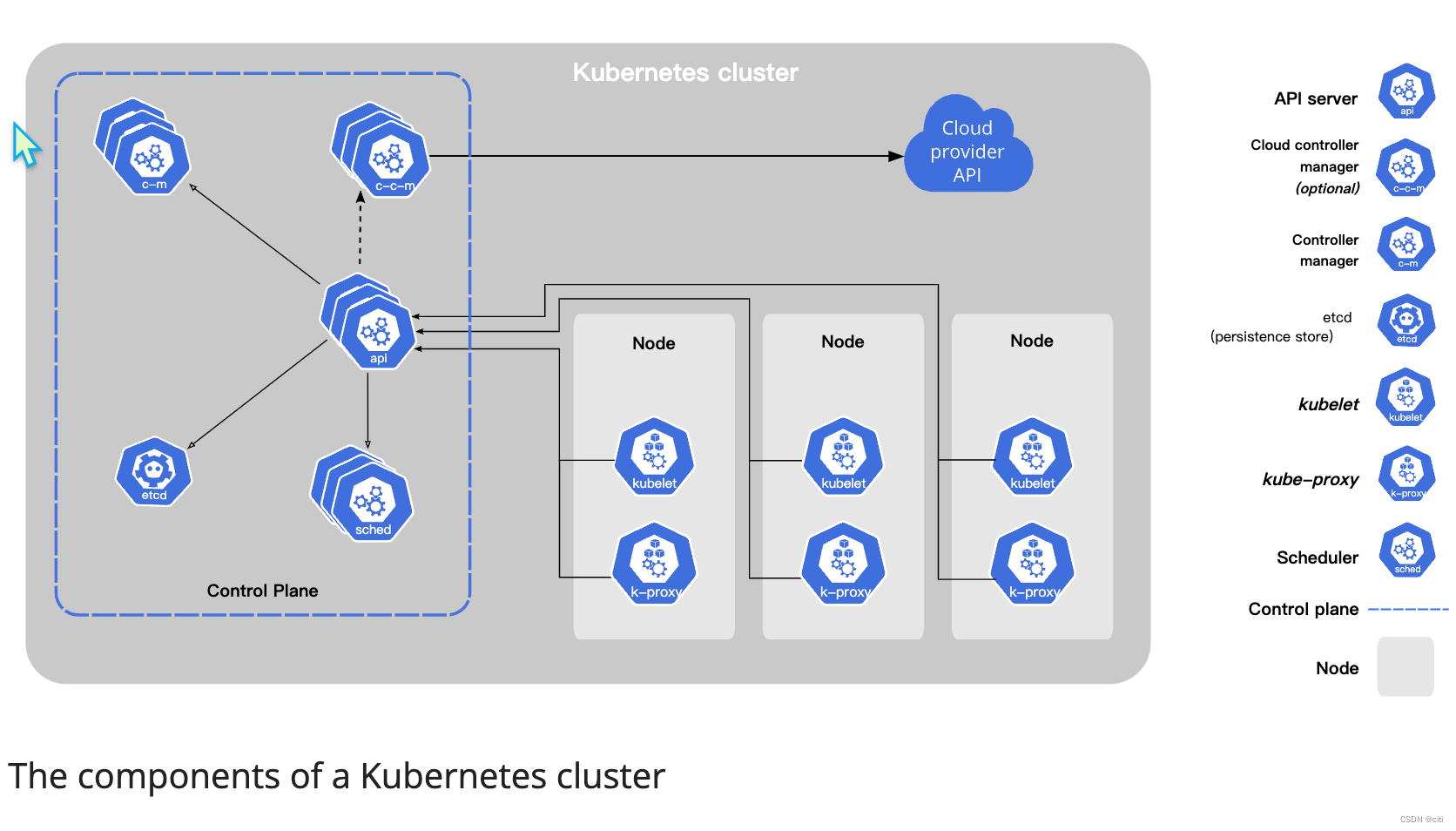
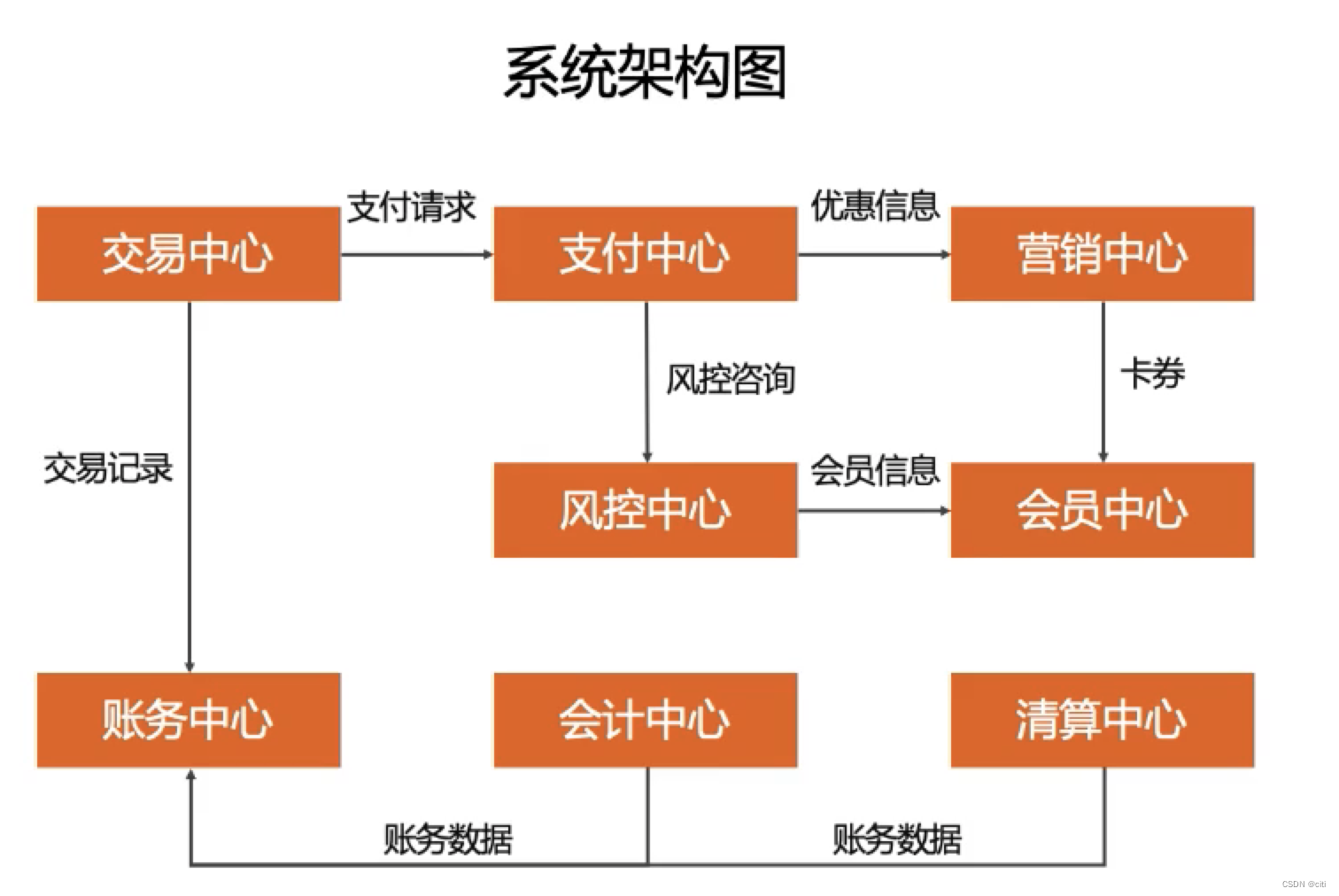
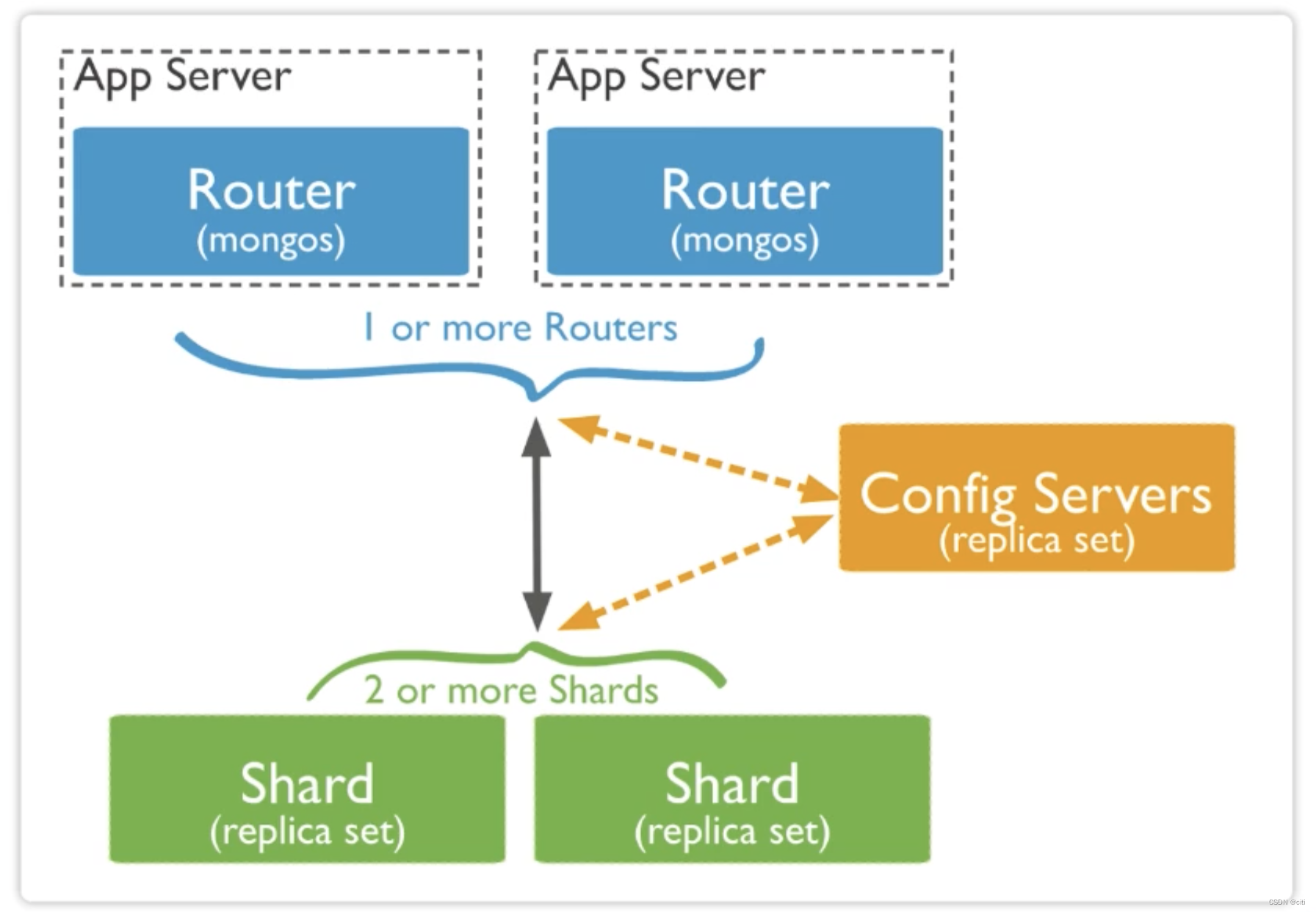
定义
后端的逻辑架构,又叫后端架构、技术架构。
【个人理解】:系统架构个人认为应该包含业务架构+应用架构。来表示软件系统提供什么样的业务能力、解决方案,同时这个系统的子模块、子系统的组成。让技术人员形成一个整体的宏观认知。
使用场景
- 整体架构设计
- 架构图培训
画图技巧
- 通过不同颜色来标识不同角色
- 通过连接线表示关系
应用架构
例子
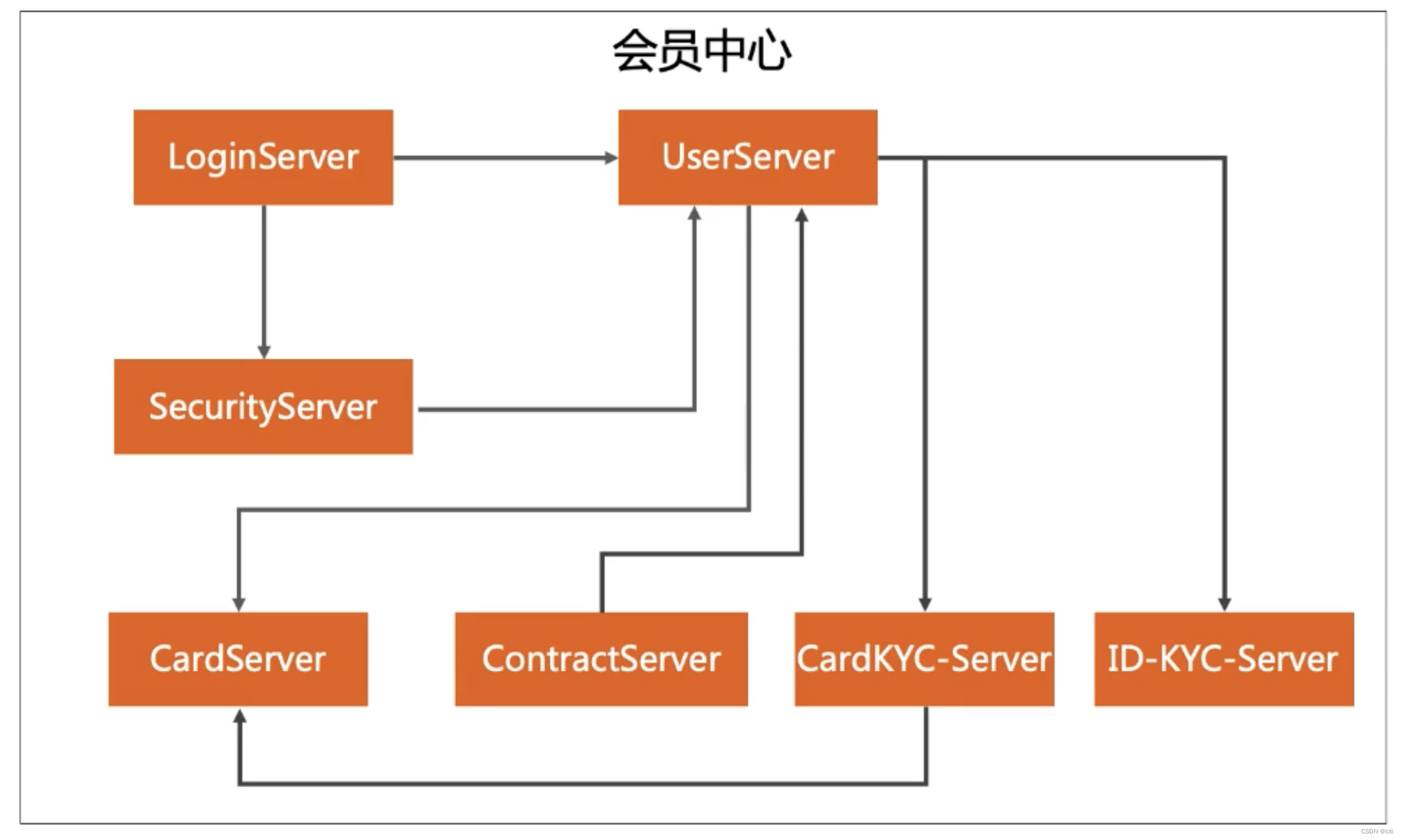
定义
描述后端系统由哪些应用组成。有点类似开发视图。应用架构有时和系统架构等价的。但如果软件系统更大更复杂, 系统架构则看起来需要使用业务架构+应用架构等多个来组成。
使用场景
- 项目开发、测试
- 部署发布
- 子域架构设计
画图技巧
- 通过不同颜色来标识不同角色
- 通过连接线表示关系
部署架构
例子
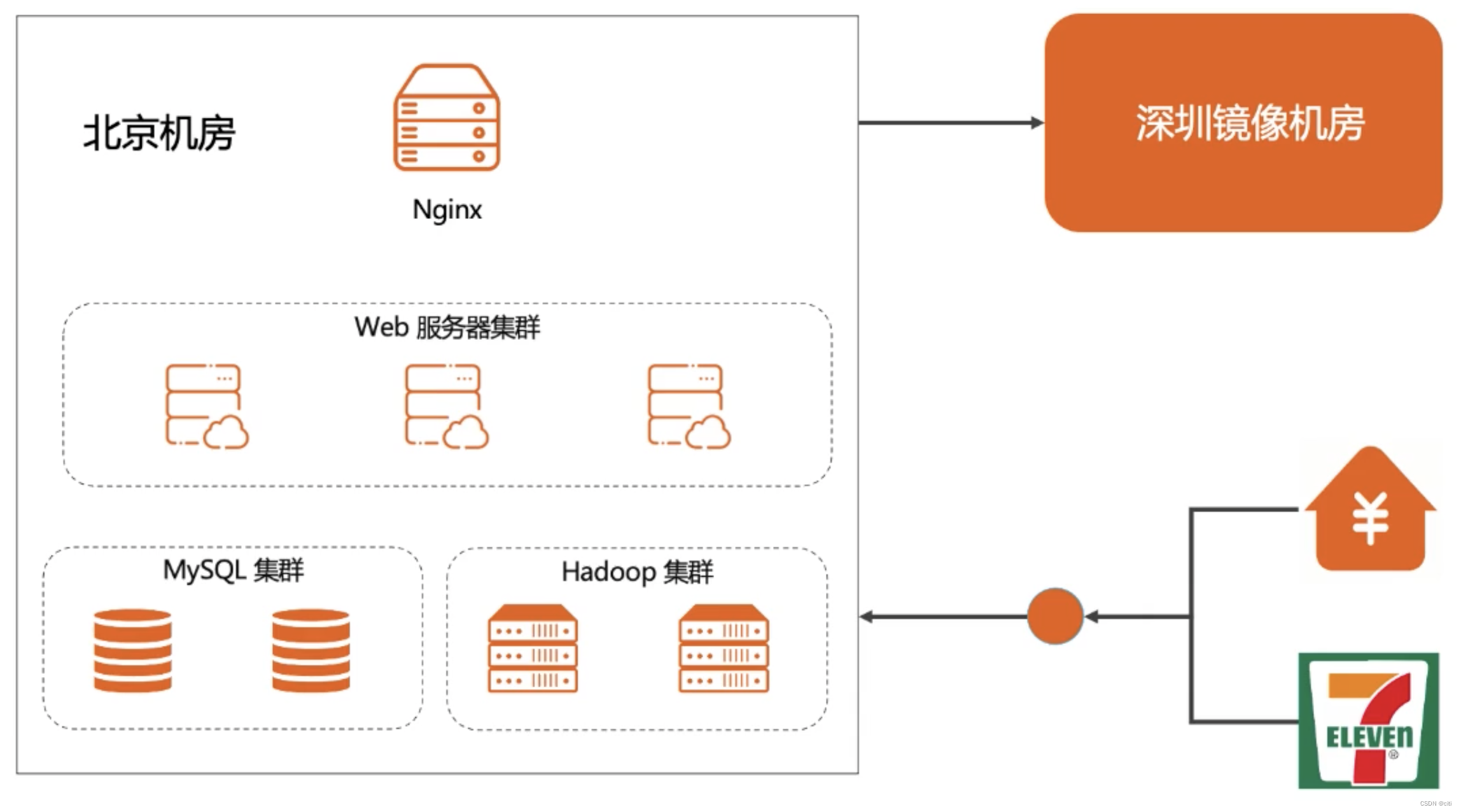
定义
描述后端系统具体如何部署。对应4+1视图的物理视图。
使用场景
- 总体架构设计
- 运维规划和优化
画图技巧
- 用图标代替区块
系统序列图
为什么系统序列图
组成角色 Role、角色关系 Relation
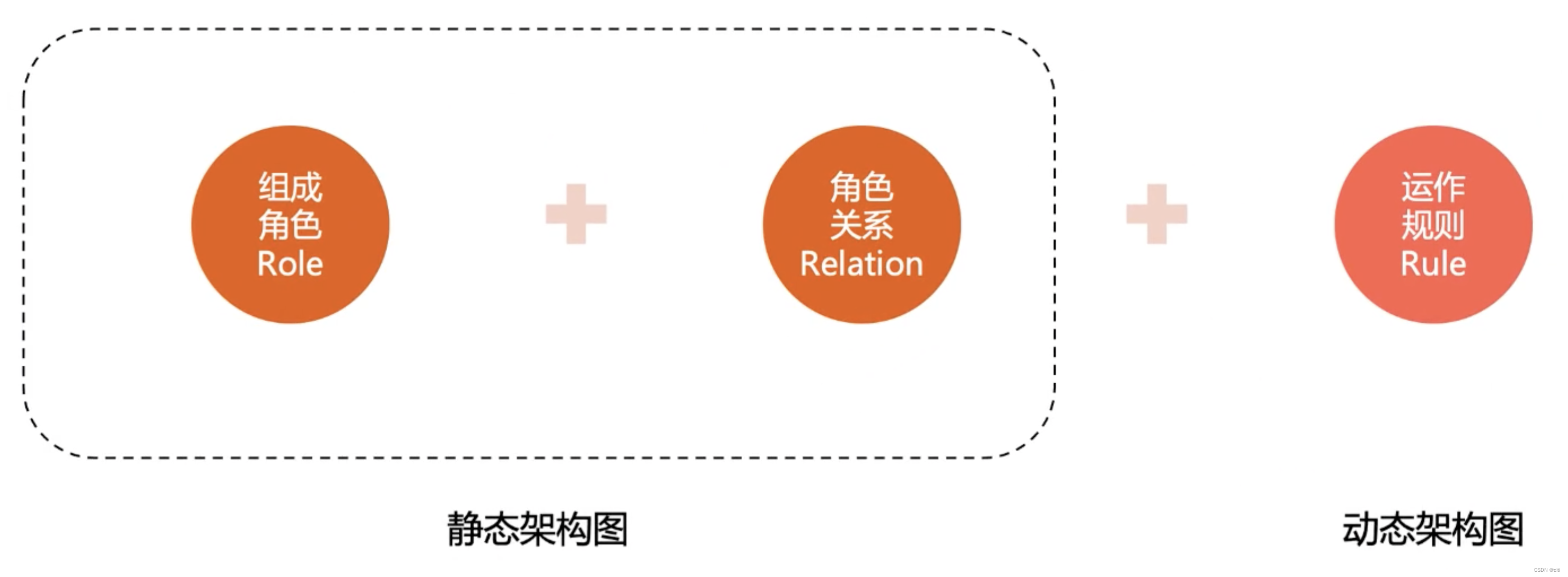
动态架构图 需要用系统序列图表示。(时序图)
从架构图到序列图
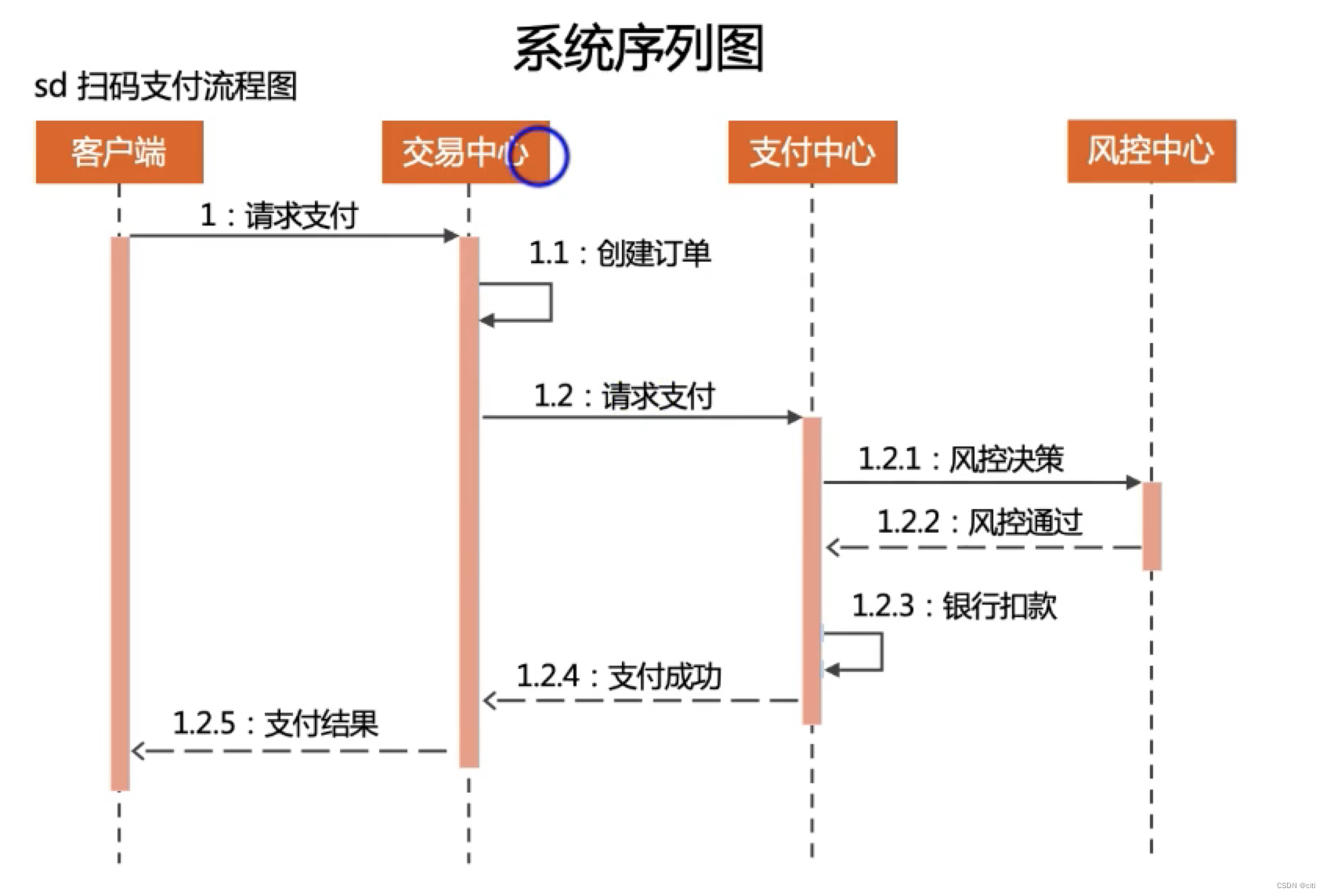
参考引用
Kruchten P. Architectural Blueprints—The “4+ 1” View Model of Software Architecture. 1995[J]. IEE Software, 2005, 12(6)
架构蓝图--软件架构的“4+1”视图模型 - 知乎
极客时间训练营-让优秀的人一起学习